 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeROVE: Unlocking Human Interventions for Humanoid Manipulation via Reinforcement Learning
Jun 15, 2026Human interventions provide crucial corrective signals for post-training Vision-Language-Action (VLA) models. However, enabling seamless humanoid interventions is a formidable systems challenge due to complex whole-body kinematics and dexterous-hand control. Consequently, the collected intervention trajectories are often suboptimal, and methods that rely on human interventions as expert supervision can absorb hesitant, inefficient, or even erroneous behaviors. To address both the system and algorithmic challenges, we propose ROVE, a reinforcement learning framework for humanoid VLA post-training with imperfect human interventions. First, ROVE introduces a human-in-the-loop pipeline capable of collecting deployment and intervention data for humanoid manipulation. Second, it utilizes Optimistic Value Estimation (OVE) to prioritize high-value behaviors from mixed-quality trajectories. To further robustify value estimation, we incorporate cross-embodiment human experience videos to provide rich supervision for long-tailed failure and recovery modes. The resulting critic yields informative advantage signals, steering the VLA actor to focus on high-value behaviors rather than indiscriminately imitating all actions. On challenging real-world contact-rich and fine-grained humanoid manipulation tasks, ROVE outperforms experience-learning baselines and consistently improves across multiple rollout-intervention iterations.
Making Foresight Actionable: Repurposing Representation Alignment in World Action Models
Jun 10, 2026World Action Models (WAMs) offer a promising route for robot manipulation by using video generation models to model future scene evolution before producing control actions. However, our empirical observations reveal a phenomenon: generating plausible visual futures does not always guarantee the extraction of accurate actions. To diagnose this failure, we conduct action-head attention analysis and causal interventions. We find that the action decoder fails to focus on task-relevant interaction regions and remains sensitive to perturbations in task-irrelevant areas. This reveals a representation mismatch: hidden states optimized for visual reconstruction are not inherently organized in a form useful for low-level action control. In this paper, we propose AGRA, an Action-Grounded Representation Alignment objective that regularizes the world-action interface by aligning intermediate video diffusion features with spatially coherent semantic representations from a foundation visual encoder. We evaluate AGRA on real-world manipulation tasks. Experiments show that AGRA makes world model representations more action-grounded: by focusing the action decoder on the correct interaction regions, it improves object localization accuracy and affordance understanding, and makes the policy more robust to perturbations in task-irrelevant regions. As a result, AGRA consistently improves both in-distribution performance and out-of-distribution generalization over the baseline world action model.
Galilean State Estimation for Inertial Navigation Systems with Unknown Time Delay
May 13, 2026Many Inertial Navigation Systems (INS) use Global Navigation Satellite System (GNSS) position as the primary measurement to drive filter performance and bound error growth. However, commercial-grade GNSS receivers introduce unknown measurement delays ranging from 50 ms to 300 ms depending on sensor quality and operating mode. Such time delays can significantly degrade INS performance unless they are explicitly compensated for. Existing algorithms commonly estimate this delay offline, run the filter concurrently with GNSS measurements using buffered Inertial Measurement Unit (IMU) data, and predict the current state by forward-integrating buffered inertial measurements via IMU preintegration. The state-of-the-art online method is an Extended Kalman Filter (EKF) that explicitly models the time delay as a state parameter, which defines the preintegration duration. This paper introduces a novel geometric framework for modeling time-delayed INS, in which Galilean symmetry is leveraged to provide a joint representation of space and time for consistent state estimation. An Equivariant Filter (EqF) is derived for the coupled estimation of navigation states and time delay. Validation is performed on two fixed-wing Uncrewed Aerial Vehicles (UAV) with GNSS time lags of 90 ms and 120 ms. The test flights last two to three minutes. Simulations further investigate delays up to 500 ms and provide a statistical comparison against the state-of-the-art EKF. Results show that the EqF preserves accuracy and consistency, while the EKF lacks consistency and its performance degrades significantly with increasing measurement delays.
