 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Disentangled Slim Tensor Learning for Multi-view Clustering
Nov 12, 2024



Tensor-based multi-view clustering has recently received significant attention due to its exceptional ability to explore cross-view high-order correlations. However, most existing methods still encounter some limitations. (1) Most of them explore the correlations among different affinity matrices, making them unscalable to large-scale data. (2) Although some methods address it by introducing bipartite graphs, they may result in sub-optimal solutions caused by an unstable anchor selection process. (3) They generally ignore the negative impact of latent semantic-unrelated information in each view. To tackle these issues, we propose a new approach termed fast Disentangled Slim Tensor Learning (DSTL) for multi-view clustering . Instead of focusing on the multi-view graph structures, DSTL directly explores the high-order correlations among multi-view latent semantic representations based on matrix factorization. To alleviate the negative influence of feature redundancy, inspired by robust PCA, DSTL disentangles the latent low-dimensional representation into a semantic-unrelated part and a semantic-related part for each view. Subsequently, two slim tensors are constructed with tensor-based regularization. To further enhance the quality of feature disentanglement, the semantic-related representations are aligned across views through a consensus alignment indicator. Our proposed model is computationally efficient and can be solved effectively. Extensive experiments demonstrate the superiority and efficiency of DSTL over state-of-the-art approaches. The code of DSTL is available at https://github.com/dengxu-nju/DSTL.
DeMamba: AI-Generated Video Detection on Million-Scale GenVideo Benchmark
May 30, 2024



Recently, video generation techniques have advanced rapidly. Given the popularity of video content on social media platforms, these models intensify concerns about the spread of fake information. Therefore, there is a growing demand for detectors capable of distinguishing between fake AI-generated videos and mitigating the potential harm caused by fake information. However, the lack of large-scale datasets from the most advanced video generators poses a barrier to the development of such detectors. To address this gap, we introduce the first AI-generated video detection dataset, GenVideo. It features the following characteristics: (1) a large volume of videos, including over one million AI-generated and real videos collected; (2) a rich diversity of generated content and methodologies, covering a broad spectrum of video categories and generation techniques. We conducted extensive studies of the dataset and proposed two evaluation methods tailored for real-world-like scenarios to assess the detectors' performance: the cross-generator video classification task assesses the generalizability of trained detectors on generators; the degraded video classification task evaluates the robustness of detectors to handle videos that have degraded in quality during dissemination. Moreover, we introduced a plug-and-play module, named Detail Mamba (DeMamba), designed to enhance the detectors by identifying AI-generated videos through the analysis of inconsistencies in temporal and spatial dimensions. Our extensive experiments demonstrate DeMamba's superior generalizability and robustness on GenVideo compared to existing detectors. We believe that the GenVideo dataset and the DeMamba module will significantly advance the field of AI-generated video detection. Our code and dataset will be aviliable at \url{https://github.com/chenhaoxing/DeMamba}.
