 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Gate: Mitigating Privacy Risks in LVLMs via Neuron-Level Gradient Gating
Mar 13, 2026Large Vision-Language Models (LVLMs) have shown remarkable potential across a wide array of vision-language tasks, leading to their adoption in critical domains such as finance and healthcare. However, their growing deployment also introduces significant security and privacy risks. Malicious actors could potentially exploit these models to extract sensitive information, highlighting a critical vulnerability. Recent studies show that LVLMs often fail to consistently refuse instructions designed to compromise user privacy. While existing work on privacy protection has made meaningful progress in preventing the leakage of sensitive data, they are constrained by limitations in both generalization and non-destructiveness. They often struggle to robustly handle unseen privacy-related queries and may inadvertently degrade a model's performance on standard tasks. To address these challenges, we introduce Neural Gate, a novel method for mitigating privacy risks through neuron-level model editing. Our method improves a model's privacy safeguards by increasing its rate of refusal for privacy-related questions, crucially extending this protective behavior to novel sensitive queries not encountered during the editing process. Neural Gate operates by learning a feature vector to identify neurons associated with privacy-related concepts within the model's representation of a subject. This localization then precisely guides the update of model parameters. Through comprehensive experiments on MiniGPT and LLaVA, we demonstrate that our method significantly boosts the model's privacy protection while preserving its original utility.
OSI: One-step Inversion Excels in Extracting Diffusion Watermarks
Feb 10, 2026Watermarking is an important mechanism for provenance and copyright protection of diffusion-generated images. Training-free methods, exemplified by Gaussian Shading, embed watermarks into the initial noise of diffusion models with negligible impact on the quality of generated images. However, extracting this type of watermark typically requires multi-step diffusion inversion to obtain precise initial noise, which is computationally expensive and time-consuming. To address this issue, we propose One-step Inversion (OSI), a significantly faster and more accurate method for extracting Gaussian Shading style watermarks. OSI reformulates watermark extraction as a learnable sign classification problem, which eliminates the need for precise regression of the initial noise. Then, we initialize the OSI model from the diffusion backbone and finetune it on synthesized noise-image pairs with a sign classification objective. In this manner, the OSI model is able to accomplish the watermark extraction efficiently in only one step. Our OSI substantially outperforms the multi-step diffusion inversion method: it is 20x faster, achieves higher extraction accuracy, and doubles the watermark payload capacity. Extensive experiments across diverse schedulers, diffusion backbones, and cryptographic schemes consistently show improvements, demonstrating the generality of our OSI framework.
