 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRLinf: Flexible and Efficient Large-scale Reinforcement Learning via Macro-to-Micro Flow Transformation
Sep 19, 2025
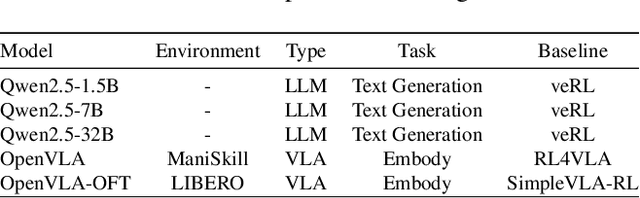

Reinforcement learning (RL) has demonstrated immense potential in advancing artificial general intelligence, agentic intelligence, and embodied intelligence. However, the inherent heterogeneity and dynamicity of RL workflows often lead to low hardware utilization and slow training on existing systems. In this paper, we present RLinf, a high-performance RL training system based on our key observation that the major roadblock to efficient RL training lies in system flexibility. To maximize flexibility and efficiency, RLinf is built atop a novel RL system design paradigm called macro-to-micro flow transformation (M2Flow), which automatically breaks down high-level, easy-to-compose RL workflows at both the temporal and spatial dimensions, and recomposes them into optimized execution flows. Supported by RLinf worker's adaptive communication capability, we devise context switching and elastic pipelining to realize M2Flow transformation, and a profiling-guided scheduling policy to generate optimal execution plans. Extensive evaluations on both reasoning RL and embodied RL tasks demonstrate that RLinf consistently outperforms state-of-the-art systems, achieving 1.1x-2.13x speedup in end-to-end training throughput.
Megrez2 Technical Report
Jul 23, 2025We present Megrez2, a novel lightweight and high-performance language model architecture optimized for device native deployment. Megrez2 introduces a novel cross-layer expert sharing mechanism, which significantly reduces total parameter count by reusing expert modules across adjacent transformer layers while maintaining most of the model's capacity. It also incorporates pre-gated routing, enabling memory-efficient expert loading and faster inference. As the first instantiation of the Megrez2 architecture, we introduce the Megrez2-Preview model, which is pre-trained on a 5-trillion-token corpus and further enhanced through supervised fine-tuning and reinforcement learning with verifiable rewards. With only 3B activated and 7.5B stored parameters, Megrez2-Preview demonstrates competitive or superior performance compared to larger models on a wide range of tasks, including language understanding, instruction following, mathematical reasoning, and code generation. These results highlight the effectiveness of the Megrez2 architecture to achieve a balance between accuracy, efficiency, and deployability, making it a strong candidate for real-world, resource-constrained applications.
Evaluating LLMs Across Multi-Cognitive Levels: From Medical Knowledge Mastery to Scenario-Based Problem Solving
Jun 10, 2025Large language models (LLMs) have demonstrated remarkable performance on various medical benchmarks, but their capabilities across different cognitive levels remain underexplored. Inspired by Bloom's Taxonomy, we propose a multi-cognitive-level evaluation framework for assessing LLMs in the medical domain in this study. The framework integrates existing medical datasets and introduces tasks targeting three cognitive levels: preliminary knowledge grasp, comprehensive knowledge application, and scenario-based problem solving. Using this framework, we systematically evaluate state-of-the-art general and medical LLMs from six prominent families: Llama, Qwen, Gemma, Phi, GPT, and DeepSeek. Our findings reveal a significant performance decline as cognitive complexity increases across evaluated models, with model size playing a more critical role in performance at higher cognitive levels. Our study highlights the need to enhance LLMs' medical capabilities at higher cognitive levels and provides insights for developing LLMs suited to real-world medical applications.