Segment Anything Model Meets Image Harmonization
Dec 20, 2023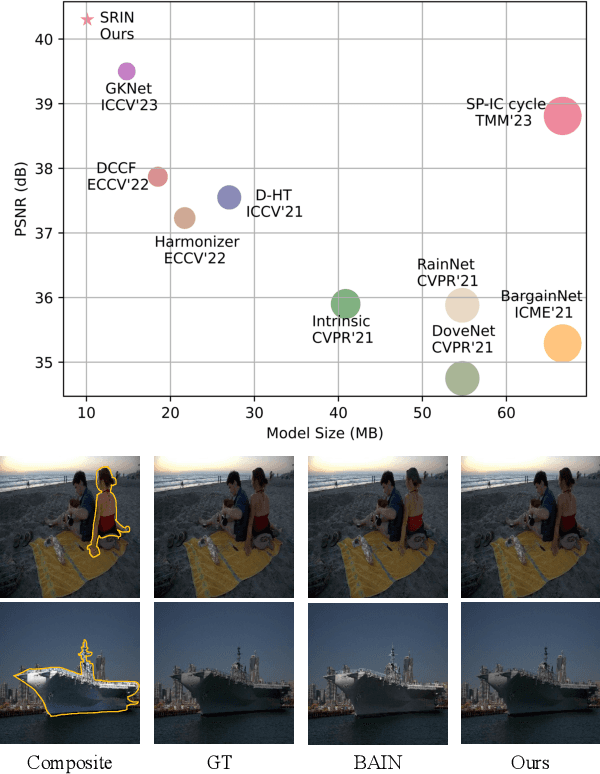
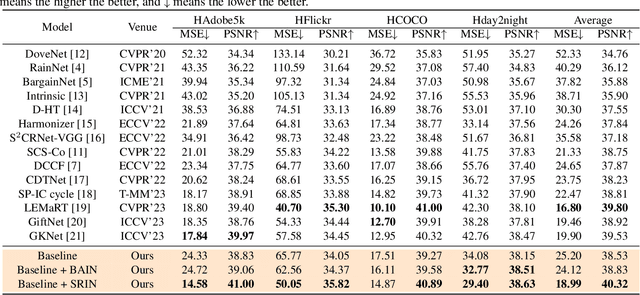
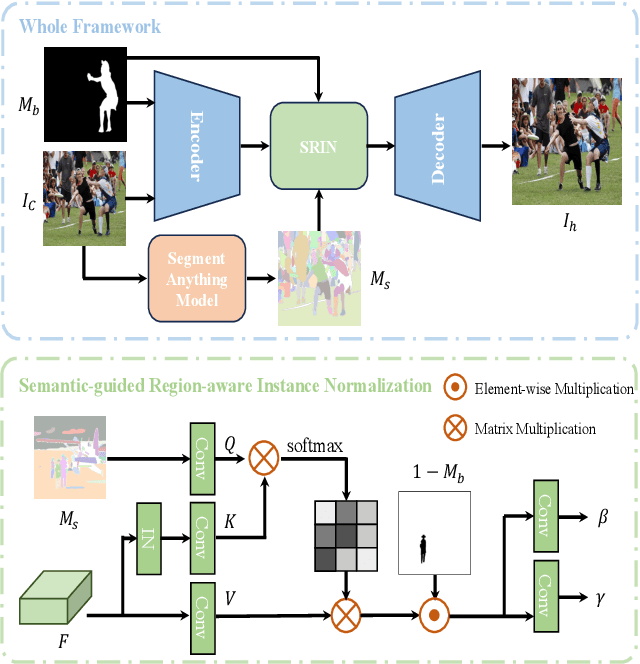
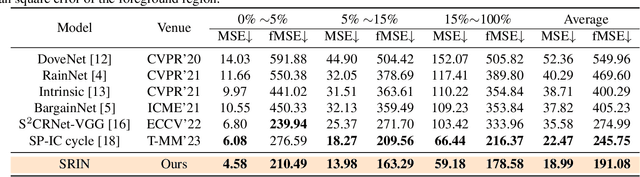
Image harmonization is a crucial technique in image composition that aims to seamlessly match the background by adjusting the foreground of composite images. Current methods adopt either global-level or pixel-level feature matching. Global-level feature matching ignores the proximity prior, treating foreground and background as separate entities. On the other hand, pixel-level feature matching loses contextual information. Therefore, it is necessary to use the information from semantic maps that describe different objects to guide harmonization. In this paper, we propose Semantic-guided Region-aware Instance Normalization (SRIN) that can utilize the semantic segmentation maps output by a pre-trained Segment Anything Model (SAM) to guide the visual consistency learning of foreground and background features. Abundant experiments demonstrate the superiority of our method for image harmonization over state-of-the-art methods.
Joint Projection Learning and Tensor Decomposition Based Incomplete Multi-view Clustering
Oct 06, 2023



Incomplete multi-view clustering (IMVC) has received increasing attention since it is often that some views of samples are incomplete in reality. Most existing methods learn similarity subgraphs from original incomplete multi-view data and seek complete graphs by exploring the incomplete subgraphs of each view for spectral clustering. However, the graphs constructed on the original high-dimensional data may be suboptimal due to feature redundancy and noise. Besides, previous methods generally ignored the graph noise caused by the inter-class and intra-class structure variation during the transformation of incomplete graphs and complete graphs. To address these problems, we propose a novel Joint Projection Learning and Tensor Decomposition Based method (JPLTD) for IMVC. Specifically, to alleviate the influence of redundant features and noise in high-dimensional data, JPLTD introduces an orthogonal projection matrix to project the high-dimensional features into a lower-dimensional space for compact feature learning.Meanwhile, based on the lower-dimensional space, the similarity graphs corresponding to instances of different views are learned, and JPLTD stacks these graphs into a third-order low-rank tensor to explore the high-order correlations across different views. We further consider the graph noise of projected data caused by missing samples and use a tensor-decomposition based graph filter for robust clustering.JPLTD decomposes the original tensor into an intrinsic tensor and a sparse tensor. The intrinsic tensor models the true data similarities. An effective optimization algorithm is adopted to solve the JPLTD model. Comprehensive experiments on several benchmark datasets demonstrate that JPLTD outperforms the state-of-the-art methods. The code of JPLTD is available at https://github.com/weilvNJU/JPLTD.