Jodi: Unification of Visual Generation and Understanding via Joint Modeling
May 25, 2025Visual generation and understanding are two deeply interconnected aspects of human intelligence, yet they have been traditionally treated as separate tasks in machine learning. In this paper, we propose Jodi, a diffusion framework that unifies visual generation and understanding by jointly modeling the image domain and multiple label domains. Specifically, Jodi is built upon a linear diffusion transformer along with a role switch mechanism, which enables it to perform three particular types of tasks: (1) joint generation, where the model simultaneously generates images and multiple labels; (2) controllable generation, where images are generated conditioned on any combination of labels; and (3) image perception, where multiple labels can be predicted at once from a given image. Furthermore, we present the Joint-1.6M dataset, which contains 200,000 high-quality images collected from public sources, automatic labels for 7 visual domains, and LLM-generated captions. Extensive experiments demonstrate that Jodi excels in both generation and understanding tasks and exhibits strong extensibility to a wider range of visual domains. Code is available at https://github.com/VIPL-GENUN/Jodi.
Plan-R1: Safe and Feasible Trajectory Planning as Language Modeling
May 23, 2025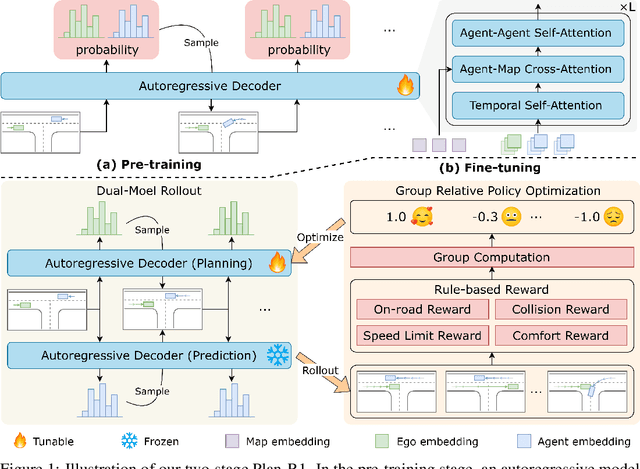
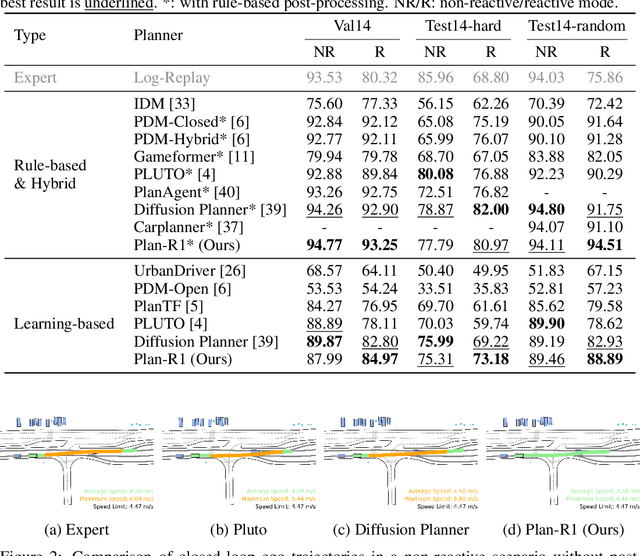
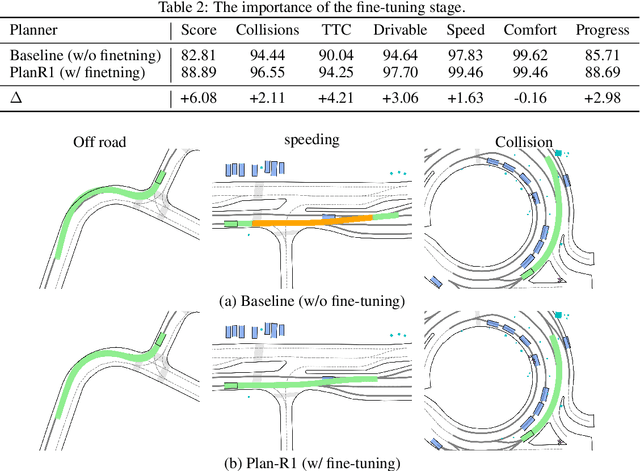
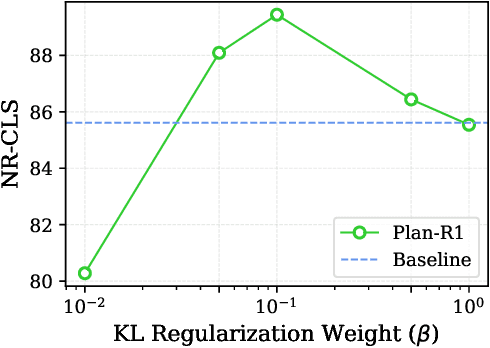
Safe and feasible trajectory planning is essential for real-world autonomous driving systems. However, existing learning-based planning methods often rely on expert demonstrations, which not only lack explicit safety awareness but also risk inheriting unsafe behaviors such as speeding from suboptimal human driving data. Inspired by the success of large language models, we propose Plan-R1, a novel two-stage trajectory planning framework that formulates trajectory planning as a sequential prediction task, guided by explicit planning principles such as safety, comfort, and traffic rule compliance. In the first stage, we train an autoregressive trajectory predictor via next motion token prediction on expert data. In the second stage, we design rule-based rewards (e.g., collision avoidance, speed limits) and fine-tune the model using Group Relative Policy Optimization (GRPO), a reinforcement learning strategy, to align its predictions with these planning principles. Experiments on the nuPlan benchmark demonstrate that our Plan-R1 significantly improves planning safety and feasibility, achieving state-of-the-art performance.
HPNet: Dynamic Trajectory Forecasting with Historical Prediction Attention
Apr 11, 2024