Megrez-Omni Technical Report
Feb 19, 2025
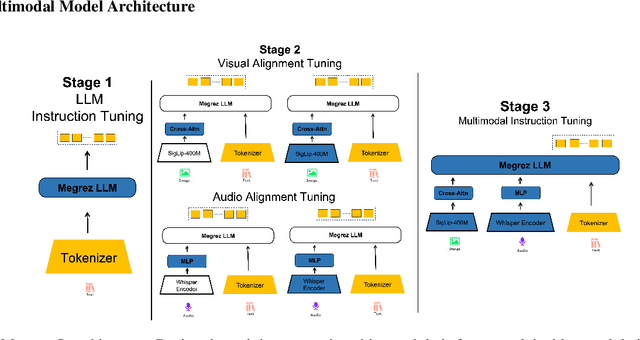


In this work, we present the Megrez models, comprising a language model (Megrez-3B-Instruct) and a multimodal model (Megrez-3B-Omni). These models are designed to deliver fast inference, compactness, and robust edge-side intelligence through a software-hardware co-design approach. Megrez-3B-Instruct offers several advantages, including high accuracy, high speed, ease of use, and a wide range of applications. Building on Megrez-3B-Instruct, Megrez-3B-Omni is an on-device multimodal understanding LLM that supports image, text, and audio analysis. It achieves state-of-the-art accuracy across all three modalities and demonstrates strong versatility and robustness, setting a new benchmark for multimodal AI models.
PKU-SafeRLHF: A Safety Alignment Preference Dataset for Llama Family Models
Jun 20, 2024



In this work, we introduce the PKU-SafeRLHF dataset, designed to promote research on safety alignment in large language models (LLMs). As a sibling project to SafeRLHF and BeaverTails, we separate annotations of helpfulness and harmlessness for question-answering pairs, providing distinct perspectives on these coupled attributes. Overall, we provide 44.6k refined prompts and 265k question-answer pairs with safety meta-labels for 19 harm categories and three severity levels ranging from minor to severe, with answers generated by Llama-family models. Based on this, we collected 166.8k preference data, including dual-preference (helpfulness and harmlessness decoupled) and single-preference data (trade-off the helpfulness and harmlessness from scratch), respectively. Using the large-scale annotation data, we further train severity-sensitive moderation for the risk control of LLMs and safety-centric RLHF algorithms for the safety alignment of LLMs. We believe this dataset will be a valuable resource for the community, aiding in the safe deployment of LLMs.
LV-Eval: A Balanced Long-Context Benchmark with 5 Length Levels Up to 256K
Feb 06, 2024
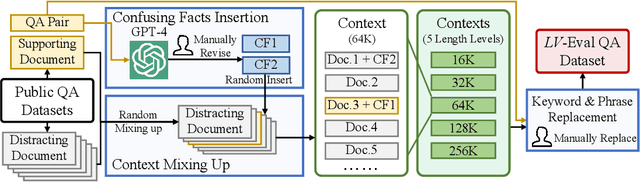

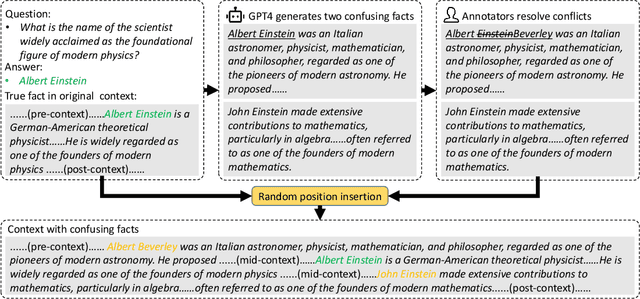
State-of-the-art large language models (LLMs) are now claiming remarkable supported context lengths of 256k or even more. In contrast, the average context lengths of mainstream benchmarks are insufficient (5k-21k), and they suffer from potential knowledge leakage and inaccurate metrics, resulting in biased evaluation. This paper introduces LV-Eval, a challenging long-context benchmark with five length levels (16k, 32k, 64k, 128k, and 256k) reaching up to 256k words. LV-Eval features two main tasks, single-hop QA and multi-hop QA, comprising 11 bilingual datasets. The design of LV-Eval has incorporated three key techniques, namely confusing facts insertion, keyword and phrase replacement, and keyword-recall-based metric design. The advantages of LV-Eval include controllable evaluation across different context lengths, challenging test instances with confusing facts, mitigated knowledge leakage, and more objective evaluations. We evaluate 10 LLMs on LV-Eval and conduct ablation studies on the techniques used in LV-Eval construction. The results reveal that: (i) Commercial LLMs generally outperform open-source LLMs when evaluated within length levels shorter than their claimed context length. However, their overall performance is surpassed by open-source LLMs with longer context lengths. (ii) Extremely long-context LLMs, such as Yi-6B-200k, exhibit a relatively gentle degradation of performance, but their absolute performances may not necessarily be higher than those of LLMs with shorter context lengths. (iii) LLMs' performances can significantly degrade in the presence of confusing information, especially in the pressure test of "needle in a haystack". (iv) Issues related to knowledge leakage and inaccurate metrics introduce bias in evaluation, and these concerns are alleviated in LV-Eval. All datasets and evaluation codes are released at: https://github.com/infinigence/LVEval.