Contrastive Latent Space Reconstruction Learning for Audio-Text Retrieval
Sep 16, 2023


Cross-modal retrieval (CMR) has been extensively applied in various domains, such as multimedia search engines and recommendation systems. Most existing CMR methods focus on image-to-text retrieval, whereas audio-to-text retrieval, a less explored domain, has posed a great challenge due to the difficulty to uncover discriminative features from audio clips and texts. Existing studies are restricted in the following two ways: 1) Most researchers utilize contrastive learning to construct a common subspace where similarities among data can be measured. However, they considers only cross-modal transformation, neglecting the intra-modal separability. Besides, the temperature parameter is not adaptively adjusted along with semantic guidance, which degrades the performance. 2) These methods do not take latent representation reconstruction into account, which is essential for semantic alignment. This paper introduces a novel audio-text oriented CMR approach, termed Contrastive Latent Space Reconstruction Learning (CLSR). CLSR improves contrastive representation learning by taking intra-modal separability into account and adopting an adaptive temperature control strategy. Moreover, the latent representation reconstruction modules are embedded into the CMR framework, which improves modal interaction. Experiments in comparison with some state-of-the-art methods on two audio-text datasets have validated the superiority of CLSR.
Hierarchical Dynamic Image Harmonization
Nov 16, 2022Image harmonization is a critical task in computer vision, which aims to adjust the fore-ground to make it compatible with the back-ground. Recent works mainly focus on using global transformation (i.e., normalization and color curve rendering) to achieve visual consistency. However, these model ignore local consistency and their model size limit their harmonization ability on edge devices. Inspired by the dynamic deep networks that adapt the model structures or parameters conditioned on the inputs, we propose a hierarchical dynamic network (HDNet) for efficient image harmonization to adapt the model parameters and features from local to global view for better feature transformation. Specifically, local dynamics (LD) and mask-aware global dynamics (MGD) are applied. LD enables features of different channels and positions to change adaptively and improve the representation ability of geometric transformation through structural information learning. MGD learns the representations of fore- and back-ground regions and correlations to global harmonization. Experiments show that the proposed HDNet reduces more than 80\% parameters compared with previous methods but still achieves the state-of-the-art performance on the popular iHarmony4 dataset. Our code is avaliable in https://github.com/chenhaoxing/HDNet.
