 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAdam: Metric-Aware Multi-Objective Adam
Jun 02, 2026Multi-objective optimization (MOO) underlies many machine learning problems, yet MOO solvers across the loss-balancing, gradient-balancing, and Pareto-based families almost universally hand their reconciled directions to Adam~\cite{kingma2015adam}. We show this coupling introduces two systematic gaps between the solver's intent and the optimizer's execution. The first is a \emph{weighting mismatch}: Adam's second-moment denominator entangles the time-varying preference vector with gradient statistics, marginalizing the preference into a history average and collapsing distinct Pareto trade-offs toward a near-uniform mixture. The second is a \emph{geometric mismatch}: Adam's adaptive metric distorts the Euclidean geometry MOO solvers assume, turning aligned objectives into apparent conflicts. To resolve both jointly, we introduce \textbf{MAdam} (Metric-Aware Multi-Objective Adam), a drop-in wrapper that leaves both solver and optimizer unchanged. MAdam preconditions the reconciled direction by the preference-conditioned curvature of the scalarized objective; on this whitened input, Adam's second moment collapses to identity, so the realized update is governed by the preference-conditioned metric. Across multi-task learning, Pareto-front recovery, physics-informed neural networks, and medical imaging, MAdam consistently improves over Adam for every solver family.
MORI-Seg: Learning Morphological Geometry for Instance Segmentation without Instance Annotations
May 27, 2026Instance-level quantification of kidney functional units is essential for morphometric analysis, yet most publicly available pathology datasets provide only semantic segmentation annotations, where adjacent structures of the same class are merged into single regions. This prevents reliable instance-level analysis and limits downstream quantitative studies. Existing heuristic post-processing methods often yield suboptimal instance separation, particularly in crowded and adherent regions, while deep learning-based instance segmentation approaches typically require intensive instance-level annotations that are costly and labor-intensive to obtain. We propose MORI-Seg, a deep learning framework that enables instance segmentation without requiring instance-level annotations. Instead of heuristic splitting or instance supervision, MORI-Seg learns morphology-aware geometric representations directly from semantic masks by jointly modeling object-centric distance fields and boundary-band representations to encode interior structure and contact interfaces. A class-conditioned feature disentanglement module further promotes intra-instance coherence and inter-instance separation. Under semantic-only supervision, MORI-Seg decomposes connected semantic regions into distinct instance masks in an end-to-end manner. Experiments demonstrate improved instance separation accuracy and more reliable morphometric quantification compared with classical post-processing pipelines and representative semantic-to-instance learning approaches. The official implementation is publicly available at https://github.com/ddrrnn123/MORI-Seg.
DUET: Dual-Paradigm Adaptive Expert Triage with Single-cell Inductive Prior for Spatial Transcriptomics Prediction
May 13, 2026Inferring spatially resolved gene expression from histology images offers a cost-effective complement to spatial transcriptomics (ST). However, existing methods reduce this task to a simple morphology-to-expression mapping, where visual similarity does not guarantee molecular consistency. Meanwhile, single-cell data has amassed rich resources far surpassing the scale of ST data, yet it remains underexplored in vision-omics modeling. Furthermore, current approaches commit to a monolithic paradigm with bottlenecks, unable to balance expressive flexibility with biological fidelity. To bridge these gaps, we propose DUET, a novel dual-paradigm framework that synergizes parametric prediction and memory-based retrieval under cellular inductive priors. DUET implements a parallel regression-retrieval paradigm, adaptively reconciling the outputs of its complementary pathways. To mitigate aleatoric vision ambiguity, we incorporate large-scale single-cell references to impose molecular states as biological constraints for faithful learning. Building upon structural refinement, we further design a lightweight adapter to dynamically assign branch preference across spatial contexts to achieve optimal performance. Extensive experiments on three public datasets across varied gene scales demonstrate that DUET achieves SOTA performance, with consistent gains contributed by each proposed component. Code is available at https://github.com/Junchao-Zhu/DUET
Explainable Pathomics Feature Visualization via Correlation-aware Conditional Feature Editing
Feb 05, 2026Pathomics is a recent approach that offers rich quantitative features beyond what black-box deep learning can provide, supporting more reproducible and explainable biomarkers in digital pathology. However, many derived features (e.g., "second-order moment") remain difficult to interpret, especially across different clinical contexts, which limits their practical adoption. Conditional diffusion models show promise for explainability through feature editing, but they typically assume feature independence**--**an assumption violated by intrinsically correlated pathomics features. Consequently, editing one feature while fixing others can push the model off the biological manifold and produce unrealistic artifacts. To address this, we propose a Manifold-Aware Diffusion (MAD) framework for controllable and biologically plausible cell nuclei editing. Unlike existing approaches, our method regularizes feature trajectories within a disentangled latent space learned by a variational auto-encoder (VAE). This ensures that manipulating a target feature automatically adjusts correlated attributes to remain within the learned distribution of real cells. These optimized features then guide a conditional diffusion model to synthesize high-fidelity images. Experiments demonstrate that our approach is able to navigate the manifold of pathomics features when editing those features. The proposed method outperforms baseline methods in conditional feature editing while preserving structural coherence.
