 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeMusic-Agent: Efficient Conversational Music Recommendation via Knowledge Internalization and Agentic Boundary Learning
Dec 18, 2025Personalized music recommendation in conversational scenarios usually requires a deep understanding of user preferences and nuanced musical context, yet existing methods often struggle with balancing specialized domain knowledge and flexible tool integration. This paper proposes WeMusic-Agent, a training framework for efficient LLM-based conversational music recommendation. By integrating the knowledge internalization and agentic boundary learning, the framework aims to teach the model to intelligently decide when to leverage internalized knowledge and when to call specialized tools (e.g., music retrieval APIs, music recommendation systems). Under this framework, we present WeMusic-Agent-M1, an agentic model that internalizes extensive musical knowledge via continued pretraining on 50B music-related corpus while acquiring the ability to invoke external tools when necessary. Additionally, considering the lack of open-source benchmarks for conversational music recommendation, we also construct a benchmark for personalized music recommendations derived from real-world data in WeChat Listen. This benchmark enables comprehensive evaluation across multiple dimensions, including relevance, personalization, and diversity of the recommendations. Experiments on real-world data demonstrate that WeMusic-Agent achieves significant improvements over existing models.
MuCPT: Music-related Natural Language Model Continued Pretraining
Nov 18, 2025


Large language models perform strongly on general tasks but remain constrained in specialized settings such as music, particularly in the music-entertainment domain, where corpus scale, purity, and the match between data and training objectives are critical. We address this by constructing a large, music-related natural language corpus (40B tokens) that combines open source and in-house data, and by implementing a domain-first data pipeline: a lightweight classifier filters and weights in-domain text, followed by multi-stage cleaning, de-duplication, and privacy-preserving masking. We further integrate multi-source music text with associated metadata to form a broader, better-structured foundation of domain knowledge. On the training side, we introduce reference-model (RM)-based token-level soft scoring for quality control: a unified loss-ratio criterion is used both for data selection and for dynamic down-weighting during optimization, reducing noise gradients and amplifying task-aligned signals, thereby enabling more effective music-domain continued pretraining and alignment. To assess factuality, we design the MusicSimpleQA benchmark, which adopts short, single-answer prompts with automated agreement scoring. Beyond the benchmark design, we conduct systematic comparisons along the axes of data composition. Overall, this work advances both the right corpus and the right objective, offering a scalable data-training framework and a reusable evaluation tool for building domain LLMs in the music field.
WIDER Face and Pedestrian Challenge 2018: Methods and Results
Feb 19, 2019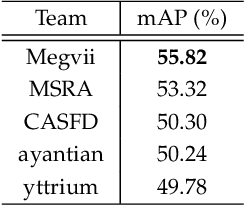

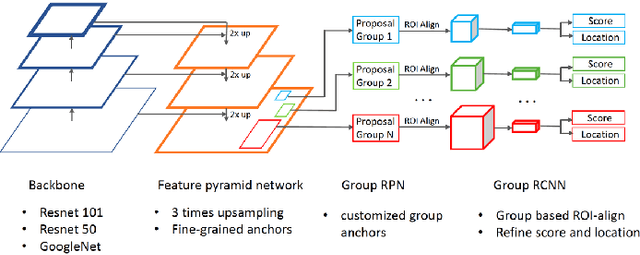
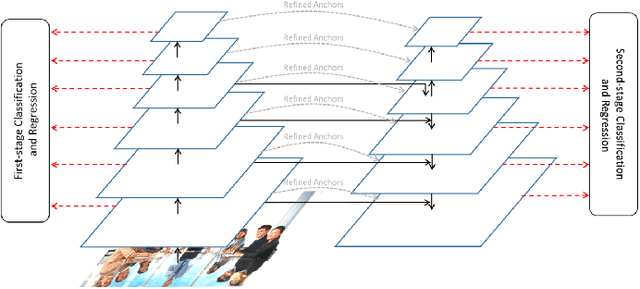
This paper presents a review of the 2018 WIDER Challenge on Face and Pedestrian. The challenge focuses on the problem of precise localization of human faces and bodies, and accurate association of identities. It comprises of three tracks: (i) WIDER Face which aims at soliciting new approaches to advance the state-of-the-art in face detection, (ii) WIDER Pedestrian which aims to find effective and efficient approaches to address the problem of pedestrian detection in unconstrained environments, and (iii) WIDER Person Search which presents an exciting challenge of searching persons across 192 movies. In total, 73 teams made valid submissions to the challenge tracks. We summarize the winning solutions for all three tracks. and present discussions on open problems and potential research directions in these topics.