Model-Aware Contrastive Learning: Towards Escaping Uniformity-Tolerance Dilemma in Training
Jul 16, 2022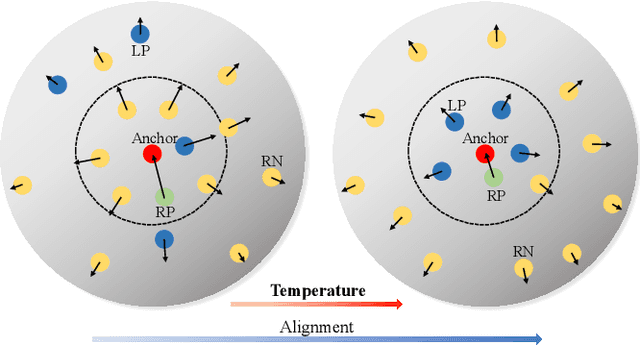
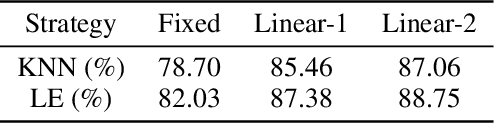
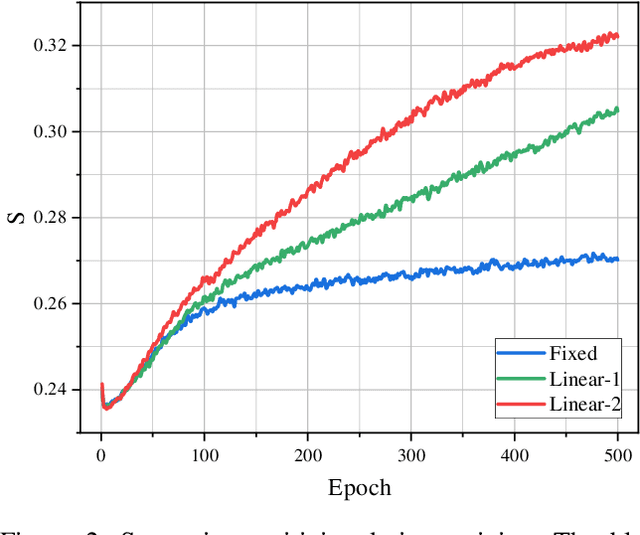
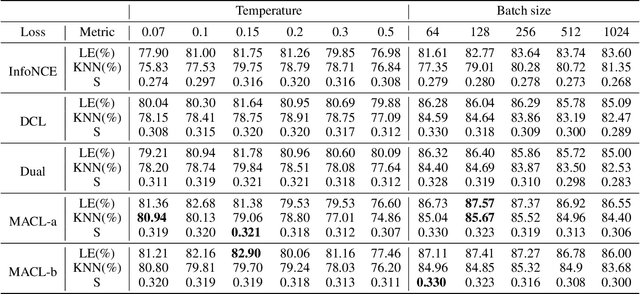
Instance discrimination contrastive learning (CL) has achieved significant success in learning transferable representations. A hardness-aware property related to the temperature $ \tau $ of the CL loss is identified to play an essential role in automatically concentrating on hard negative samples. However, previous work also proves that there exists a uniformity-tolerance dilemma (UTD) in CL loss, which will lead to unexpected performance degradation. Specifically, a smaller temperature helps to learn separable embeddings but has less tolerance to semantically related samples, which may result in suboptimal embedding space, and vice versa. In this paper, we propose a Model-Aware Contrastive Learning (MACL) strategy to escape UTD. For the undertrained phases, there is less possibility that the high similarity region of the anchor contains latent positive samples. Thus, adopting a small temperature in these stages can impose larger penalty strength on hard negative samples to improve the discrimination of the CL model. In contrast, a larger temperature in the well-trained phases helps to explore semantic structures due to more tolerance to potential positive samples. During implementation, the temperature in MACL is designed to be adaptive to the alignment property that reflects the confidence of a CL model. Furthermore, we reexamine why contrastive learning requires a large number of negative samples in a unified gradient reduction perspective. Based on MACL and these analyses, a new CL loss is proposed in this work to improve the learned representations and training with small batch size.
Shaping Visual Representations with Attributes for Few-Shot Learning
Dec 13, 2021
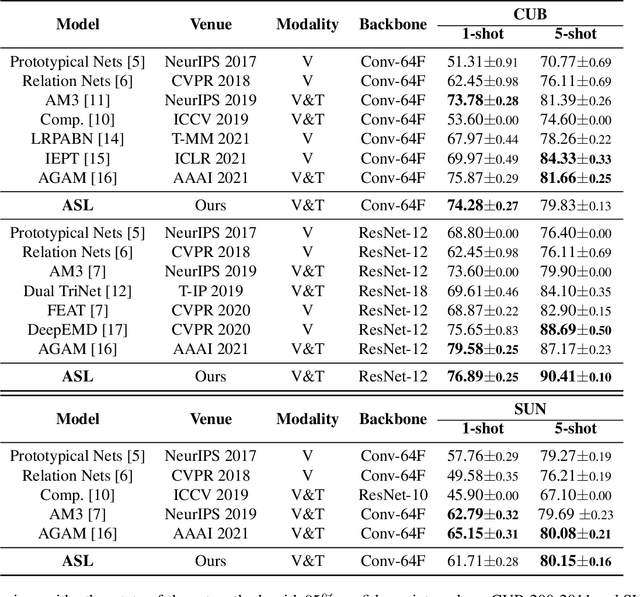
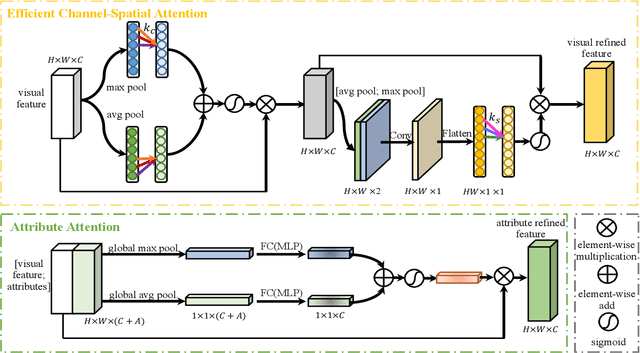
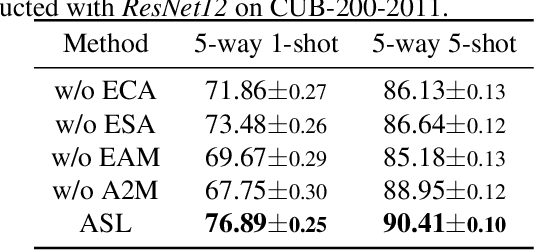
