 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCyberJurors: A Multi-Agent Simulation Task for E-Commerce Disputes Verdict
May 27, 2026E-commerce platforms have begun recruiting crowdsourced jurors to adjudicate massive volumes of transaction disputes. Unlike formal legal judgment, E-commerce dispute verdicts require grounding pivotal clues from redundant, multi-round, multimodal evidence and making decisions under flexible platform-specific conventions. These characteristics render existing methods insufficient for this scenario. To bridge this gap, we introduce a pioneering task, E-commerce Dispute Verdicts (EDV), and present VerdictBench, a multimodal benchmark comprising 6,000 real-world cases designed to reflect crowdsourced jury decisions. Building upon this, we propose CyberJurors, a multi-agent framework to clarify the dispute logic and regulate the verdict process. At the individual level, Individual Verdict Chain-of-Thought decomposes the EDV task into four structured reasoning stages, enabling fine-grained clue perception and clarifying causal logic between pivotal clues and the dispute focus. At the collective level, Jury Consensus Verdict simulates multi-round discussion and voting among jurors, while incorporating verdict precedents to mitigate cognitive biases toward either disputant. Experiments on VerdictBench show that CyberJurors outperforms state-of-the-art LLMs, MLLMs, and court simulators, while achieving stronger alignment with real-world jury voting patterns. Code and dataset are available at https://github.com/YanhuiS/CyberJurors and https://huggingface.co/datasets/piggi/VerdictBench.
Rotation-Invariant Spherical Watermarking via Third-Order SO(3) Representation Coupling
May 26, 2026Reliable watermarking of panoramic imagery is fundamentally challenged by arbitrary 3D rotations. As panoramas are defined on the sphere, they naturally transform under the action of $SO(3)$, rendering conventional planar representations and augmentation-based robustness strategies inadequate and devoid of theoretical guarantees. To address this, we formulate panoramas as spherical signals and leverage $SO(3)$ representation theory to derive provably rotation-invariant descriptors. While spherical harmonic coefficients transform equivariantly under rotations, the natural invariant constructions are typically limited to zeroth-order statistics which eliminate directional information and severely constrain embedding capacity. In this work, we introduce a principled third-order invariant construction by coupling higher-order $SO(3)$ irreducible representations via tensor products and projecting onto the trivial representation. This yields a spherical invariant bispectrum that preserves phase information while remaining strictly rotation-invariant. Leveraging this property, we embed watermarks into higher-order spherical harmonic coefficients and recover them from invariant bispectral scalars, enabling reliable extraction under arbitrary 3D rotations. We provide a theoretical proof of $SO(3)$ invariance for it and demonstrate experimentally its near-perfect robustness to continuous rotations while maintaining high visual fidelity.
EMS: Multi-Agent Voting via Efficient Majority-then-Stopping
Apr 03, 2026Majority voting is the standard for aggregating multi-agent responses into a final decision. However, traditional methods typically require all agents to complete their reasoning before aggregation begins, leading to significant computational overhead, as many responses become redundant once a majority consensus is achieved. In this work, we formulate the multi-agent voting as a reliability-aware agent scheduling problem, and propose an Efficient Majority-then-Stopping (EMS) to improve reasoning efficiency. EMS prioritizes agents based on task-aware reliability and terminates the reasoning pipeline the moment a majority is achieved from the following three critical components. Specifically, we introduce Agent Confidence Modeling (ACM) to estimate agent reliability using historical performance and semantic similarity, Adaptive Incremental Voting (AIV) to sequentially select agents with early stopping, and Individual Confidence Updating (ICU) to dynamically update the reliability of each contributing agent. Extensive evaluations across six benchmarks demonstrate that EMS consistently reduces the average number of invoked agents by 32%.
A Paradigm Shift: Fully End-to-End Training for Temporal Sentence Grounding in Videos
Apr 03, 2026Temporal sentence grounding in videos (TSGV) aims to localize a temporal segment that semantically corresponds to a sentence query from an untrimmed video. Most current methods adopt pre-trained query-agnostic visual encoders for offline feature extraction, and the video backbones are frozen and not optimized for TSGV. This leads to a task discrepancy issue for the video backbone trained for visual classification, but utilized for TSGV. To bridge this gap, we propose a fully end-to-end paradigm that jointly optimizes the video backbone and localization head. We first conduct an empirical study validating the effectiveness of end-to-end learning over frozen baselines across different model scales. Furthermore, we introduce a Sentence Conditioned Adapter (SCADA), which leverages sentence features to train a small portion of video backbone parameters adaptively. SCADA facilitates the deployment of deeper network backbones with reduced memory and significantly enhances visual representation by modulating feature maps through precise integration of linguistic embeddings. Experiments on two benchmarks show that our method outperforms state-of-the-art approaches. The code and models will be released.
