 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSS4D: Native 4D Generative Model via Structured Spacetime Latents
Dec 16, 2025



We present SS4D, a native 4D generative model that synthesizes dynamic 3D objects directly from monocular video. Unlike prior approaches that construct 4D representations by optimizing over 3D or video generative models, we train a generator directly on 4D data, achieving high fidelity, temporal coherence, and structural consistency. At the core of our method is a compressed set of structured spacetime latents. Specifically, (1) To address the scarcity of 4D training data, we build on a pre-trained single-image-to-3D model, preserving strong spatial consistency. (2) Temporal consistency is enforced by introducing dedicated temporal layers that reason across frames. (3) To support efficient training and inference over long video sequences, we compress the latent sequence along the temporal axis using factorized 4D convolutions and temporal downsampling blocks. In addition, we employ a carefully designed training strategy to enhance robustness against occlusion
* ToG(Siggraph Asia 2025)
V-RGBX: Video Editing with Accurate Controls over Intrinsic Properties
Dec 12, 2025



Large-scale video generation models have shown remarkable potential in modeling photorealistic appearance and lighting interactions in real-world scenes. However, a closed-loop framework that jointly understands intrinsic scene properties (e.g., albedo, normal, material, and irradiance), leverages them for video synthesis, and supports editable intrinsic representations remains unexplored. We present V-RGBX, the first end-to-end framework for intrinsic-aware video editing. V-RGBX unifies three key capabilities: (1) video inverse rendering into intrinsic channels, (2) photorealistic video synthesis from these intrinsic representations, and (3) keyframe-based video editing conditioned on intrinsic channels. At the core of V-RGBX is an interleaved conditioning mechanism that enables intuitive, physically grounded video editing through user-selected keyframes, supporting flexible manipulation of any intrinsic modality. Extensive qualitative and quantitative results show that V-RGBX produces temporally consistent, photorealistic videos while propagating keyframe edits across sequences in a physically plausible manner. We demonstrate its effectiveness in diverse applications, including object appearance editing and scene-level relighting, surpassing the performance of prior methods.
FlexiCup: Wireless Multimodal Suction Cup with Dual-Zone Vision-Tactile Sensing
Nov 18, 2025



Conventional suction cups lack sensing capabilities for contact-aware manipulation in unstructured environments. This paper presents FlexiCup, a fully wireless multimodal suction cup that integrates dual-zone vision-tactile sensing. The central zone dynamically switches between vision and tactile modalities via illumination control for contact detection, while the peripheral zone provides continuous spatial awareness for approach planning. FlexiCup supports both vacuum and Bernoulli suction modes through modular mechanical configurations, achieving complete wireless autonomy with onboard computation and power. We validate hardware versatility through dual control paradigms. Modular perception-driven grasping across structured surfaces with varying obstacle densities demonstrates comparable performance between vacuum (90.0% mean success) and Bernoulli (86.7% mean success) modes. Diffusion-based end-to-end learning achieves 73.3% success on inclined transport and 66.7% on orange extraction tasks. Ablation studies confirm that multi-head attention coordinating dual-zone observations provides 13% improvements for contact-aware manipulation. Hardware designs and firmware are available at https://anonymous.4open.science/api/repo/FlexiCup-DA7D/file/index.html?v=8f531b44.
Mixture-of-Channels: Exploiting Sparse FFNs for Efficient LLMs Pre-Training and Inference
Nov 12, 2025Large language models (LLMs) have demonstrated remarkable success across diverse artificial intelligence tasks, driven by scaling laws that correlate model size and training data with performance improvements. However, this scaling paradigm incurs substantial memory overhead, creating significant challenges for both training and inference. While existing research has primarily addressed parameter and optimizer state memory reduction, activation memory-particularly from feed-forward networks (FFNs)-has become the critical bottleneck, especially when FlashAttention is implemented. In this work, we conduct a detailed memory profiling of LLMs and identify FFN activations as the predominant source to activation memory overhead. Motivated by this, we introduce Mixture-of-Channels (MoC), a novel FFN architecture that selectively activates only the Top-K most relevant channels per token determined by SwiGLU's native gating mechanism. MoC substantially reduces activation memory during pre-training and improves inference efficiency by reducing memory access through partial weight loading into GPU SRAM. Extensive experiments validate that MoC delivers significant memory savings and throughput gains while maintaining competitive model performance.
PreResQ-R1: Towards Fine-Grained Rank-and-Score Reinforcement Learning for Visual Quality Assessment via Preference-Response Disentangled Policy Optimization
Nov 07, 2025Visual Quality Assessment (QA) seeks to predict human perceptual judgments of visual fidelity. While recent multimodal large language models (MLLMs) show promise in reasoning about image and video quality, existing approaches mainly rely on supervised fine-tuning or rank-only objectives, resulting in shallow reasoning, poor score calibration, and limited cross-domain generalization. We propose PreResQ-R1, a Preference-Response Disentangled Reinforcement Learning framework that unifies absolute score regression and relative ranking consistency within a single reasoning-driven optimization scheme. Unlike prior QA methods, PreResQ-R1 introduces a dual-branch reward formulation that separately models intra-sample response coherence and inter-sample preference alignment, optimized via Group Relative Policy Optimization (GRPO). This design encourages fine-grained, stable, and interpretable chain-of-thought reasoning about perceptual quality. To extend beyond static imagery, we further design a global-temporal and local-spatial data flow strategy for Video Quality Assessment. Remarkably, with reinforcement fine-tuning on only 6K images and 28K videos, PreResQ-R1 achieves state-of-the-art results across 10 IQA and 5 VQA benchmarks under both SRCC and PLCC metrics, surpassing by margins of 5.30% and textbf2.15% in IQA task, respectively. Beyond quantitative gains, it produces human-aligned reasoning traces that reveal the perceptual cues underlying quality judgments. Code and model are available.
Towards a Golden Classifier-Free Guidance Path via Foresight Fixed Point Iterations
Oct 24, 2025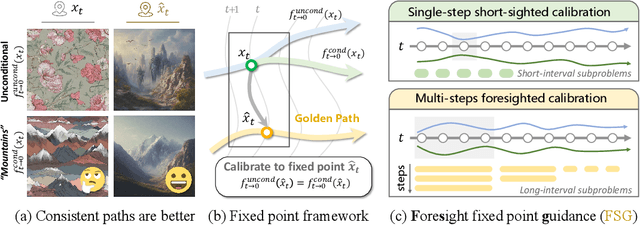