Predicting the trajectories of road agents is essential for autonomous driving systems. The recent mainstream methods follow a static paradigm, which predicts the future trajectory by using a fixed duration of historical frames. These methods make the predictions independently even at adjacent time steps, which leads to potential instability and temporal inconsistency. As successive time steps have largely overlapping historical frames, their forecasting should have intrinsic correlation, such as overlapping predicted trajectories should be consistent, or be different but share the same motion goal depending on the road situation. Motivated by this, in this work, we introduce HPNet, a novel dynamic trajectory forecasting method. Aiming for stable and accurate trajectory forecasting, our method leverages not only historical frames including maps and agent states, but also historical predictions. Specifically, we newly design a Historical Prediction Attention module to automatically encode the dynamic relationship between successive predictions. Besides, it also extends the attention range beyond the currently visible window benefitting from the use of historical predictions. The proposed Historical Prediction Attention together with the Agent Attention and Mode Attention is further formulated as the Triple Factorized Attention module, serving as the core design of HPNet.Experiments on the Argoverse and INTERACTION datasets show that HPNet achieves state-of-the-art performance, and generates accurate and stable future trajectories. Our code are available at https://github.com/XiaolongTang23/HPNet.
Triplet Knowledge Distillation
May 25, 2023



In Knowledge Distillation, the teacher is generally much larger than the student, making the solution of the teacher likely to be difficult for the student to learn. To ease the mimicking difficulty, we introduce a triplet knowledge distillation mechanism named TriKD. Besides teacher and student, TriKD employs a third role called anchor model. Before distillation begins, the pre-trained anchor model delimits a subspace within the full solution space of the target problem. Solutions within the subspace are expected to be easy targets that the student could mimic well. Distillation then begins in an online manner, and the teacher is only allowed to express solutions within the aforementioned subspace. Surprisingly, benefiting from accurate but easy-to-mimic hints, the student can finally perform well. After the student is well trained, it can be used as the new anchor for new students, forming a curriculum learning strategy. Our experiments on image classification and face recognition with various models clearly demonstrate the effectiveness of our method. Furthermore, the proposed TriKD is also effective in dealing with the overfitting issue. Moreover, our theoretical analysis supports the rationality of our triplet distillation.
Function-Consistent Feature Distillation
Apr 24, 2023



Feature distillation makes the student mimic the intermediate features of the teacher. Nearly all existing feature-distillation methods use L2 distance or its slight variants as the distance metric between teacher and student features. However, while L2 distance is isotropic w.r.t. all dimensions, the neural network's operation on different dimensions is usually anisotropic, i.e., perturbations with the same 2-norm but in different dimensions of intermediate features lead to changes in the final output with largely different magnitude. Considering this, we argue that the similarity between teacher and student features should not be measured merely based on their appearance (i.e., L2 distance), but should, more importantly, be measured by their difference in function, namely how later layers of the network will read, decode, and process them. Therefore, we propose Function-Consistent Feature Distillation (FCFD), which explicitly optimizes the functional similarity between teacher and student features. The core idea of FCFD is to make teacher and student features not only numerically similar, but more importantly produce similar outputs when fed to the later part of the same network. With FCFD, the student mimics the teacher more faithfully and learns more from the teacher. Extensive experiments on image classification and object detection demonstrate the superiority of FCFD to existing methods. Furthermore, we can combine FCFD with many existing methods to obtain even higher accuracy. Our codes are available at https://github.com/LiuDongyang6/FCFD.
EigenGAN: Layer-Wise Eigen-Learning for GANs
Apr 26, 2021

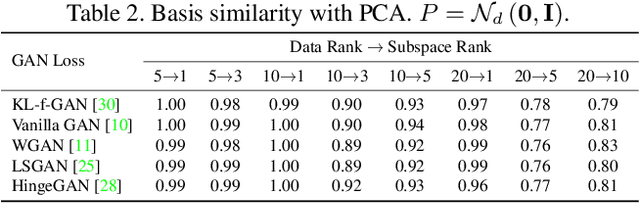

Recent studies on Generative Adversarial Network (GAN) reveal that different layers of a generative CNN hold different semantics of the synthesized images. However, few GAN models have explicit dimensions to control the semantic attributes represented in a specific layer. This paper proposes EigenGAN which is able to unsupervisedly mine interpretable and controllable dimensions from different generator layers. Specifically, EigenGAN embeds one linear subspace with orthogonal basis into each generator layer. Via the adversarial training to learn a target distribution, these layer-wise subspaces automatically discover a set of "eigen-dimensions" at each layer corresponding to a set of semantic attributes or interpretable variations. By traversing the coefficient of a specific eigen-dimension, the generator can produce samples with continuous changes corresponding to a specific semantic attribute. Taking the human face for example, EigenGAN can discover controllable dimensions for high-level concepts such as pose and gender in the subspace of deep layers, as well as low-level concepts such as hue and color in the subspace of shallow layers. Moreover, under the linear circumstance, we theoretically prove that our algorithm derives the principal components as PCA does. Codes can be found in https://github.com/LynnHo/EigenGAN-Tensorflow.
PA-GAN: Progressive Attention Generative Adversarial Network for Facial Attribute Editing
Jul 12, 2020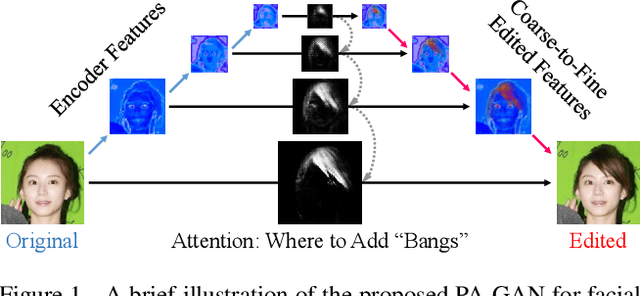
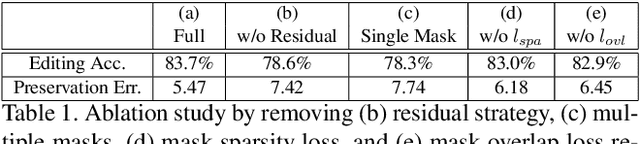