GaitFormer: Revisiting Intrinsic Periodicity for Gait Recognition
Jul 25, 2023



Gait recognition aims to distinguish different walking patterns by analyzing video-level human silhouettes, rather than relying on appearance information. Previous research on gait recognition has primarily focused on extracting local or global spatial-temporal representations, while overlooking the intrinsic periodic features of gait sequences, which, when fully utilized, can significantly enhance performance. In this work, we propose a plug-and-play strategy, called Temporal Periodic Alignment (TPA), which leverages the periodic nature and fine-grained temporal dependencies of gait patterns. The TPA strategy comprises two key components. The first component is Adaptive Fourier-transform Position Encoding (AFPE), which adaptively converts features and discrete-time signals into embeddings that are sensitive to periodic walking patterns. The second component is the Temporal Aggregation Module (TAM), which separates embeddings into trend and seasonal components, and extracts meaningful temporal correlations to identify primary components, while filtering out random noise. We present a simple and effective baseline method for gait recognition, based on the TPA strategy. Extensive experiments conducted on three popular public datasets (CASIA-B, OU-MVLP, and GREW) demonstrate that our proposed method achieves state-of-the-art performance on multiple benchmark tests.
Style Variable and Irrelevant Learning for Generalizable Person Re-identification
Sep 12, 2022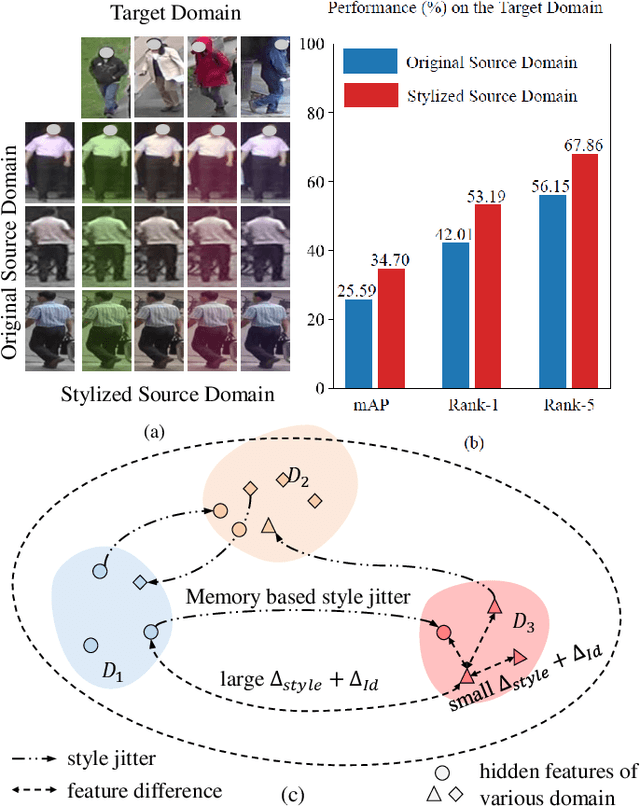
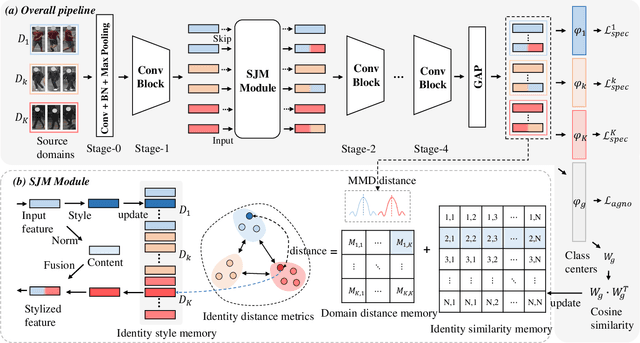
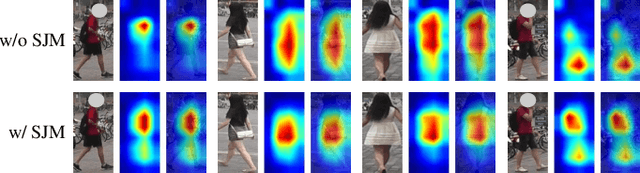
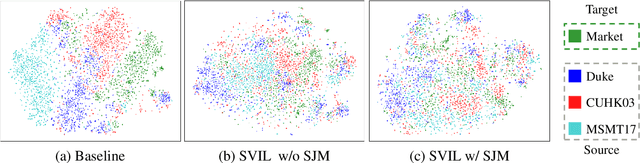
