 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Completion for Occluded Person Re-Identification
Jun 24, 2021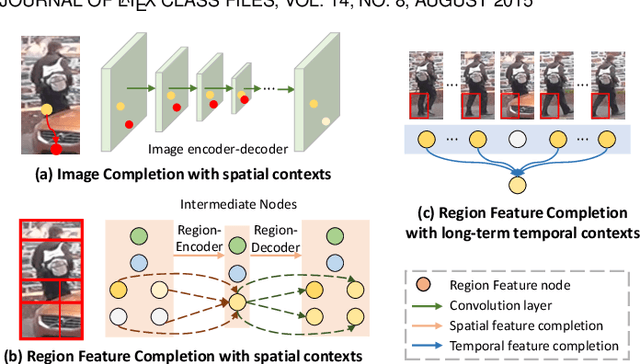
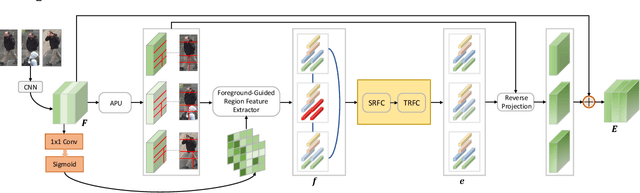
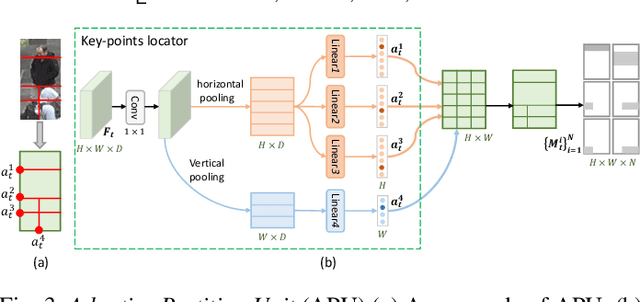

Person re-identification (reID) plays an important role in computer vision. However, existing methods suffer from performance degradation in occluded scenes. In this work, we propose an occlusion-robust block, Region Feature Completion (RFC), for occluded reID. Different from most previous works that discard the occluded regions, RFC block can recover the semantics of occluded regions in feature space. Firstly, a Spatial RFC (SRFC) module is developed. SRFC exploits the long-range spatial contexts from non-occluded regions to predict the features of occluded regions. The unit-wise prediction task leads to an encoder/decoder architecture, where the region-encoder models the correlation between non-occluded and occluded region, and the region-decoder utilizes the spatial correlation to recover occluded region features. Secondly, we introduce Temporal RFC (TRFC) module which captures the long-term temporal contexts to refine the prediction of SRFC. RFC block is lightweight, end-to-end trainable and can be easily plugged into existing CNNs to form RFCnet. Extensive experiments are conducted on occluded and commonly holistic reID benchmarks. Our method significantly outperforms existing methods on the occlusion datasets, while remains top even superior performance on holistic datasets. The source code is available at https://github.com/blue-blue272/OccludedReID-RFCnet.
* 18 pages, 17 figures. The paper is accepted by TPAMI, and the code is available at https://github.com/blue-blue272/OccludedReID-RFCnet
Continuity-Discrimination Convolutional Neural Network for Visual Object Tracking
Apr 18, 2021

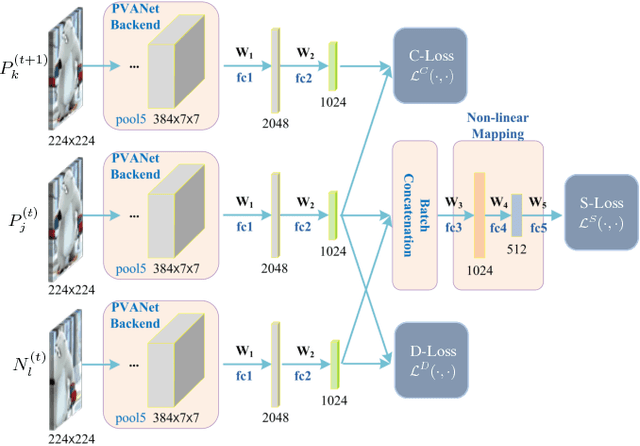

This paper proposes a novel model, named Continuity-Discrimination Convolutional Neural Network (CD-CNN), for visual object tracking. Existing state-of-the-art tracking methods do not deal with temporal relationship in video sequences, which leads to imperfect feature representations. To address this problem, CD-CNN models temporal appearance continuity based on the idea of temporal slowness. Mathematically, we prove that, by introducing temporal appearance continuity into tracking, the upper bound of target appearance representation error can be sufficiently small with high probability. Further, in order to alleviate inaccurate target localization and drifting, we propose a novel notion, object-centroid, to characterize not only objectness but also the relative position of the target within a given patch. Both temporal appearance continuity and object-centroid are jointly learned during offline training and then transferred for online tracking. We evaluate our tracker through extensive experiments on two challenging benchmarks and show its competitive tracking performance compared with state-of-the-art trackers.