Few-shot recognition aims to recognize novel categories under low-data regimes. Due to the scarcity of images, machines cannot obtain enough effective information, and the generalization ability of the model is extremely weak. By using auxiliary semantic modalities, recent metric-learning based few-shot learning methods have achieved promising performances. However, these methods only augment the representations of support classes, while query images have no semantic modalities information to enhance representations. Instead, we propose attribute-shaped learning (ASL), which can normalize visual representations to predict attributes for query images. And we further devise an attribute-visual attention module (AVAM), which utilizes attributes to generate more discriminative features. Our method enables visual representations to focus on important regions with attributes guidance. Experiments demonstrate that our method can achieve competitive results on CUB and SUN benchmarks. Our code is available at {https://github.com/chenhaoxing/ASL}.
Sparse Spatial Transformers for Few-Shot Learning
Sep 27, 2021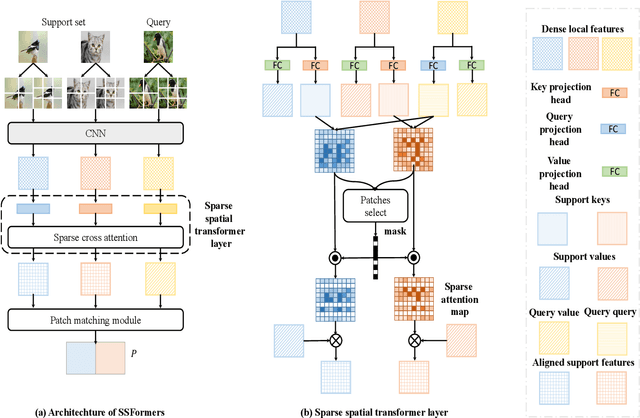
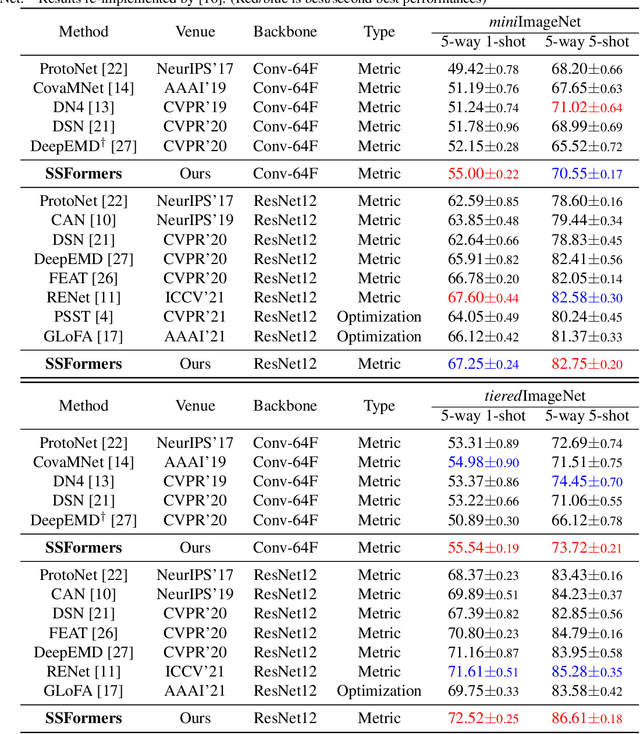


Learning from limited data is a challenging task since the scarcity of data leads to a poor generalization of the trained model. The classical global pooled representation is likely to lose useful local information. Recently, many few shot learning methods address this challenge by using deep descriptors and learning a pixel-level metric. However, using deep descriptors as feature representations may lose the contextual information of the image. And most of these methods deal with each class in the support set independently, which cannot sufficiently utilize discriminative information and task-specific embeddings. In this paper, we propose a novel Transformer based neural network architecture called Sparse Spatial Transformers (SSFormers), which can find task-relevant features and suppress task-irrelevant features. Specifically, we first divide each input image into several image patches of different sizes to obtain dense local features. These features retain contextual information while expressing local information. Then, a sparse spatial transformer layer is proposed to find spatial correspondence between the query image and the entire support set to select task-relevant image patches and suppress task-irrelevant image patches. Finally, we propose an image patch matching module to calculate the distance between dense local representations to determine which category the query image belongs to in the support set. Extensive experiments on popular few-shot learning benchmarks show that our method achieves the state-of-the-art performance. Our code is available at \url{https://github.com/chenhaoxing/SSFormers}.
