 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJailbreak susceptibility prediction and mitigation via the behavioral geometry of models
May 26, 2026Evaluating and mitigating a generative system's susceptibility to jailbreak attacks is critical to its safe deployment. Given the number of deployable systems, full per-configuration evaluation and optimization is impractical. In this paper, we formalize the behavioral geometry of a population of models that, by leveraging previously evaluated and defended models, supports both efficient susceptibility prediction and effective defense transfer across a population. We apply the framework to 79 models spanning 24 providers and to 100 system configurations of a single base model. Simple methods that use the behavioral geometry reach an AUPRC of $0.94$ for susceptibility detection with $\approx98\%$ fewer probes relative to a full evaluation. Using the behavioral geometry to select which model to transfer an optimized defense from outperforms same-provider assignment ($+2\%$, $p = 0.03$) at no additional probe cost, with a set of three models sufficient to cover the population. Results are robust to hyperparameter selection and judge.
Cubit: Token Mixer with Kernel Ridge Regression
May 07, 2026Since its introduction in 2017, the Transformer has become one of the most widely adopted architectures in modern deep learning. Despite extensive efforts to improve positional encoding, attention mechanisms, and feed-forward networks, the core token-mixing mechanism in Transformers remains attention. In this work, we show that the attention module in Transformers can be interpreted as performing Nadaraya-Watson regression, where it computes similarities between tokens and aggregates the corresponding values accordingly. Motivated by this perspective, we propose Cubit, a potential next-generation architecture that leverages Kernel Ridge Regression (KRR), while the vanilla Transformer relies on Nadaraya-Watson regression. Specifically, Cubit modifies the classical attention computation by incorporating the closed-form solution of KRR, combining value aggregation through kernel similarities with normalization via the inverse of the kernel matrix. To improve the training stability, we further propose the Limited-Range Rescale (LRR), which rescales the value layer within a controlled range. We argue that Cubit, as a KRR-based architecture, provides a stronger mathematical foundation than the vanilla Transformer, whose attention mechanism corresponds to Nadaraya-Watson regression. We validate this claim through comprehensive experiments. The experimental results suggest that Cubit may exhibit stronger long-sequence modeling capability. In particular, its performance gain over the Transformer appears to increase as the training sequence length grows.
Does a Global Perspective Help Prune Sparse MoEs Elegantly?
Apr 08, 2026Empirical scaling laws for language models have encouraged the development of ever-larger LLMs, despite their growing computational and memory costs. Sparse Mixture-of-Experts (MoEs) offer a promising alternative by activating only a subset of experts per forward pass, improving efficiency without sacrificing performance. However, the large number of expert parameters still leads to substantial memory consumption. Existing pruning methods typically allocate budgets uniformly across layers, overlooking the heterogeneous redundancy that arises in sparse MoEs. We propose GRAPE (Global Redundancy-Aware Pruning of Experts, a global pruning strategy that dynamically allocates pruning budgets based on cross-layer redundancy. Experiments on Mixtral-8x7B, Mixtral-8x22B, DeepSeek-MoE, Qwen-MoE, and GPT-OSS show that, under the same pruning budget, GRAPE consistently achieves the best average performance. On the three main models reported in the paper, it improves average accuracy over the strongest local baseline by 1.40% on average across pruning settings, with gains of up to 2.45%.
Training Large Reasoning Models Efficiently via Progressive Thought Encoding
Feb 18, 2026Large reasoning models (LRMs) excel on complex problems but face a critical barrier to efficiency: reinforcement learning (RL) training requires long rollouts for outcome-based rewards, where autoregressive decoding dominates time and memory usage. While sliding-window cache strategies can bound memory, they disrupt long-context reasoning and degrade performance. We introduce Progressive Thought Encoding, a parameter-efficient fine-tuning method that enables LRMs to reason effectively under fixed-size caches. By progressively encoding intermediate reasoning into fixed-size vector representations, our approach eliminates the need to backpropagate through full-cache rollouts, thereby reducing memory usage, while maintaining constant memory during inference. Experiments on three models, including Qwen2.5-3B-Instruct, Qwen2.5-7B-Instruct, and DeepSeek-R1-Distill-Llama-8B, on six widely used challenging mathematical benchmarks show consistent gains: our method achieves +19.3% improvement over LoRA-based fine-tuning and +29.9% over LRMs without fine-tuning on average, with up to +23.4 accuracy improvement on AIME2024/2025 under the same tight cache budgets. These results demonstrate that Progressive Thought Encoding not only improves reasoning accuracy but also makes RL training of LRMs substantially more efficient and scalable under real-world memory constraints.