Visual Alignment Constraint for Continuous Sign Language Recognition
Apr 06, 2021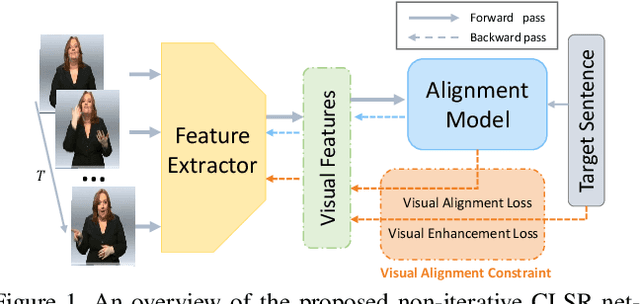

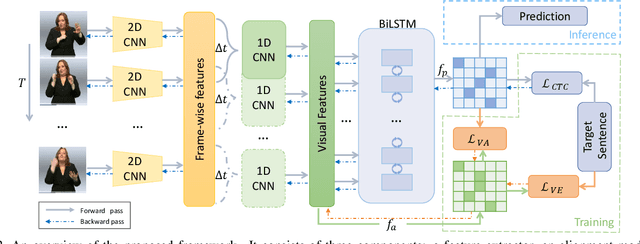
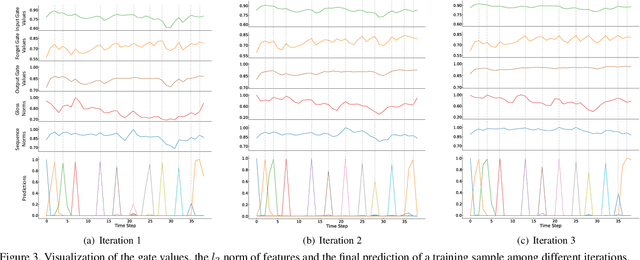
Vision-based Continuous Sign Language Recognition (CSLR) aims to recognize unsegmented gestures from image sequences. To better train CSLR models, the iterative training scheme is widely adopted to alleviate the overfitting of the alignment model. Although the iterative training scheme can improve performance, it will also increase the training time. In this work, we revisit the overfitting problem in recent CTC-based CSLR works and attribute it to the insufficient training of the feature extractor. To solve this problem, we propose a Visual Alignment Constraint (VAC) to enhance the feature extractor with more alignment supervision. Specifically, the proposed VAC is composed of two auxiliary losses: one makes predictions based on visual features only, and the other aligns short-term visual and long-term contextual features. Moreover, we further propose two metrics to evaluate the contributions of the feature extractor and the alignment model, which provide evidence for the overfitting problem. The proposed VAC achieves competitive performance on two challenging CSLR datasets and experimental results show its effectiveness.
Attributes Aware Face Generation with Generative Adversarial Networks
Dec 03, 2020
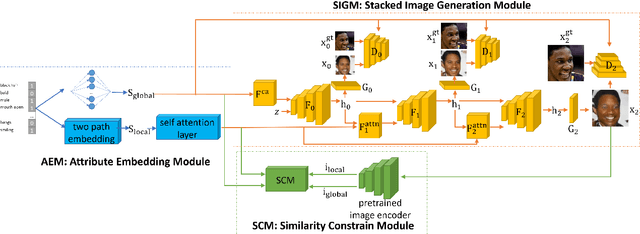
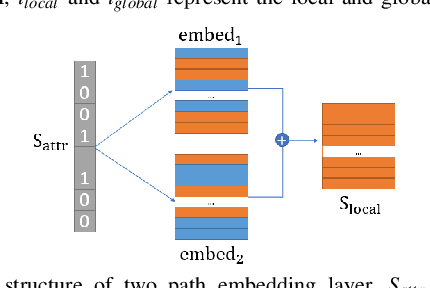

Recent studies have shown remarkable success in face image generations. However, most of the existing methods only generate face images from random noise, and cannot generate face images according to the specific attributes. In this paper, we focus on the problem of face synthesis from attributes, which aims at generating faces with specific characteristics corresponding to the given attributes. To this end, we propose a novel attributes aware face image generator method with generative adversarial networks called AFGAN. Specifically, we firstly propose a two-path embedding layer and self-attention mechanism to convert binary attribute vector to rich attribute features. Then three stacked generators generate $64 \times 64$, $128 \times 128$ and $256 \times 256$ resolution face images respectively by taking the attribute features as input. In addition, an image-attribute matching loss is proposed to enhance the correlation between the generated images and input attributes. Extensive experiments on CelebA demonstrate the superiority of our AFGAN in terms of both qualitative and quantitative evaluations.