Multi-level Metric Learning for Few-shot Image Recognition
Apr 12, 2021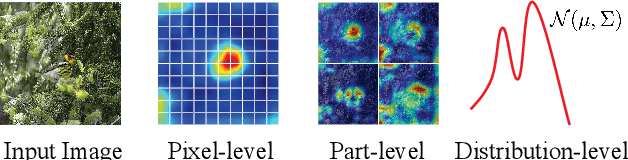
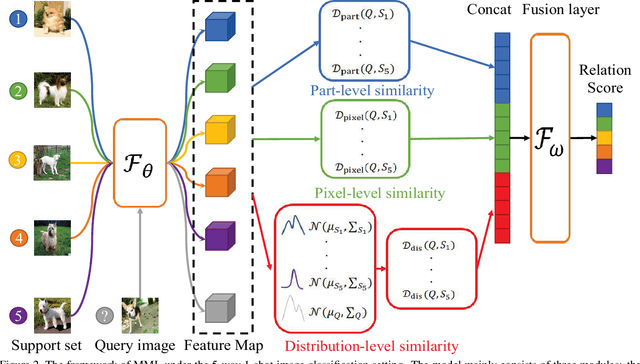
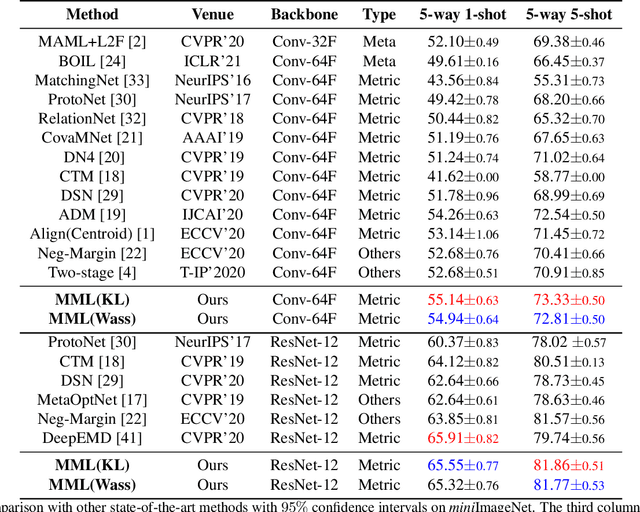
Few-shot learning is devoted to training a model on few samples. Recently, the method based on local descriptor metric-learning has achieved great performance. Most of these approaches learn a model based on a pixel-level metric. However, such works can only measure the relations between them on a single level, which is not comprehensive and effective. We argue that if query images can simultaneously be well classified via three distinct level similarity metrics, the query images within a class can be more tightly distributed in a smaller feature space, generating more discriminative feature maps. Motivated by this, we propose a novel Multi-level Metric Learning (MML) method for few-shot learning, which not only calculates the pixel-level similarity but also considers the similarity of part-level features and the similarity of distributions. First, we use a feature extractor to get the feature maps of images. Second, a multi-level metric module is proposed to calculate the part-level, pixel-level, and distribution-level similarities simultaneously. Specifically, the distribution-level similarity metric calculates the distribution distance (i.e., Wasserstein distance, Kullback-Leibler divergence) between query images and the support set, the pixel-level, and the part-level metric calculates the pixel-level and part-level similarities respectively. Finally, the fusion layer fuses three kinds of relation scores to obtain the final similarity score. Extensive experiments on popular benchmarks demonstrate that the MML method significantly outperforms the current state-of-the-art methods.