Patient-Conditioned Adaptive Offsets for Reliable Diagnosis across Subgroups
Jan 19, 2026AI models for medical diagnosis often exhibit uneven performance across patient populations due to heterogeneity in disease prevalence, imaging appearance, and clinical risk profiles. Existing algorithmic fairness approaches typically seek to reduce such disparities by suppressing sensitive attributes. However, in medical settings these attributes often carry essential diagnostic information, and removing them can degrade accuracy and reliability, particularly in high-stakes applications. In contrast, clinical decision making explicitly incorporates patient context when interpreting diagnostic evidence, suggesting a different design direction for subgroup-aware models. In this paper, we introduce HyperAdapt, a patient-conditioned adaptation framework that improves subgroup reliability while maintaining a shared diagnostic model. Clinically relevant attributes such as age and sex are encoded into a compact embedding and used to condition a hypernetwork-style module, which generates small residual modulation parameters for selected layers of a shared backbone. This design preserves the general medical knowledge learned by the backbone while enabling targeted adjustments that reflect patient-specific variability. To ensure efficiency and robustness, adaptations are constrained through low-rank and bottlenecked parameterizations, limiting both model complexity and computational overhead. Experiments across multiple public medical imaging benchmarks demonstrate that the proposed approach consistently improves subgroup-level performance without sacrificing overall accuracy. On the PAD-UFES-20 dataset, our method outperforms the strongest competing baseline by 4.1% in recall and 4.4% in F1 score, with larger gains observed for underrepresented patient populations.
SCR2-ST: Combine Single Cell with Spatial Transcriptomics for Efficient Active Sampling via Reinforcement Learning
Dec 15, 2025



Spatial transcriptomics (ST) is an emerging technology that enables researchers to investigate the molecular relationships underlying tissue morphology. However, acquiring ST data remains prohibitively expensive, and traditional fixed-grid sampling strategies lead to redundant measurements of morphologically similar or biologically uninformative regions, thus resulting in scarce data that constrain current methods. The well-established single-cell sequencing field, however, could provide rich biological data as an effective auxiliary source to mitigate this limitation. To bridge these gaps, we introduce SCR2-ST, a unified framework that leverages single-cell prior knowledge to guide efficient data acquisition and accurate expression prediction. SCR2-ST integrates a single-cell guided reinforcement learning-based (SCRL) active sampling and a hybrid regression-retrieval prediction network SCR2Net. SCRL combines single-cell foundation model embeddings with spatial density information to construct biologically grounded reward signals, enabling selective acquisition of informative tissue regions under constrained sequencing budgets. SCR2Net then leverages the actively sampled data through a hybrid architecture combining regression-based modeling with retrieval-augmented inference, where a majority cell-type filtering mechanism suppresses noisy matches and retrieved expression profiles serve as soft labels for auxiliary supervision. We evaluated SCR2-ST on three public ST datasets, demonstrating SOTA performance in both sampling efficiency and prediction accuracy, particularly under low-budget scenarios. Code is publicly available at: https://github.com/hrlblab/SCR2ST