Learn an Effective Lip Reading Model without Pains
Nov 15, 2020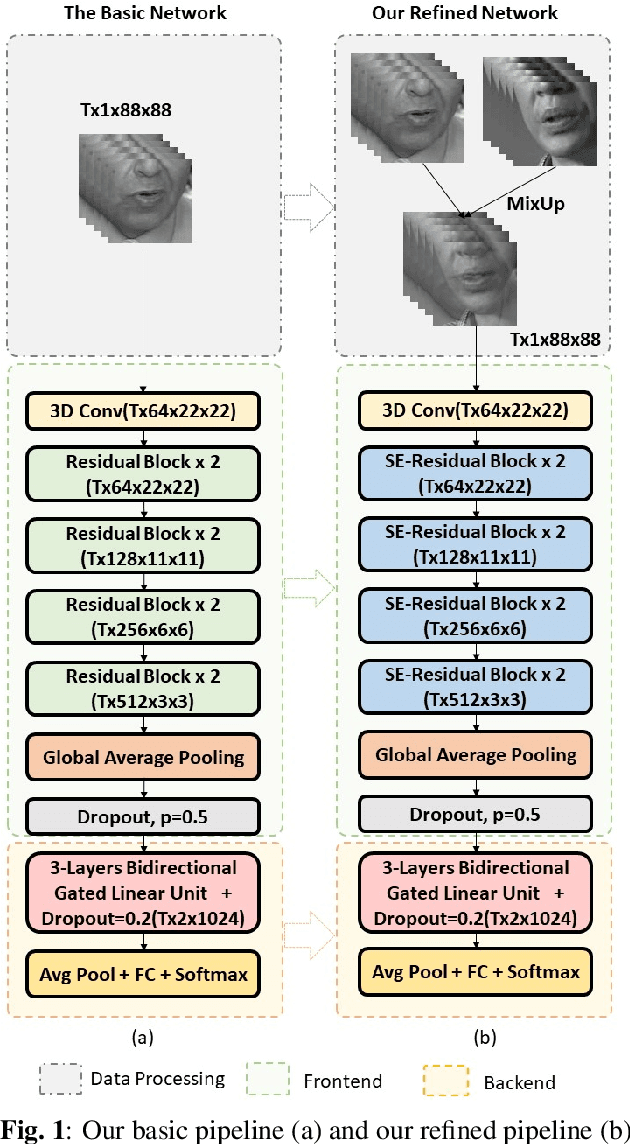
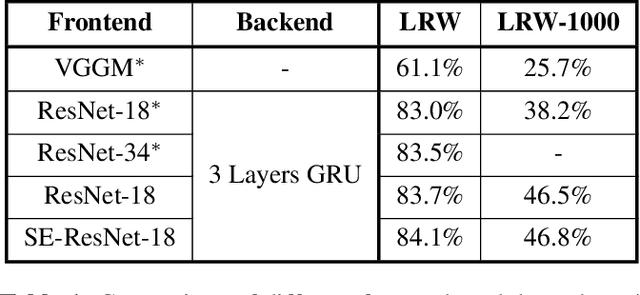
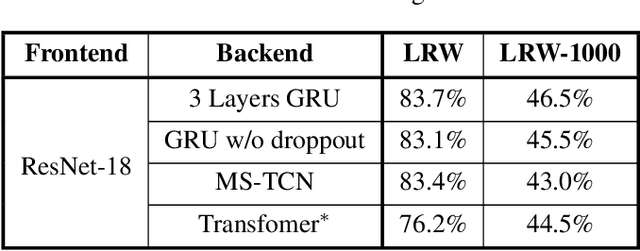
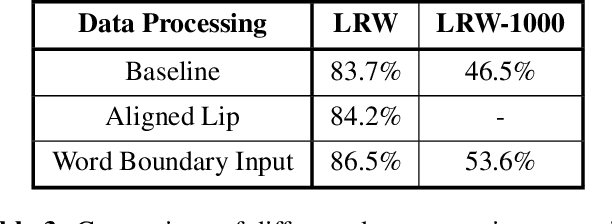
Lip reading, also known as visual speech recognition, aims to recognize the speech content from videos by analyzing the lip dynamics. There have been several appealing progress in recent years, benefiting much from the rapidly developed deep learning techniques and the recent large-scale lip-reading datasets. Most existing methods obtained high performance by constructing a complex neural network, together with several customized training strategies which were always given in a very brief description or even shown only in the source code. We find that making proper use of these strategies could always bring exciting improvements without changing much of the model. Considering the non-negligible effects of these strategies and the existing tough status to train an effective lip reading model, we perform a comprehensive quantitative study and comparative analysis, for the first time, to show the effects of several different choices for lip reading. By only introducing some easy-to-get refinements to the baseline pipeline, we obtain an obvious improvement of the performance from 83.7% to 88.4% and from 38.2% to 55.7% on two largest public available lip reading datasets, LRW and LRW-1000, respectively. They are comparable and even surpass the existing state-of-the-art results.
IAUnet: Global Context-Aware Feature Learning for Person Re-Identification
Sep 02, 2020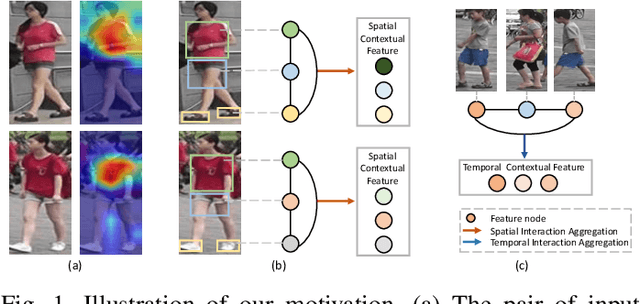
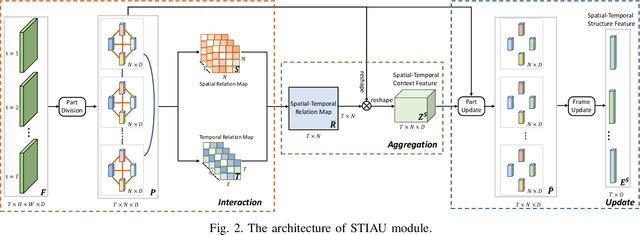