UniT: Toward a Unified Physical Language for Human-to-Humanoid Policy Learning and World Modeling
Apr 21, 2026Scaling humanoid foundation models is bottlenecked by the scarcity of robotic data. While massive egocentric human data offers a scalable alternative, bridging the cross-embodiment chasm remains a fundamental challenge due to kinematic mismatches. We introduce UniT (Unified Latent Action Tokenizer via Visual Anchoring), a framework that establishes a unified physical language for human-to-humanoid transfer. Grounded in the philosophy that heterogeneous kinematics share universal visual consequences, UniT employs a tri-branch cross-reconstruction mechanism: actions predict vision to anchor kinematics to physical outcomes, while vision reconstructs actions to filter out irrelevant visual confounders. Concurrently, a fusion branch synergies these purified modalities into a shared discrete latent space of embodiment-agnostic physical intents. We validate UniT across two paradigms: 1) Policy Learning (VLA-UniT): By predicting these unified tokens, it effectively leverages diverse human data to achieve state-of-the-art data efficiency and robust out-of-distribution (OOD) generalization on both humanoid simulation benchmark and real-world deployments, notably demonstrating zero-shot task transfer. 2) World Modeling (WM-UniT): By aligning cross-embodiment dynamics via unified tokens as conditions, it realizes direct human-to-humanoid action transfer. This alignment ensures that human data seamlessly translates into enhanced action controllability for humanoid video generation. Ultimately, by inducing a highly aligned cross-embodiment representation (empirically verified by t-SNE visualizations revealing the convergence of human and humanoid features into a shared manifold), UniT offers a scalable path to distill vast human knowledge into general-purpose humanoid capabilities.
DIAL: Decoupling Intent and Action via Latent World Modeling for End-to-End VLA
Mar 31, 2026The development of Vision-Language-Action (VLA) models has been significantly accelerated by pre-trained Vision-Language Models (VLMs). However, most existing end-to-end VLAs treat the VLM primarily as a multimodal encoder, directly mapping vision-language features to low-level actions. This paradigm underutilizes the VLM's potential in high-level decision making and introduces training instability, frequently degrading its rich semantic representations. To address these limitations, we introduce DIAL, a framework bridging high-level decision making and low-level motor execution through a differentiable latent intent bottleneck. Specifically, a VLM-based System-2 performs latent world modeling by synthesizing latent visual foresight within the VLM's native feature space; this foresight explicitly encodes intent and serves as the structural bottleneck. A lightweight System-1 policy then decodes this predicted intent together with the current observation into precise robot actions via latent inverse dynamics. To ensure optimization stability, we employ a two-stage training paradigm: a decoupled warmup phase where System-2 learns to predict latent futures while System-1 learns motor control under ground-truth future guidance within a unified feature space, followed by seamless end-to-end joint optimization. This enables action-aware gradients to refine the VLM backbone in a controlled manner, preserving pre-trained knowledge. Extensive experiments on the RoboCasa GR1 Tabletop benchmark show that DIAL establishes a new state-of-the-art, achieving superior performance with 10x fewer demonstrations than prior methods. Furthermore, by leveraging heterogeneous human demonstrations, DIAL learns physically grounded manipulation priors and exhibits robust zero-shot generalization to unseen objects and novel configurations during real-world deployment on a humanoid robot.
TimeLens: Rethinking Video Temporal Grounding with Multimodal LLMs
Dec 16, 2025This paper does not introduce a novel method but instead establishes a straightforward, incremental, yet essential baseline for video temporal grounding (VTG), a core capability in video understanding. While multimodal large language models (MLLMs) excel at various video understanding tasks, the recipes for optimizing them for VTG remain under-explored. In this paper, we present TimeLens, a systematic investigation into building MLLMs with strong VTG ability, along two primary dimensions: data quality and algorithmic design. We first expose critical quality issues in existing VTG benchmarks and introduce TimeLens-Bench, comprising meticulously re-annotated versions of three popular benchmarks with strict quality criteria. Our analysis reveals dramatic model re-rankings compared to legacy benchmarks, confirming the unreliability of prior evaluation standards. We also address noisy training data through an automated re-annotation pipeline, yielding TimeLens-100K, a large-scale, high-quality training dataset. Building on our data foundation, we conduct in-depth explorations of algorithmic design principles, yielding a series of meaningful insights and effective yet efficient practices. These include interleaved textual encoding for time representation, a thinking-free reinforcement learning with verifiable rewards (RLVR) approach as the training paradigm, and carefully designed recipes for RLVR training. These efforts culminate in TimeLens models, a family of MLLMs with state-of-the-art VTG performance among open-source models and even surpass proprietary models such as GPT-5 and Gemini-2.5-Flash. All codes, data, and models will be released to facilitate future research.
