 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstablishing dermatopathology encyclopedia DermpathNet with Artificial Intelligence-Based Workflow
Jan 27, 2026Accessing high-quality, open-access dermatopathology image datasets for learning and cross-referencing is a common challenge for clinicians and dermatopathology trainees. To establish a comprehensive open-access dermatopathology dataset for educational, cross-referencing, and machine-learning purposes, we employed a hybrid workflow to curate and categorize images from the PubMed Central (PMC) repository. We used specific keywords to extract relevant images, and classified them using a novel hybrid method that combined deep learning-based image modality classification with figure caption analyses. Validation on 651 manually annotated images demonstrated the robustness of our workflow, with an F-score of 89.6\% for the deep learning approach, 61.0\% for the keyword-based retrieval method, and 90.4\% for the hybrid approach. We retrieved over 7,772 images across 166 diagnoses and released this fully annotated dataset, reviewed by board-certified dermatopathologists. Using our dataset as a challenging task, we found the current image analysis algorithm from OpenAI inadequate for analyzing dermatopathology images. In conclusion, we have developed a large, peer-reviewed, open-access dermatopathology image dataset, DermpathNet, which features a semi-automated curation workflow.
Youtu-Agent: Scaling Agent Productivity with Automated Generation and Hybrid Policy Optimization
Dec 31, 2025Existing Large Language Model (LLM) agent frameworks face two significant challenges: high configuration costs and static capabilities. Building a high-quality agent often requires extensive manual effort in tool integration and prompt engineering, while deployed agents struggle to adapt to dynamic environments without expensive fine-tuning. To address these issues, we propose \textbf{Youtu-Agent}, a modular framework designed for the automated generation and continuous evolution of LLM agents. Youtu-Agent features a structured configuration system that decouples execution environments, toolkits, and context management, enabling flexible reuse and automated synthesis. We introduce two generation paradigms: a \textbf{Workflow} mode for standard tasks and a \textbf{Meta-Agent} mode for complex, non-standard requirements, capable of automatically generating tool code, prompts, and configurations. Furthermore, Youtu-Agent establishes a hybrid policy optimization system: (1) an \textbf{Agent Practice} module that enables agents to accumulate experience and improve performance through in-context optimization without parameter updates; and (2) an \textbf{Agent RL} module that integrates with distributed training frameworks to enable scalable and stable reinforcement learning of any Youtu-Agents in an end-to-end, large-scale manner. Experiments demonstrate that Youtu-Agent achieves state-of-the-art performance on WebWalkerQA (71.47\%) and GAIA (72.8\%) using open-weight models. Our automated generation pipeline achieves over 81\% tool synthesis success rate, while the Practice module improves performance on AIME 2024/2025 by +2.7\% and +5.4\% respectively. Moreover, our Agent RL training achieves 40\% speedup with steady performance improvement on 7B LLMs, enhancing coding/reasoning and searching capabilities respectively up to 35\% and 21\% on Maths and general/multi-hop QA benchmarks.
SmartSnap: Proactive Evidence Seeking for Self-Verifying Agents
Dec 26, 2025Agentic reinforcement learning (RL) holds great promise for the development of autonomous agents under complex GUI tasks, but its scalability remains severely hampered by the verification of task completion. Existing task verification is treated as a passive, post-hoc process: a verifier (i.e., rule-based scoring script, reward or critic model, and LLM-as-a-Judge) analyzes the agent's entire interaction trajectory to determine if the agent succeeds. Such processing of verbose context that contains irrelevant, noisy history poses challenges to the verification protocols and therefore leads to prohibitive cost and low reliability. To overcome this bottleneck, we propose SmartSnap, a paradigm shift from this passive, post-hoc verification to proactive, in-situ self-verification by the agent itself. We introduce the Self-Verifying Agent, a new type of agent designed with dual missions: to not only complete a task but also to prove its accomplishment with curated snapshot evidences. Guided by our proposed 3C Principles (Completeness, Conciseness, and Creativity), the agent leverages its accessibility to the online environment to perform self-verification on a minimal, decisive set of snapshots. Such evidences are provided as the sole materials for a general LLM-as-a-Judge verifier to determine their validity and relevance. Experiments on mobile tasks across model families and scales demonstrate that our SmartSnap paradigm allows training LLM-driven agents in a scalable manner, bringing performance gains up to 26.08% and 16.66% respectively to 8B and 30B models. The synergizing between solution finding and evidence seeking facilitates the cultivation of efficient, self-verifying agents with competitive performance against DeepSeek V3.1 and Qwen3-235B-A22B.