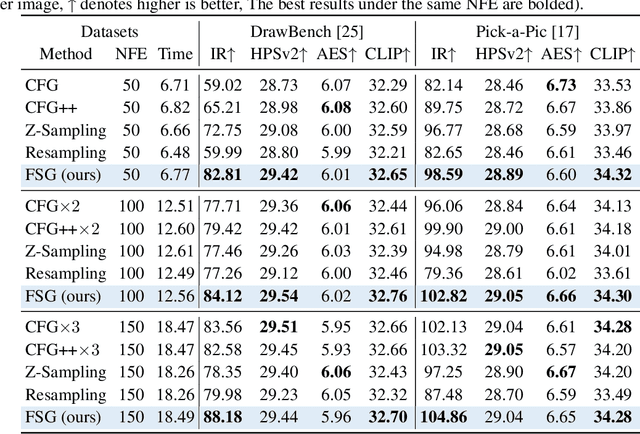
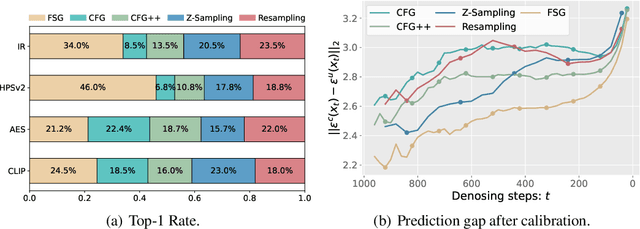
Classifier-Free Guidance (CFG) is an essential component of text-to-image diffusion models, and understanding and advancing its operational mechanisms remains a central focus of research. Existing approaches stem from divergent theoretical interpretations, thereby limiting the design space and obscuring key design choices. To address this, we propose a unified perspective that reframes conditional guidance as fixed point iterations, seeking to identify a golden path where latents produce consistent outputs under both conditional and unconditional generation. We demonstrate that CFG and its variants constitute a special case of single-step short-interval iteration, which is theoretically proven to exhibit inefficiency. To this end, we introduce Foresight Guidance (FSG), which prioritizes solving longer-interval subproblems in early diffusion stages with increased iterations. Extensive experiments across diverse datasets and model architectures validate the superiority of FSG over state-of-the-art methods in both image quality and computational efficiency. Our work offers novel perspectives for conditional guidance and unlocks the potential of adaptive design.
Universal Graph Learning for Power System Reconfigurations: Transfer Across Topology Variations
Sep 10, 2025This work addresses a fundamental challenge in applying deep learning to power systems: developing neural network models that transfer across significant system changes, including networks with entirely different topologies and dimensionalities, without requiring training data from unseen reconfigurations. Despite extensive research, most ML-based approaches remain system-specific, limiting real-world deployment. This limitation stems from a dual barrier. First, topology changes shift feature distributions and alter input dimensions due to power flow physics. Second, reconfigurations redefine output semantics and dimensionality, requiring models to handle configuration-specific outputs while maintaining transferable feature extraction. To overcome this challenge, we introduce a Universal Graph Convolutional Network (UGCN) that achieves transferability to any reconfiguration or variation of existing power systems without any prior knowledge of new grid topologies or retraining during implementation. Our approach applies to both transmission and distribution networks and demonstrates generalization capability to completely unseen system reconfigurations, such as network restructuring and major grid expansions. Experimental results across power system applications, including false data injection detection and state forecasting, show that UGCN significantly outperforms state-of-the-art methods in cross-system zero-shot transferability of new reconfigurations.
EGTM: Event-guided Efficient Turbulence Mitigation
Sep 04, 2025Turbulence mitigation (TM) aims to remove the stochastic distortions and blurs introduced by atmospheric turbulence into frame cameras. Existing state-of-the-art deep-learning TM methods extract turbulence cues from multiple degraded frames to find the so-called "lucky'', not distorted patch, for "lucky fusion''. However, it requires high-capacity network to learn from coarse-grained turbulence dynamics between synchronous frames with limited frame-rate, thus fall short in computational and storage efficiency. Event cameras, with microsecond-level temporal resolution, have the potential to fundamentally address this bottleneck with efficient sparse and asynchronous imaging mechanism. In light of this, we (i) present the fundamental \textbf{``event-lucky insight''} to reveal the correlation between turbulence distortions and inverse spatiotemporal distribution of event streams. Then, build upon this insight, we (ii) propose a novel EGTM framework that extracts pixel-level reliable turbulence-free guidance from the explicit but noisy turbulent events for temporal lucky fusion. Moreover, we (iii) build the first turbulence data acquisition system to contribute the first real-world event-driven TM dataset. Extensive experimental results demonstrate that our approach significantly surpass the existing SOTA TM method by 710 times, 214 times and 224 times in model size, inference latency and model complexity respectively, while achieving the state-of-the-art in restoration quality (+0.94 PSNR and +0.08 SSIM) on our real-world EGTM dataset. This demonstrating the great efficiency merit of introducing event modality into TM task. Demo code and data have been uploaded in supplementary material and will be released once accepted.
DiCache: Let Diffusion Model Determine Its Own Cache
Aug 24, 2025