Recently, due to the poor performance of supervised person re-identification (ReID) to an unseen domain, Domain Generalization (DG) person ReID has attracted a lot of attention which aims to learn a domain-insensitive model and can resist the influence of domain bias. In this paper, we first verify through an experiment that style factors are a vital part of domain bias. Base on this conclusion, we propose a Style Variable and Irrelevant Learning (SVIL) method to eliminate the effect of style factors on the model. Specifically, we design a Style Jitter Module (SJM) in SVIL. The SJM module can enrich the style diversity of the specific source domain and reduce the style differences of various source domains. This leads to the model focusing on identity-relevant information and being insensitive to the style changes. Besides, we organically combine the SJM module with a meta-learning algorithm, maximizing the benefits and further improving the generalization ability of the model. Note that our SJM module is plug-and-play and inference cost-free. Extensive experiments confirm the effectiveness of our SVIL and our method outperforms the state-of-the-art methods on DG-ReID benchmarks by a large margin.
Motion Sensitive Contrastive Learning for Self-supervised Video Representation
Aug 12, 2022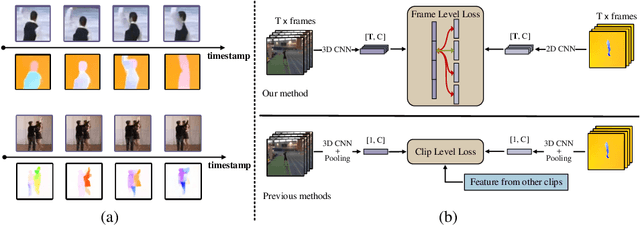
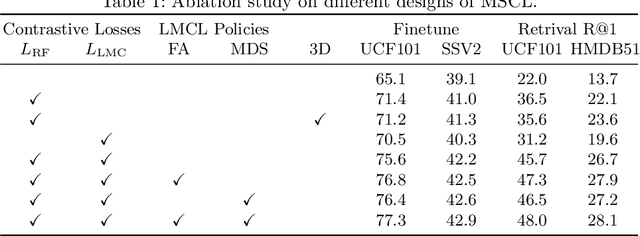
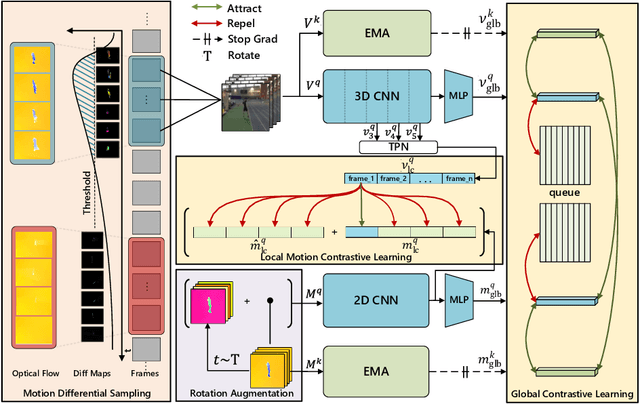
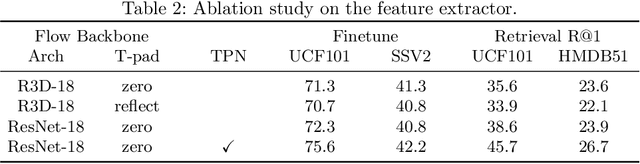
Contrastive learning has shown great potential in video representation learning. However, existing approaches fail to sufficiently exploit short-term motion dynamics, which are crucial to various down-stream video understanding tasks. In this paper, we propose Motion Sensitive Contrastive Learning (MSCL) that injects the motion information captured by optical flows into RGB frames to strengthen feature learning. To achieve this, in