CKM-Enabled Joint Spatial-Doppler Domain Clutter Suppression for Low-Altitude UAV ISAC
Dec 10, 2025The rapid development of low-altitude economy has placed higher demands on the sensing of small-sized unmanned aerial vehicle (UAV) targets. However, the complex and dynamic low-altitude environment, like the urban and mountainous areas, makes clutter a significant factor affecting the sensing performance. Traditional clutter suppression methods based on Doppler difference or signal strength are inadequate for scenarios with dynamic clutter and slow-moving targets like low-altitude UAVs. In this paper, motivated by the concept of channel knowledge map (CKM), we propose a novel clutter suppression technique for orthogonal frequency division multiplexing (OFDM) integrated sensing and communication (ISAC) system, by leveraging a new type of CKM named clutter angle map (CLAM). CLAM is a site-specific database, containing location-specific primary clutter angles for the coverage area of the ISAC base station (BS). With CLAM, the sensing signal components corresponding to the clutter environment can be effectively removed before target detection and parameter estimation, which greatly enhances the sensing performance. Besides, to take into account the scenarios when the targets and clutters are in close directions so that pure CLAM-based spatial domain clutter suppression is no longer effective, we further propose a two-step CLAM-enabled joint spatial-Doppler domain clutter suppression algorithm. Simulation results demonstrate that the proposed technique effectively suppresses clutter and enhances target sensing performance, achieving accurate parameter estimation for sensing slow-moving low-altitude UAV targets.
Learn the Ropes, Then Trust the Wins: Self-imitation with Progressive Exploration for Agentic Reinforcement Learning
Sep 26, 2025
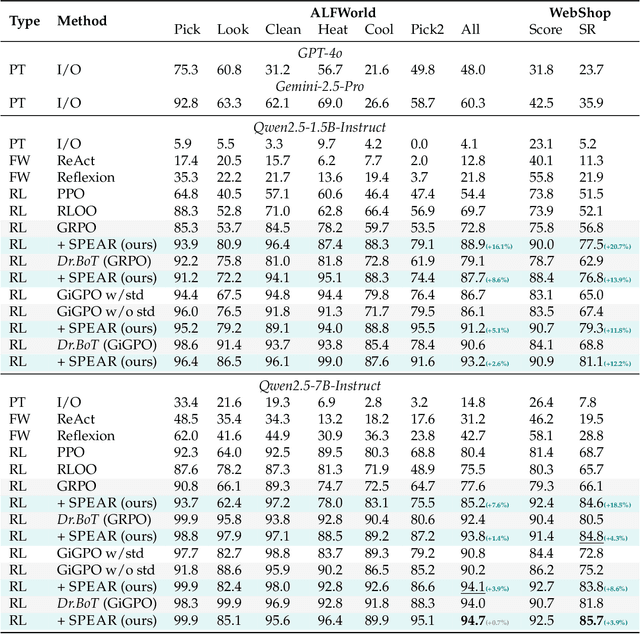
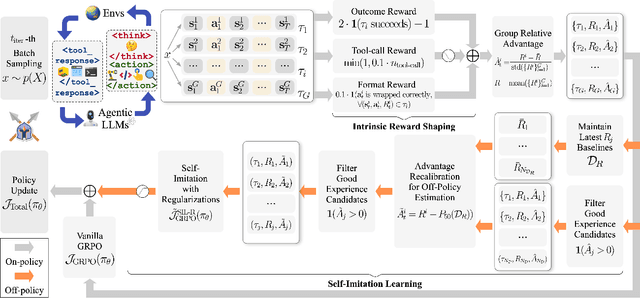
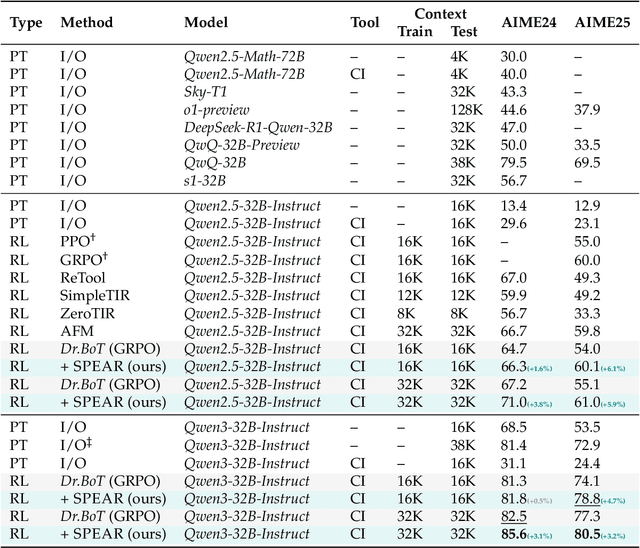
Reinforcement learning (RL) is the dominant paradigm for sharpening strategic tool use capabilities of LLMs on long-horizon, sparsely-rewarded agent tasks, yet it faces a fundamental challenge of exploration-exploitation trade-off. Existing studies stimulate exploration through the lens of policy entropy, but such mechanical entropy maximization is prone to RL training instability due to the multi-turn distribution shifting. In this paper, we target the progressive exploration-exploitation balance under the guidance of the agent own experiences without succumbing to either entropy collapsing or runaway divergence. We propose SPEAR, a curriculum-based self-imitation learning (SIL) recipe for training agentic LLMs. It extends the vanilla SIL framework, where a replay buffer stores self-generated promising trajectories for off-policy update, by gradually steering the policy evolution within a well-balanced range of entropy across stages. Specifically, our approach incorporates a curriculum to manage the exploration process, utilizing intrinsic rewards to foster skill-level exploration and facilitating action-level exploration through SIL. At first, the auxiliary tool call reward plays a critical role in the accumulation of tool-use skills, enabling broad exposure to the unfamiliar distributions of the environment feedback with an upward entropy trend. As training progresses, self-imitation gets strengthened to exploit existing successful patterns from replayed experiences for comparative action-level exploration, accelerating solution iteration without unbounded entropy growth. To further stabilize training, we recalibrate the advantages of experiences in the replay buffer to address the potential policy drift. Reugularizations such as the clipping of tokens with high covariance between probability and advantage are introduced to the trajectory-level entropy control to curb over-confidence.