ARC-Chapter: Structuring Hour-Long Videos into Navigable Chapters and Hierarchical Summaries
Nov 18, 2025



The proliferation of hour-long videos (e.g., lectures, podcasts, documentaries) has intensified demand for efficient content structuring. However, existing approaches are constrained by small-scale training with annotations that are typical short and coarse, restricting generalization to nuanced transitions in long videos. We introduce ARC-Chapter, the first large-scale video chaptering model trained on over million-level long video chapters, featuring bilingual, temporally grounded, and hierarchical chapter annotations. To achieve this goal, we curated a bilingual English-Chinese chapter dataset via a structured pipeline that unifies ASR transcripts, scene texts, visual captions into multi-level annotations, from short title to long summaries. We demonstrate clear performance improvements with data scaling, both in data volume and label intensity. Moreover, we design a new evaluation metric termed GRACE, which incorporates many-to-one segment overlaps and semantic similarity, better reflecting real-world chaptering flexibility. Extensive experiments demonstrate that ARC-Chapter establishes a new state-of-the-art by a significant margin, outperforming the previous best by 14.0% in F1 score and 11.3% in SODA score. Moreover, ARC-Chapter shows excellent transferability, improving the state-of-the-art on downstream tasks like dense video captioning on YouCook2.
AudioStory: Generating Long-Form Narrative Audio with Large Language Models
Aug 27, 2025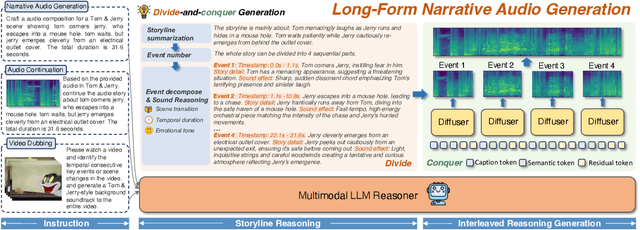
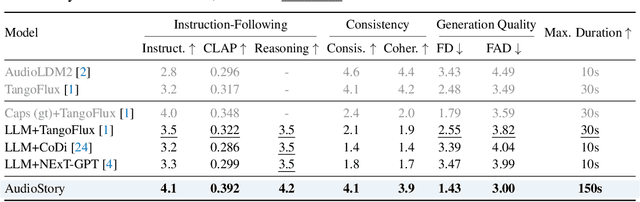
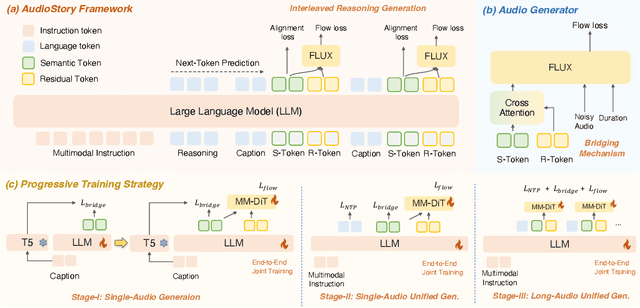

Recent advances in text-to-audio (TTA) generation excel at synthesizing short audio clips but struggle with long-form narrative audio, which requires temporal coherence and compositional reasoning. To address this gap, we propose AudioStory, a unified framework that integrates large language models (LLMs) with TTA systems to generate structured, long-form audio narratives. AudioStory possesses strong instruction-following reasoning generation capabilities. It employs LLMs to decompose complex narrative queries into temporally ordered sub-tasks with contextual cues, enabling coherent scene transitions and emotional tone consistency. AudioStory has two appealing features: (1) Decoupled bridging mechanism: AudioStory disentangles LLM-diffuser collaboration into two specialized components, i.e., a bridging query for intra-event semantic alignment and a residual query for cross-event coherence preservation. (2) End-to-end training: By unifying instruction comprehension and audio generation within a single end-to-end framework, AudioStory eliminates the need for modular training pipelines while enhancing synergy between components. Furthermore, we establish a benchmark AudioStory-10K, encompassing diverse domains such as animated soundscapes and natural sound narratives. Extensive experiments show the superiority of AudioStory on both single-audio generation and narrative audio generation, surpassing prior TTA baselines in both instruction-following ability and audio fidelity. Our code is available at https://github.com/TencentARC/AudioStory