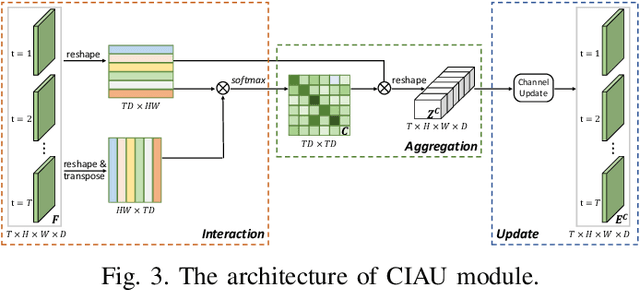

Person re-identification (reID) by CNNs based networks has achieved favorable performance in recent years. However, most of existing CNNs based methods do not take full advantage of spatial-temporal context modeling. In fact, the global spatial-temporal context can greatly clarify local distractions to enhance the target feature representation. To comprehensively leverage the spatial-temporal context information, in this work, we present a novel block, Interaction-Aggregation-Update (IAU), for high-performance person reID. Firstly, Spatial-Temporal IAU (STIAU) module is introduced. STIAU jointly incorporates two types of contextual interactions into a CNN framework for target feature learning. Here the spatial interactions learn to compute the contextual dependencies between different body parts of a single frame. While the temporal interactions are used to capture the contextual dependencies between the same body parts across all frames. Furthermore, a Channel IAU (CIAU) module is designed to model the semantic contextual interactions between channel features to enhance the feature representation, especially for small-scale visual cues and body parts. Therefore, the IAU block enables the feature to incorporate the globally spatial, temporal, and channel context. It is lightweight, end-to-end trainable, and can be easily plugged into existing CNNs to form IAUnet. The experiments show that IAUnet performs favorably against state-of-the-art on both image and video reID tasks and achieves compelling results on a general object categorization task. The source code is available at https://github.com/blue-blue272/ImgReID-IAnet.