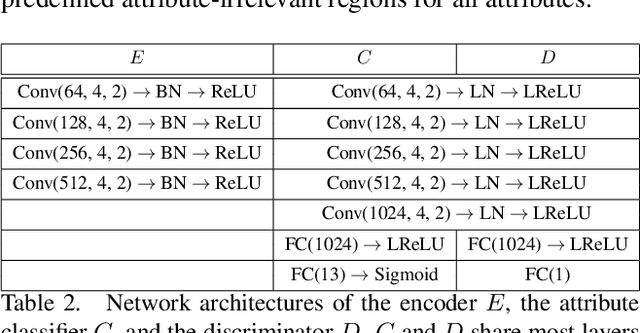
Facial attribute editing aims to manipulate attributes on the human face, e.g., adding a mustache or changing the hair color. Existing approaches suffer from a serious compromise between correct attribute generation and preservation of the other information such as identity and background, because they edit the attributes in the imprecise area. To resolve this dilemma, we propose a progressive attention GAN (PA-GAN) for facial attribute editing. In our approach, the editing is progressively conducted from high to low feature level while being constrained inside a proper attribute area by an attention mask at each level. This manner prevents undesired modifications to the irrelevant regions from the beginning, and then the network can focus more on correctly generating the attributes within a proper boundary at each level. As a result, our approach achieves correct attribute editing with irrelevant details much better preserved compared with the state-of-the-arts. Codes are released at https://github.com/LynnHo/PA-GAN-Tensorflow.
Self-supervised Equivariant Attention Mechanism for Weakly Supervised Semantic Segmentation
Apr 09, 2020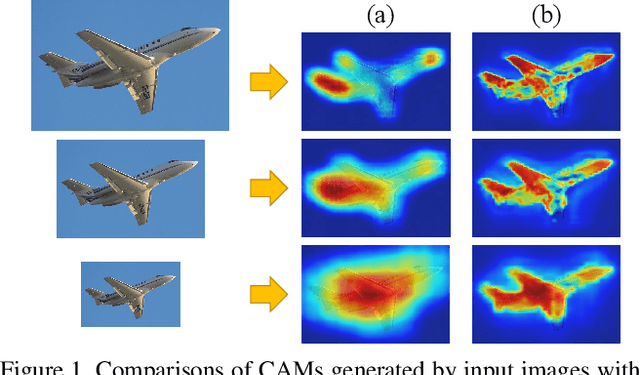
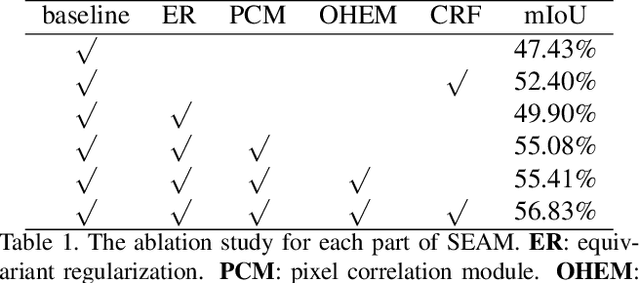
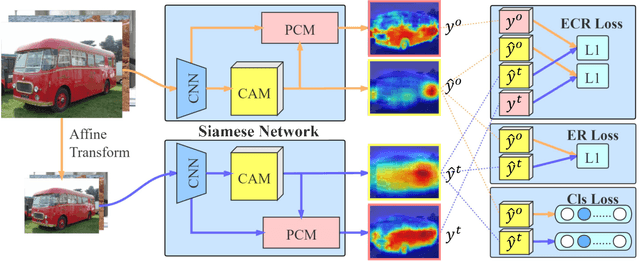

Image-level weakly supervised semantic segmentation is a challenging problem that has been deeply studied in recent years. Most of advanced solutions exploit class activation map (CAM). However, CAMs can hardly serve as the object mask due to the gap between full and weak supervisions. In this paper, we propose a self-supervised equivariant attention mechanism (SEAM) to discover additional supervision and narrow the gap. Our method is based on the observation that equivariance is an implicit constraint in fully supervised semantic segmentation, whose pixel-level labels take the same spatial transformation as the input images during data augmentation. However, this constraint is lost on the CAMs trained by image-level supervision. Therefore, we propose consistency regularization on predicted CAMs from various transformed images to provide self-supervision for network learning. Moreover, we propose a pixel correlation module (PCM), which exploits context appearance information and refines the prediction of current pixel by its similar neighbors, leading to further improvement on CAMs consistency. Extensive experiments on PASCAL VOC 2012 dataset demonstrate our method outperforms state-of-the-art methods using the same level of supervision. The code is released online.