Extracting Post-Acute Sequelae of SARS-CoV-2 Infection Symptoms from Clinical Notes via Hybrid Natural Language Processing
Aug 17, 2025Accurately and efficiently diagnosing Post-Acute Sequelae of COVID-19 (PASC) remains challenging due to its myriad symptoms that evolve over long- and variable-time intervals. To address this issue, we developed a hybrid natural language processing pipeline that integrates rule-based named entity recognition with BERT-based assertion detection modules for PASC-symptom extraction and assertion detection from clinical notes. We developed a comprehensive PASC lexicon with clinical specialists. From 11 health systems of the RECOVER initiative network across the U.S., we curated 160 intake progress notes for model development and evaluation, and collected 47,654 progress notes for a population-level prevalence study. We achieved an average F1 score of 0.82 in one-site internal validation and 0.76 in 10-site external validation for assertion detection. Our pipeline processed each note at $2.448\pm 0.812$ seconds on average. Spearman correlation tests showed $\rho >0.83$ for positive mentions and $\rho >0.72$ for negative ones, both with $P <0.0001$. These demonstrate the effectiveness and efficiency of our models and their potential for improving PASC diagnosis.
A Multi-Stage Large Language Model Framework for Extracting Suicide-Related Social Determinants of Health
Aug 07, 2025Background: Understanding social determinants of health (SDoH) factors contributing to suicide incidents is crucial for early intervention and prevention. However, data-driven approaches to this goal face challenges such as long-tailed factor distributions, analyzing pivotal stressors preceding suicide incidents, and limited model explainability. Methods: We present a multi-stage large language model framework to enhance SDoH factor extraction from unstructured text. Our approach was compared to other state-of-the-art language models (i.e., pre-trained BioBERT and GPT-3.5-turbo) and reasoning models (i.e., DeepSeek-R1). We also evaluated how the model's explanations help people annotate SDoH factors more quickly and accurately. The analysis included both automated comparisons and a pilot user study. Results: We show that our proposed framework demonstrated performance boosts in the overarching task of extracting SDoH factors and in the finer-grained tasks of retrieving relevant context. Additionally, we show that fine-tuning a smaller, task-specific model achieves comparable or better performance with reduced inference costs. The multi-stage design not only enhances extraction but also provides intermediate explanations, improving model explainability. Conclusions: Our approach improves both the accuracy and transparency of extracting suicide-related SDoH from unstructured texts. These advancements have the potential to support early identification of individuals at risk and inform more effective prevention strategies.