Appearance-Preserving 3D Convolution for Video-based Person Re-identification
Jul 27, 2020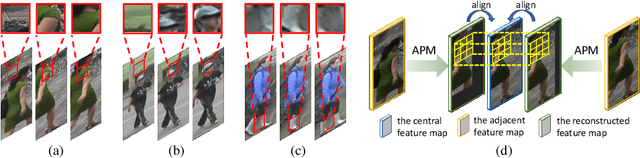
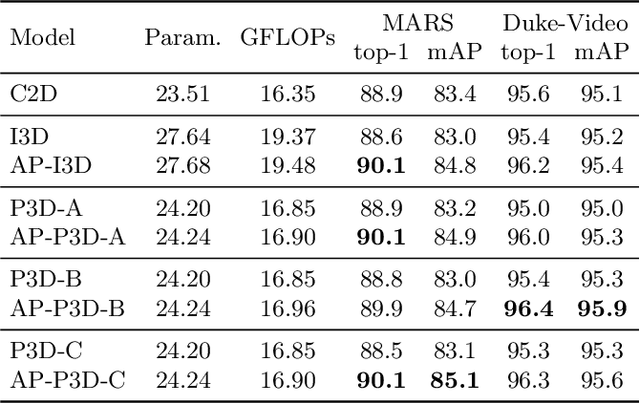
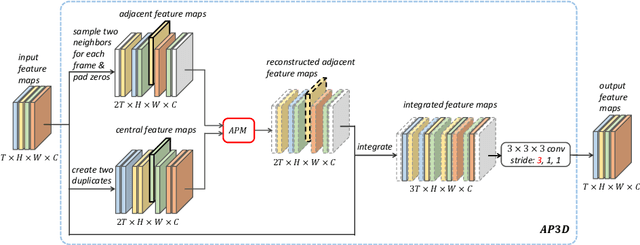
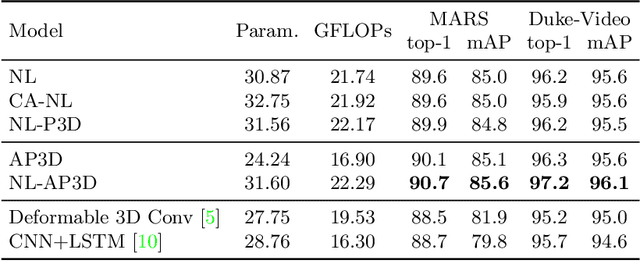
Due to the imperfect person detection results and posture changes, temporal appearance misalignment is unavoidable in video-based person re-identification (ReID). In this case, 3D convolution may destroy the appearance representation of person video clips, thus it is harmful to ReID. To address this problem, we propose AppearancePreserving 3D Convolution (AP3D), which is composed of two components: an Appearance-Preserving Module (APM) and a 3D convolution kernel. With APM aligning the adjacent feature maps in pixel level, the following 3D convolution can model temporal information on the premise of maintaining the appearance representation quality. It is easy to combine AP3D with existing 3D ConvNets by simply replacing the original 3D convolution kernels with AP3Ds. Extensive experiments demonstrate the effectiveness of AP3D for video-based ReID and the results on three widely used datasets surpass the state-of-the-arts. Code is available at: https://github.com/guxinqian/AP3D.