Recent years have witnessed the rapid development of acceleration techniques for diffusion models, especially caching-based acceleration methods. These studies seek to answer two fundamental questions: "When to cache" and "How to use cache", typically relying on predefined empirical laws or dataset-level priors to determine the timing of caching and utilizing handcrafted rules for leveraging multi-step caches. However, given the highly dynamic nature of the diffusion process, they often exhibit limited generalizability and fail on outlier samples. In this paper, a strong correlation is revealed between the variation patterns of the shallow-layer feature differences in the diffusion model and those of final model outputs. Moreover, we have observed that the features from different model layers form similar trajectories. Based on these observations, we present DiCache, a novel training-free adaptive caching strategy for accelerating diffusion models at runtime, answering both when and how to cache within a unified framework. Specifically, DiCache is composed of two principal components: (1) Online Probe Profiling Scheme leverages a shallow-layer online probe to obtain a stable prior for the caching error in real time, enabling the model to autonomously determine caching schedules. (2) Dynamic Cache Trajectory Alignment combines multi-step caches based on shallow-layer probe feature trajectory to better approximate the current feature, facilitating higher visual quality. Extensive experiments validate DiCache's capability in achieving higher efficiency and improved visual fidelity over state-of-the-art methods on various leading diffusion models including WAN 2.1, HunyuanVideo for video generation, and Flux for image generation.
Hi3DEval: Advancing 3D Generation Evaluation with Hierarchical Validity
Aug 07, 2025



Despite rapid advances in 3D content generation, quality assessment for the generated 3D assets remains challenging. Existing methods mainly rely on image-based metrics and operate solely at the object level, limiting their ability to capture spatial coherence, material authenticity, and high-fidelity local details. 1) To address these challenges, we introduce Hi3DEval, a hierarchical evaluation framework tailored for 3D generative content. It combines both object-level and part-level evaluation, enabling holistic assessments across multiple dimensions as well as fine-grained quality analysis. Additionally, we extend texture evaluation beyond aesthetic appearance by explicitly assessing material realism, focusing on attributes such as albedo, saturation, and metallicness. 2) To support this framework, we construct Hi3DBench, a large-scale dataset comprising diverse 3D assets and high-quality annotations, accompanied by a reliable multi-agent annotation pipeline. We further propose a 3D-aware automated scoring system based on hybrid 3D representations. Specifically, we leverage video-based representations for object-level and material-subject evaluations to enhance modeling of spatio-temporal consistency and employ pretrained 3D features for part-level perception. Extensive experiments demonstrate that our approach outperforms existing image-based metrics in modeling 3D characteristics and achieves superior alignment with human preference, providing a scalable alternative to manual evaluations. The project page is available at https://zyh482.github.io/Hi3DEval/.