ARC-Hunyuan-Video-7B: Structured Video Comprehension of Real-World Shorts
Jul 28, 2025Real-world user-generated short videos, especially those distributed on platforms such as WeChat Channel and TikTok, dominate the mobile internet. However, current large multimodal models lack essential temporally-structured, detailed, and in-depth video comprehension capabilities, which are the cornerstone of effective video search and recommendation, as well as emerging video applications. Understanding real-world shorts is actually challenging due to their complex visual elements, high information density in both visuals and audio, and fast pacing that focuses on emotional expression and viewpoint delivery. This requires advanced reasoning to effectively integrate multimodal information, including visual, audio, and text. In this work, we introduce ARC-Hunyuan-Video, a multimodal model that processes visual, audio, and textual signals from raw video inputs end-to-end for structured comprehension. The model is capable of multi-granularity timestamped video captioning and summarization, open-ended video question answering, temporal video grounding, and video reasoning. Leveraging high-quality data from an automated annotation pipeline, our compact 7B-parameter model is trained through a comprehensive regimen: pre-training, instruction fine-tuning, cold start, reinforcement learning (RL) post-training, and final instruction fine-tuning. Quantitative evaluations on our introduced benchmark ShortVid-Bench and qualitative comparisons demonstrate its strong performance in real-world video comprehension, and it supports zero-shot or fine-tuning with a few samples for diverse downstream applications. The real-world production deployment of our model has yielded tangible and measurable improvements in user engagement and satisfaction, a success supported by its remarkable efficiency, with stress tests indicating an inference time of just 10 seconds for a one-minute video on H20 GPU.
LoRA-Gen: Specializing Large Language Model via Online LoRA Generation
Jun 13, 2025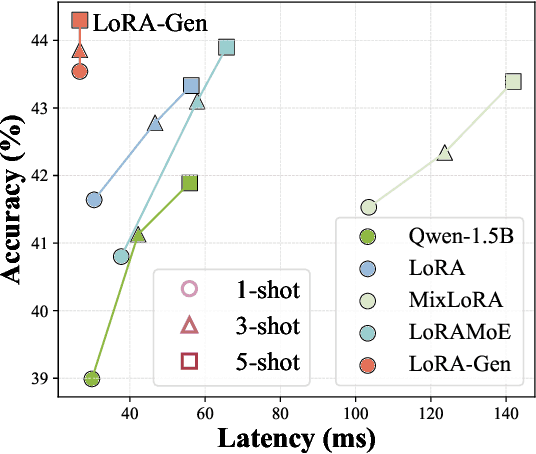

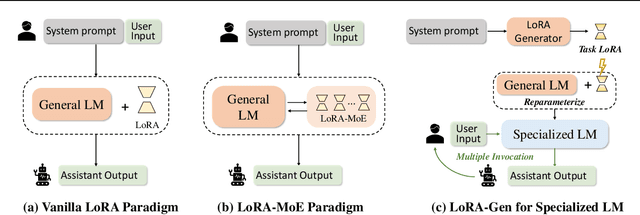
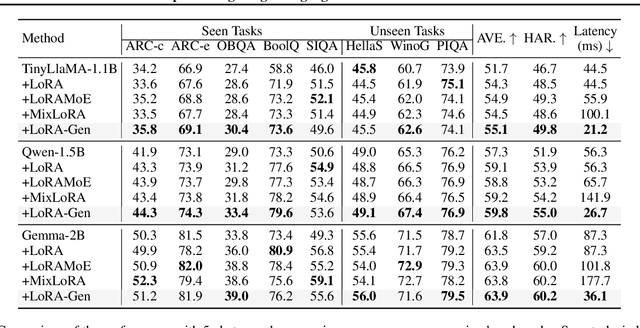
Recent advances have highlighted the benefits of scaling language models to enhance performance across a wide range of NLP tasks. However, these approaches still face limitations in effectiveness and efficiency when applied to domain-specific tasks, particularly for small edge-side models. We propose the LoRA-Gen framework, which utilizes a large cloud-side model to generate LoRA parameters for edge-side models based on task descriptions. By employing the reparameterization technique, we merge the LoRA parameters into the edge-side model to achieve flexible specialization. Our method facilitates knowledge transfer between models while significantly improving the inference efficiency of the specialized model by reducing the input context length. Without specialized training, LoRA-Gen outperforms conventional LoRA fine-tuning, which achieves competitive accuracy and a 2.1x speedup with TinyLLaMA-1.1B in reasoning tasks. Besides, our method delivers a compression ratio of 10.1x with Gemma-2B on intelligent agent tasks.