From Classification to Cross-Modal Understanding: Leveraging Vision-Language Models for Fine-Grained Renal Pathology
Nov 15, 2025Fine-grained glomerular subtyping is central to kidney biopsy interpretation, but clinically valuable labels are scarce and difficult to obtain. Existing computational pathology approaches instead tend to evaluate coarse diseased classification under full supervision with image-only models, so it remains unclear how vision-language models (VLMs) should be adapted for clinically meaningful subtyping under data constraints. In this work, we model fine-grained glomerular subtyping as a clinically realistic few-shot problem and systematically evaluate both pathology-specialized and general-purpose vision-language models under this setting. We assess not only classification performance (accuracy, AUC, F1) but also the geometry of the learned representations, examining feature alignment between image and text embeddings and the separability of glomerular subtypes. By jointly analyzing shot count, model architecture and domain knowledge, and adaptation strategy, this study provides guidance for future model selection and training under real clinical data constraints. Our results indicate that pathology-specialized vision-language backbones, when paired with the vanilla fine-tuning, are the most effective starting point. Even with only 4-8 labeled examples per glomeruli subtype, these models begin to capture distinctions and show substantial gains in discrimination and calibration, though additional supervision continues to yield incremental improvements. We also find that the discrimination between positive and negative examples is as important as image-text alignment. Overall, our results show that supervision level and adaptation strategy jointly shape both diagnostic performance and multimodal structure, providing guidance for model selection, adaptation strategies, and annotation investment.
How Close Are We? Limitations and Progress of AI Models in Banff Lesion Scoring
Oct 31, 2025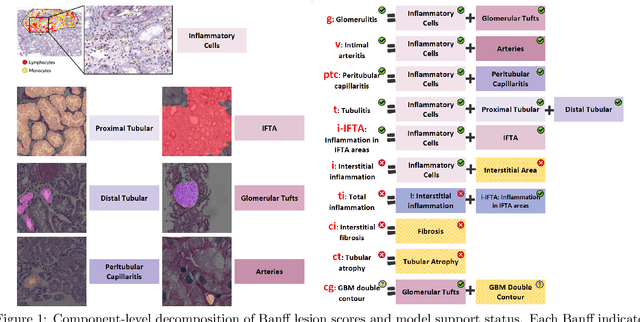
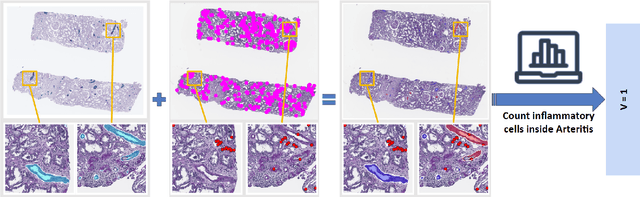
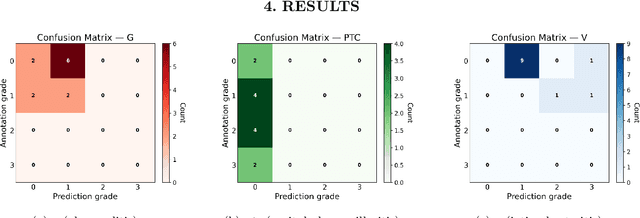
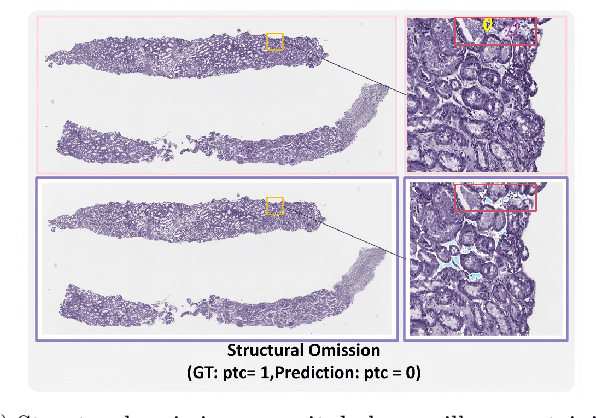
The Banff Classification provides the global standard for evaluating renal transplant biopsies, yet its semi-quantitative nature, complex criteria, and inter-observer variability present significant challenges for computational replication. In this study, we explore the feasibility of approximating Banff lesion scores using existing deep learning models through a modular, rule-based framework. We decompose each Banff indicator - such as glomerulitis (g), peritubular capillaritis (ptc), and intimal arteritis (v) - into its constituent structural and inflammatory components, and assess whether current segmentation and detection tools can support their computation. Model outputs are mapped to Banff scores using heuristic rules aligned with expert guidelines, and evaluated against expert-annotated ground truths. Our findings highlight both partial successes and critical failure modes, including structural omission, hallucination, and detection ambiguity. Even when final scores match expert annotations, inconsistencies in intermediate representations often undermine interpretability. These results reveal the limitations of current AI pipelines in replicating computational expert-level grading, and emphasize the importance of modular evaluation and computational Banff grading standard in guiding future model development for transplant pathology.