Rel-Zero: Harnessing Patch-Pair Invariance for Robust Zero-Watermarking Against AI Editing
Mar 18, 2026Recent advancements in diffusion-based image editing pose a significant threat to the authenticity of digital visual content. Traditional embedding-based watermarking methods often introduce perceptible perturbations to maintain robustness, inevitably compromising visual fidelity. Meanwhile, existing zero-watermarking approaches, typically relying on global image features, struggle to withstand sophisticated manipulations. In this work, we uncover a key observation: while individual image patches undergo substantial alterations during AI-based editing, the relational distance between patch pairs remains relatively invariant. Leveraging this property, we propose Relational Zero-Watermarking (Rel-Zero), a novel framework that requires no modification to the original image but derives a unique zero-watermark from these editing-invariant patch relations. By grounding the watermark in intrinsic structural consistency rather than absolute appearance, Rel-Zero provides a non-invasive yet resilient mechanism for content authentication. Extensive experiments demonstrate that Rel-Zero achieves substantially improved robustness across diverse editing models and manipulations compared to prior zero-watermarking approaches.
GUI-Eyes: Tool-Augmented Perception for Visual Grounding in GUI Agents
Jan 14, 2026Recent advances in vision-language models (VLMs) and reinforcement learning (RL) have driven progress in GUI automation. However, most existing methods rely on static, one-shot visual inputs and passive perception, lacking the ability to adaptively determine when, whether, and how to observe the interface. We present GUI-Eyes, a reinforcement learning framework for active visual perception in GUI tasks. To acquire more informative observations, the agent learns to make strategic decisions on both whether and how to invoke visual tools, such as cropping or zooming, within a two-stage reasoning process. To support this behavior, we introduce a progressive perception strategy that decomposes decision-making into coarse exploration and fine-grained grounding, coordinated by a two-level policy. In addition, we design a spatially continuous reward function tailored to tool usage, which integrates both location proximity and region overlap to provide dense supervision and alleviate the reward sparsity common in GUI environments. On the ScreenSpot-Pro benchmark, GUI-Eyes-3B achieves 44.8% grounding accuracy using only 3k labeled samples, significantly outperforming both supervised and RL-based baselines. These results highlight that tool-aware active perception, enabled by staged policy reasoning and fine-grained reward feedback, is critical for building robust and data-efficient GUI agents.
Region-Constraint In-Context Generation for Instructional Video Editing
Dec 19, 2025



The In-context generation paradigm recently has demonstrated strong power in instructional image editing with both data efficiency and synthesis quality. Nevertheless, shaping such in-context learning for instruction-based video editing is not trivial. Without specifying editing regions, the results can suffer from the problem of inaccurate editing regions and the token interference between editing and non-editing areas during denoising. To address these, we present ReCo, a new instructional video editing paradigm that novelly delves into constraint modeling between editing and non-editing regions during in-context generation. Technically, ReCo width-wise concatenates source and target video for joint denoising. To calibrate video diffusion learning, ReCo capitalizes on two regularization terms, i.e., latent and attention regularization, conducting on one-step backward denoised latents and attention maps, respectively. The former increases the latent discrepancy of the editing region between source and target videos while reducing that of non-editing areas, emphasizing the modification on editing area and alleviating outside unexpected content generation. The latter suppresses the attention of tokens in the editing region to the tokens in counterpart of the source video, thereby mitigating their interference during novel object generation in target video. Furthermore, we propose a large-scale, high-quality video editing dataset, i.e., ReCo-Data, comprising 500K instruction-video pairs to benefit model training. Extensive experiments conducted on four major instruction-based video editing tasks demonstrate the superiority of our proposal.