Temporal Complementary Learning for Video Person Re-Identification
Jul 18, 2020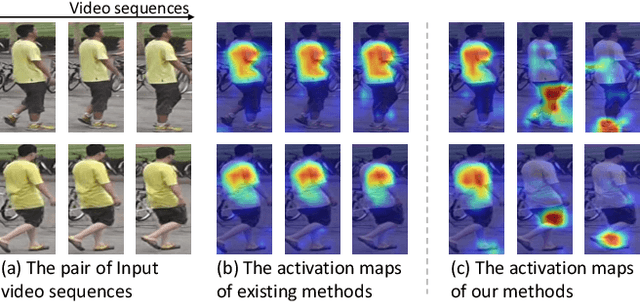
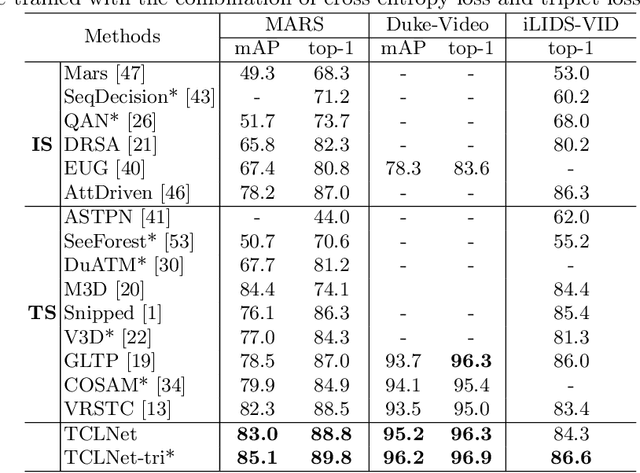
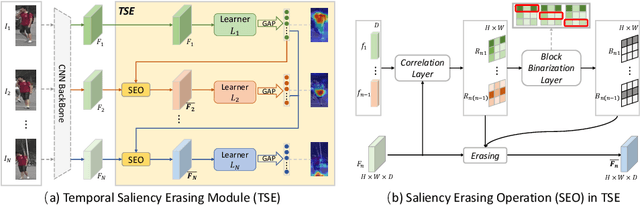
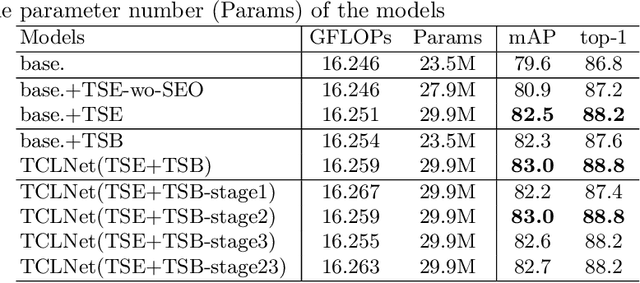
This paper proposes a Temporal Complementary Learning Network that extracts complementary features of consecutive video frames for video person re-identification. Firstly, we introduce a Temporal Saliency Erasing (TSE) module including a saliency erasing operation and a series of ordered learners. Specifically, for a specific frame of a video, the saliency erasing operation drives the specific learner to mine new and complementary parts by erasing the parts activated by previous frames. Such that the diverse visual features can be discovered for consecutive frames and finally form an integral characteristic of the target identity. Furthermore, a Temporal Saliency Boosting (TSB) module is designed to propagate the salient information among video frames to enhance the salient feature. It is complementary to TSE by effectively alleviating the information loss caused by the erasing operation of TSE. Extensive experiments show our method performs favorably against state-of-the-arts. The source code is available at https://github.com/blue-blue272/VideoReID-TCLNet.
Sketching Image Gist: Human-Mimetic Hierarchical Scene Graph Generation
Jul 17, 2020
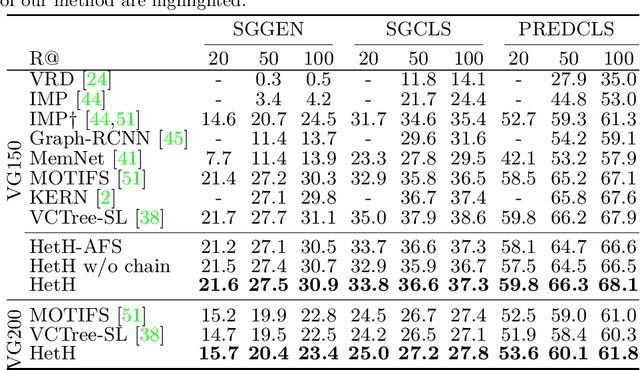
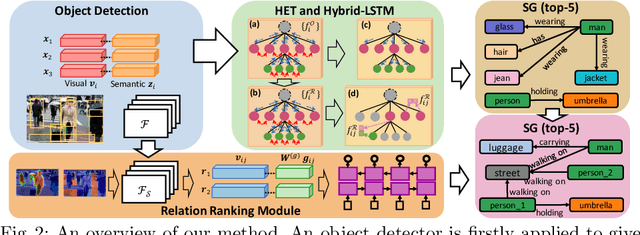
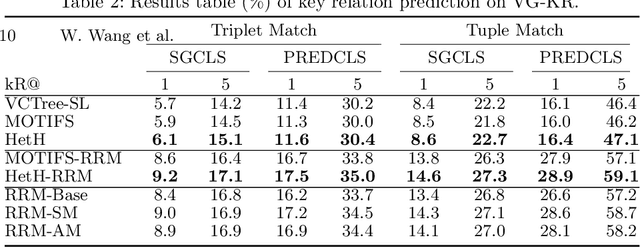
Scene graph aims to faithfully reveal humans' perception of image content. When humans analyze a scene, they usually prefer to describe image gist first, namely major objects and key relations in a scene graph. This humans' inherent perceptive habit implies that there exists a hierarchical structure about humans' preference during the scene parsing procedure. Therefore, we argue that a desirable scene graph should be also hierarchically constructed, and introduce a new scheme for modeling scene graph. Concretely, a