SEMA: Simple yet Effective Learning for Multi-Turn Jailbreak Attacks
Feb 06, 2026Multi-turn jailbreaks capture the real threat model for safety-aligned chatbots, where single-turn attacks are merely a special case. Yet existing approaches break under exploration complexity and intent drift. We propose SEMA, a simple yet effective framework that trains a multi-turn attacker without relying on any existing strategies or external data. SEMA comprises two stages. Prefilling self-tuning enables usable rollouts by fine-tuning on non-refusal, well-structured, multi-turn adversarial prompts that are self-generated with a minimal prefix, thereby stabilizing subsequent learning. Reinforcement learning with intent-drift-aware reward trains the attacker to elicit valid multi-turn adversarial prompts while maintaining the same harmful objective. We anchor harmful intent in multi-turn jailbreaks via an intent-drift-aware reward that combines intent alignment, compliance risk, and level of detail. Our open-loop attack regime avoids dependence on victim feedback, unifies single- and multi-turn settings, and reduces exploration complexity. Across multiple datasets, victim models, and jailbreak judges, our method achieves state-of-the-art (SOTA) attack success rates (ASR), outperforming all single-turn baselines, manually scripted and template-driven multi-turn baselines, as well as our SFT (Supervised Fine-Tuning) and DPO (Direct Preference Optimization) variants. For instance, SEMA performs an average $80.1\%$ ASR@1 across three closed-source and open-source victim models on AdvBench, 33.9% over SOTA. The approach is compact, reproducible, and transfers across targets, providing a stronger and more realistic stress test for large language model (LLM) safety and enabling automatic redteaming to expose and localize failure modes. Our code is available at: https://github.com/fmmarkmq/SEMA.
Statistical Estimation of Adversarial Risk in Large Language Models under Best-of-N Sampling
Jan 30, 2026Large Language Models (LLMs) are typically evaluated for safety under single-shot or low-budget adversarial prompting, which underestimates real-world risk. In practice, attackers can exploit large-scale parallel sampling to repeatedly probe a model until a harmful response is produced. While recent work shows that attack success increases with repeated sampling, principled methods for predicting large-scale adversarial risk remain limited. We propose a scaling-aware Best-of-N estimation of risk, SABER, for modeling jailbreak vulnerability under Best-of-N sampling. We model sample-level success probabilities using a Beta distribution, the conjugate prior of the Bernoulli distribution, and derive an analytic scaling law that enables reliable extrapolation of large-N attack success rates from small-budget measurements. Using only n=100 samples, our anchored estimator predicts ASR@1000 with a mean absolute error of 1.66, compared to 12.04 for the baseline, which is an 86.2% reduction in estimation error. Our results reveal heterogeneous risk scaling profiles and show that models appearing robust under standard evaluation can experience rapid nonlinear risk amplification under parallel adversarial pressure. This work provides a low-cost, scalable methodology for realistic LLM safety assessment. We will release our code and evaluation scripts upon publication to future research.
GeoNorm: Unify Pre-Norm and Post-Norm with Geodesic Optimization
Jan 29, 2026The placement of normalization layers, specifically Pre-Norm and Post-Norm, remains an open question in Transformer architecture design. In this work, we rethink these approaches through the lens of manifold optimization, interpreting the outputs of the Feed-Forward Network (FFN) and attention layers as update directions in optimization. Building on this perspective, we introduce GeoNorm, a novel method that replaces standard normalization with geodesic updates on the manifold. Furthermore, analogous to learning rate schedules, we propose a layer-wise update decay for the FFN and attention components. Comprehensive experiments demonstrate that GeoNorm consistently outperforms existing normalization methods in Transformer models. Crucially, GeoNorm can be seamlessly integrated into standard Transformer architectures, achieving performance improvements with negligible additional computational cost.
DANCER: Dance ANimation via Condition Enhancement and Rendering with diffusion model
Oct 31, 2025
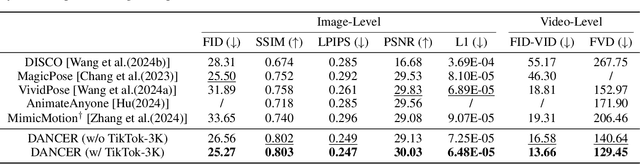
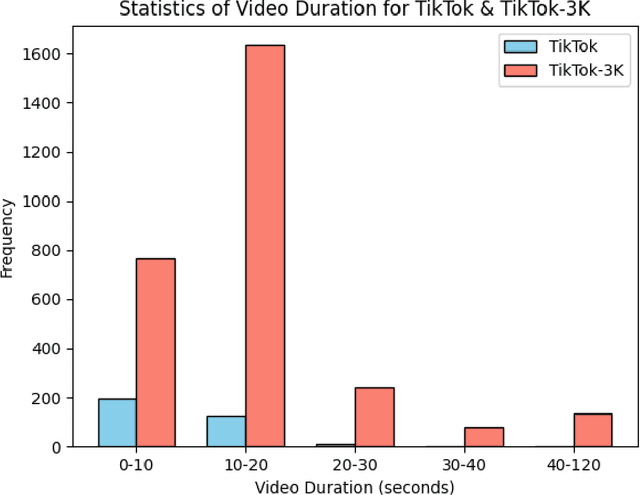

Recently, diffusion models have shown their impressive ability in visual generation tasks. Besides static images, more and more research attentions have been drawn to the generation of realistic videos. The video generation not only has a higher requirement for the quality, but also brings a challenge in ensuring the video continuity. Among all the video generation tasks, human-involved contents, such as human dancing, are even more difficult to generate due to the high degrees of freedom associated with human motions. In this paper, we propose a novel framework, named as DANCER (Dance ANimation via Condition Enhancement and Rendering with Diffusion Model), for realistic single-person dance synthesis based on the most recent stable video diffusion model. As the video generation is generally guided by a reference image and a video sequence, we introduce two important modules into our framework to fully benefit from the two inputs. More specifically, we design an Appearance Enhancement Module (AEM) to focus more on the details of the reference image during the generation, and extend the motion guidance through a Pose Rendering Module (PRM) to capture pose conditions from extra domains. To further improve the generation capability of our model, we also collect a large amount of video data from Internet, and generate a novel datasetTikTok-3K to enhance the model training. The effectiveness of the proposed model has been evaluated through extensive experiments on real-world datasets, where the performance of our model is superior to that of the state-of-the-art methods. All the data and codes will be released upon acceptance.