MotionPro: A Precise Motion Controller for Image-to-Video Generation
May 26, 2025

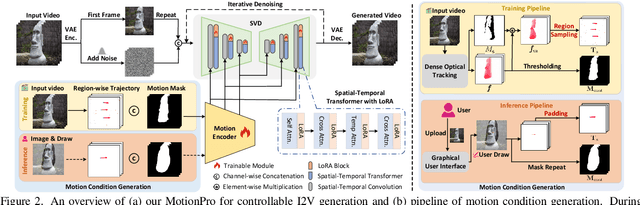

Animating images with interactive motion control has garnered popularity for image-to-video (I2V) generation. Modern approaches typically rely on large Gaussian kernels to extend motion trajectories as condition without explicitly defining movement region, leading to coarse motion control and failing to disentangle object and camera moving. To alleviate these, we present MotionPro, a precise motion controller that novelly leverages region-wise trajectory and motion mask to regulate fine-grained motion synthesis and identify target motion category (i.e., object or camera moving), respectively. Technically, MotionPro first estimates the flow maps on each training video via a tracking model, and then samples the region-wise trajectories to simulate inference scenario. Instead of extending flow through large Gaussian kernels, our region-wise trajectory approach enables more precise control by directly utilizing trajectories within local regions, thereby effectively characterizing fine-grained movements. A motion mask is simultaneously derived from the predicted flow maps to capture the holistic motion dynamics of the movement regions. To pursue natural motion control, MotionPro further strengthens video denoising by incorporating both region-wise trajectories and motion mask through feature modulation. More remarkably, we meticulously construct a benchmark, i.e., MC-Bench, with 1.1K user-annotated image-trajectory pairs, for the evaluation of both fine-grained and object-level I2V motion control. Extensive experiments conducted on WebVid-10M and MC-Bench demonstrate the effectiveness of MotionPro. Please refer to our project page for more results: https://zhw-zhang.github.io/MotionPro-page/.
HOIGen-1M: A Large-scale Dataset for Human-Object Interaction Video Generation
Mar 31, 2025Text-to-video (T2V) generation has made tremendous progress in generating complicated scenes based on texts. However, human-object interaction (HOI) often cannot be precisely generated by current T2V models due to the lack of large-scale videos with accurate captions for HOI. To address this issue, we introduce HOIGen-1M, the first largescale dataset for HOI Generation, consisting of over one million high-quality videos collected from diverse sources. In particular, to guarantee the high quality of videos, we first design an efficient framework to automatically curate HOI videos using the powerful multimodal large language models (MLLMs), and then the videos are further cleaned by human annotators. Moreover, to obtain accurate textual captions for HOI videos, we design a novel video description method based on a Mixture-of-Multimodal-Experts (MoME) strategy that not only generates expressive captions but also eliminates the hallucination by individual MLLM. Furthermore, due to the lack of an evaluation framework for generated HOI videos, we propose two new metrics to assess the quality of generated videos in a coarse-to-fine manner. Extensive experiments reveal that current T2V models struggle to generate high-quality HOI videos and confirm that our HOIGen-1M dataset is instrumental for improving HOI video generation. Project webpage is available at https://liuqi-creat.github.io/HOIGen.github.io.
OmniPrism: Learning Disentangled Visual Concept for Image Generation
Dec 16, 2024



Creative visual concept generation often draws inspiration from specific concepts in a reference image to produce relevant outcomes. However, existing methods are typically constrained to single-aspect concept generation or are easily disrupted by irrelevant concepts in multi-aspect concept scenarios, leading to concept confusion and hindering creative generation. To address this, we propose OmniPrism, a visual concept disentangling approach for creative image generation. Our method learns disentangled concept representations guided by natural language and trains a diffusion model to incorporate these concepts. We utilize the rich semantic space of a multimodal extractor to achieve concept disentanglement from given images and concept guidance. To disentangle concepts with different semantics, we construct a paired concept disentangled dataset (PCD-200K), where each pair shares the same concept such as content, style, and composition. We learn disentangled concept representations through our contrastive orthogonal disentangled (COD) training pipeline, which are then injected into additional diffusion cross-attention layers for generation. A set of block embeddings is designed to adapt each block's concept domain in the diffusion models. Extensive experiments demonstrate that our method can generate high-quality, concept-disentangled results with high fidelity to text prompts and desired concepts.