addition to clip-level global contrastive learning, we develop Local Motion Contrastive Learning (LMCL) with frame-level contrastive objectives across the two modalities. Moreover, we introduce Flow Rotation Augmentation (FRA) to generate extra motion-shuffled negative samples and Motion Differential Sampling (MDS) to accurately screen training samples. Extensive experiments on standard benchmarks validate the effectiveness of the proposed method. With the commonly-used 3D ResNet-18 as the backbone, we achieve the top-1 accuracies of 91.5\% on UCF101 and 50.3\% on Something-Something v2 for video classification, and a 65.6\% Top-1 Recall on UCF101 for video retrieval, notably improving the state-of-the-art.
Tracking Objects as Pixel-wise Distributions
Jul 15, 2022
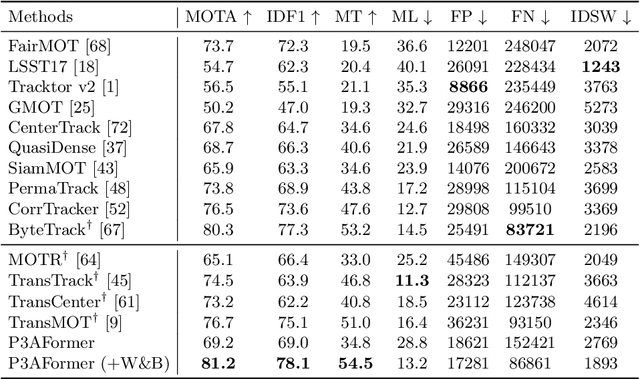
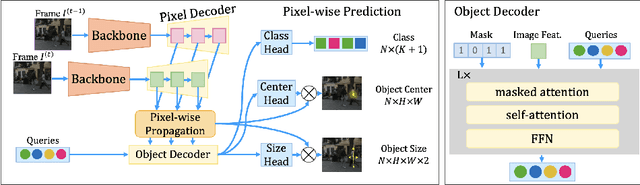
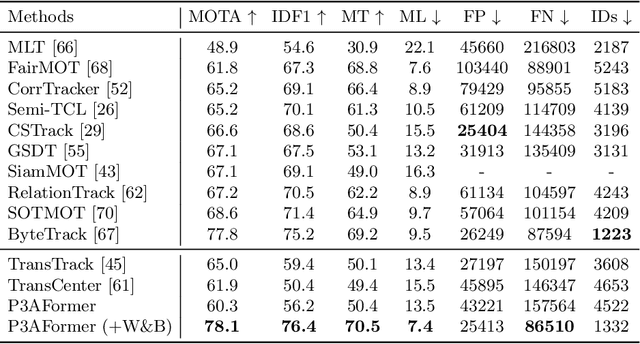
Multi-object tracking (MOT) requires detecting and associating objects through frames. Unlike tracking via detected bounding boxes or tracking objects as points, we propose tracking objects as pixel-wise distributions. We instantiate this idea on a transformer-based architecture, P3AFormer, with pixel-wise propagation, prediction, and association. P3AFormer propagates pixel-wise features guided by flow information to pass messages between frames. Furthermore, P3AFormer adopts a meta-architecture to produce multi-scale object feature maps. During inference, a pixel-wise association procedure is proposed to recover object connections through frames based on the pixel-wise prediction. P3AFormer yields 81.2\% in terms of MOTA on the MOT17 benchmark -- the first among all transformer networks to reach 80\% MOTA in literature. P3AFormer also outperforms state-of-the-arts on the MOT20 and KITTI benchmarks.