M^3-GloDets: Multi-Region and Multi-Scale Analysis of Fine-Grained Diseased Glomerular Detection
Aug 25, 2025Accurate detection of diseased glomeruli is fundamental to progress in renal pathology and underpins the delivery of reliable clinical diagnoses. Although recent advances in computer vision have produced increasingly sophisticated detection algorithms, the majority of research efforts have focused on normal glomeruli or instances of global sclerosis, leaving the wider spectrum of diseased glomerular subtypes comparatively understudied. This disparity is not without consequence; the nuanced and highly variable morphological characteristics that define these disease variants frequently elude even the most advanced computational models. Moreover, ongoing debate surrounds the choice of optimal imaging magnifications and region-of-view dimensions for fine-grained glomerular analysis, adding further complexity to the pursuit of accurate classification and robust segmentation. To bridge these gaps, we present M^3-GloDet, a systematic framework designed to enable thorough evaluation of detection models across a broad continuum of regions, scales, and classes. Within this framework, we evaluate both long-standing benchmark architectures and recently introduced state-of-the-art models that have achieved notable performance, using an experimental design that reflects the diversity of region-of-interest sizes and imaging resolutions encountered in routine digital renal pathology. As the results, we found that intermediate patch sizes offered the best balance between context and efficiency. Additionally, moderate magnifications enhanced generalization by reducing overfitting. Through systematic comparison of these approaches on a multi-class diseased glomerular dataset, our aim is to advance the understanding of model strengths and limitations, and to offer actionable insights for the refinement of automated detection strategies and clinical workflows in the digital pathology domain.
DyMorph-B2I: Dynamic and Morphology-Guided Binary-to-Instance Segmentation for Renal Pathology
Aug 21, 2025Accurate morphological quantification of renal pathology functional units relies on instance-level segmentation, yet most existing datasets and automated methods provide only binary (semantic) masks, limiting the precision of downstream analyses. Although classical post-processing techniques such as watershed, morphological operations, and skeletonization, are often used to separate semantic masks into instances, their individual effectiveness is constrained by the diverse morphologies and complex connectivity found in renal tissue. In this study, we present DyMorph-B2I, a dynamic, morphology-guided binary-to-instance segmentation pipeline tailored for renal pathology. Our approach integrates watershed, skeletonization, and morphological operations within a unified framework, complemented by adaptive geometric refinement and customizable hyperparameter tuning for each class of functional unit. Through systematic parameter optimization, DyMorph-B2I robustly separates adherent and heterogeneous structures present in binary masks. Experimental results demonstrate that our method outperforms individual classical approaches and na\"ive combinations, enabling superior instance separation and facilitating more accurate morphometric analysis in renal pathology workflows. The pipeline is publicly available at: https://github.com/ddrrnn123/DyMorph-B2I.