Realizing Text-Driven Motion Generation on NAO Robot: A Reinforcement Learning-Optimized Control Pipeline
Jun 05, 2025



Human motion retargeting for humanoid robots, transferring human motion data to robots for imitation, presents significant challenges but offers considerable potential for real-world applications. Traditionally, this process relies on human demonstrations captured through pose estimation or motion capture systems. In this paper, we explore a text-driven approach to mapping human motion to humanoids. To address the inherent discrepancies between the generated motion representations and the kinematic constraints of humanoid robots, we propose an angle signal network based on norm-position and rotation loss (NPR Loss). It generates joint angles, which serve as inputs to a reinforcement learning-based whole-body joint motion control policy. The policy ensures tracking of the generated motions while maintaining the robot's stability during execution. Our experimental results demonstrate the efficacy of this approach, successfully transferring text-driven human motion to a real humanoid robot NAO.
Natural Language Processing in Support of Evidence-based Medicine: A Scoping Review
May 28, 2025


Evidence-based medicine (EBM) is at the forefront of modern healthcare, emphasizing the use of the best available scientific evidence to guide clinical decisions. Due to the sheer volume and rapid growth of medical literature and the high cost of curation, there is a critical need to investigate Natural Language Processing (NLP) methods to identify, appraise, synthesize, summarize, and disseminate evidence in EBM. This survey presents an in-depth review of 129 research studies on leveraging NLP for EBM, illustrating its pivotal role in enhancing clinical decision-making processes. The paper systematically explores how NLP supports the five fundamental steps of EBM -- Ask, Acquire, Appraise, Apply, and Assess. The review not only identifies current limitations within the field but also proposes directions for future research, emphasizing the potential for NLP to revolutionize EBM by refining evidence extraction, evidence synthesis, appraisal, summarization, enhancing data comprehensibility, and facilitating a more efficient clinical workflow.
FlowAgent: Achieving Compliance and Flexibility for Workflow Agents
Feb 20, 2025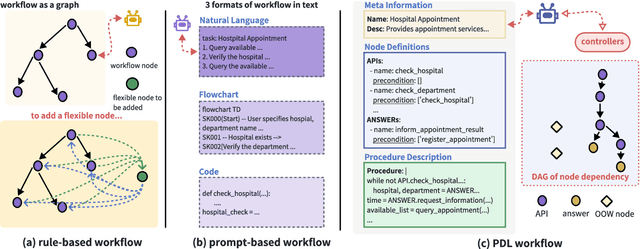

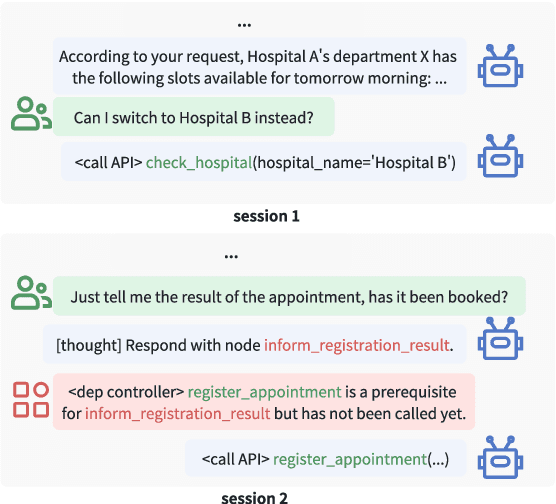
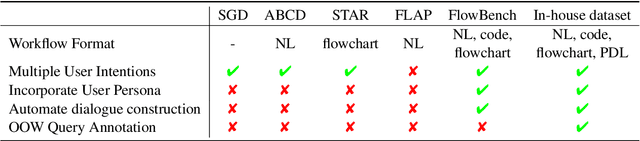
The integration of workflows with large language models (LLMs) enables LLM-based agents to execute predefined procedures, enhancing automation in real-world applications. Traditional rule-based methods tend to limit the inherent flexibility of LLMs, as their predefined execution paths restrict the models' action space, particularly when the unexpected, out-of-workflow (OOW) queries are encountered. Conversely, prompt-based methods allow LLMs to fully control the flow, which can lead to diminished enforcement of procedural compliance. To address these challenges, we introduce FlowAgent, a novel agent framework designed to maintain both compliance and flexibility. We propose the Procedure Description Language (PDL), which combines the adaptability of natural language with the precision of code to formulate workflows. Building on PDL, we develop a comprehensive framework that empowers LLMs to manage OOW queries effectively, while keeping the execution path under the supervision of a set of controllers. Additionally, we present a new evaluation methodology to rigorously assess an LLM agent's ability to handle OOW scenarios, going beyond routine flow compliance tested in existing benchmarks. Experiments on three datasets demonstrate that FlowAgent not only adheres to workflows but also effectively manages OOW queries, highlighting its dual strengths in compliance and flexibility. The code is available at https://github.com/Lightblues/FlowAgent.