scene is represented by a human-mimetic Hierarchical Entity Tree (HET) consisting of a series of image regions. To generate a scene graph based on HET, we parse HET with a Hybrid Long Short-Term Memory (Hybrid-LSTM) which specifically encodes hierarchy and siblings context to capture the structured information embedded in HET. To further prioritize key relations in the scene graph, we devise a Relation Ranking Module (RRM) to dynamically adjust their rankings by learning to capture humans' subjective perceptive habits from objective entity saliency and size. Experiments indicate that our method not only achieves state-of-the-art performances for scene graph generation, but also is expert in mining image-specific relations which play a great role in serving downstream tasks.
SegFix: Model-Agnostic Boundary Refinement for Segmentation
Jul 09, 2020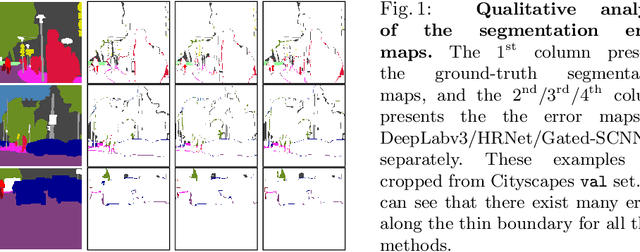
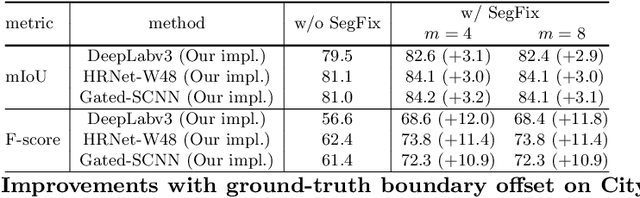
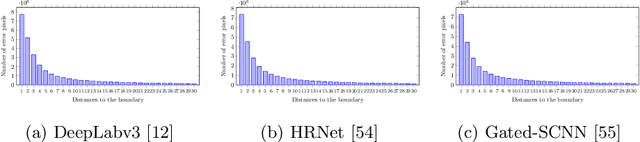
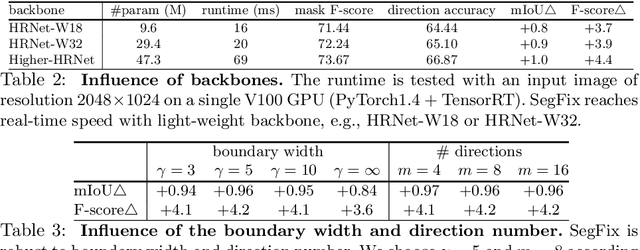
We present a model-agnostic post-processing scheme to improve the boundary quality for the segmentation result that is generated by any existing segmentation model. Motivated by the empirical observation that the label predictions of interior pixels are more reliable, we propose to replace the originally unreliable predictions of boundary pixels by the predictions of interior pixels. Our approach processes only the input image through two steps: (i) localize the boundary pixels and (ii) identify the corresponding interior pixel for each boundary pixel. We build the correspondence by learning a direction away from the boundary pixel to an interior pixel. Our method requires no prior information of the segmentation models and achieves nearly real-time speed. We empirically verify that our SegFix consistently reduces the boundary errors for segmentation results generated from various state-of-the-art models on Cityscapes, ADE20K and GTA5. Code is available at: https://github.com/openseg-group/openseg.pytorch.