FlowRL: Matching Reward Distributions for LLM Reasoning
Sep 18, 2025We propose FlowRL: matching the full reward distribution via flow balancing instead of maximizing rewards in large language model (LLM) reinforcement learning (RL). Recent advanced reasoning models adopt reward-maximizing methods (\eg, PPO and GRPO), which tend to over-optimize dominant reward signals while neglecting less frequent but valid reasoning paths, thus reducing diversity. In contrast, we transform scalar rewards into a normalized target distribution using a learnable partition function, and then minimize the reverse KL divergence between the policy and the target distribution. We implement this idea as a flow-balanced optimization method that promotes diverse exploration and generalizable reasoning trajectories. We conduct experiments on math and code reasoning tasks: FlowRL achieves a significant average improvement of $10.0\%$ over GRPO and $5.1\%$ over PPO on math benchmarks, and performs consistently better on code reasoning tasks. These results highlight reward distribution-matching as a key step toward efficient exploration and diverse reasoning in LLM reinforcement learning.
Step More: Going Beyond Single Backpropagation in Meta Learning Based Model Editing
Aug 06, 2025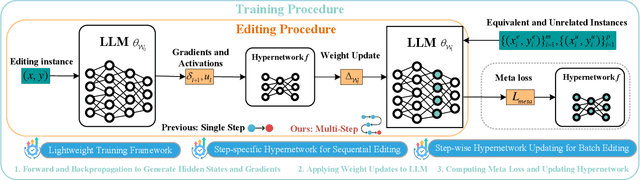
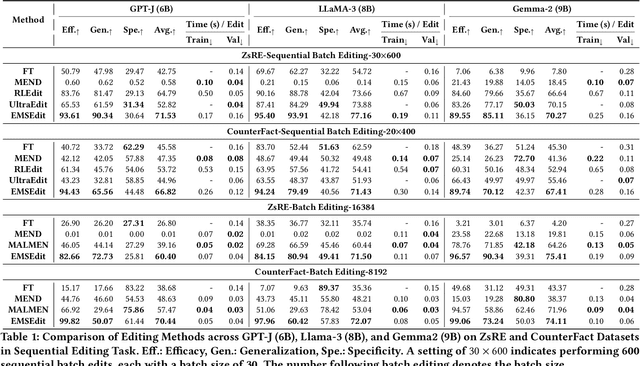
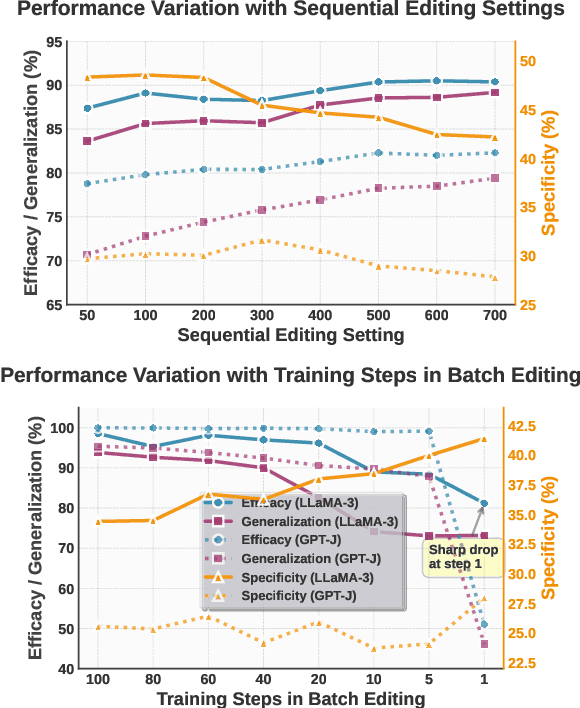
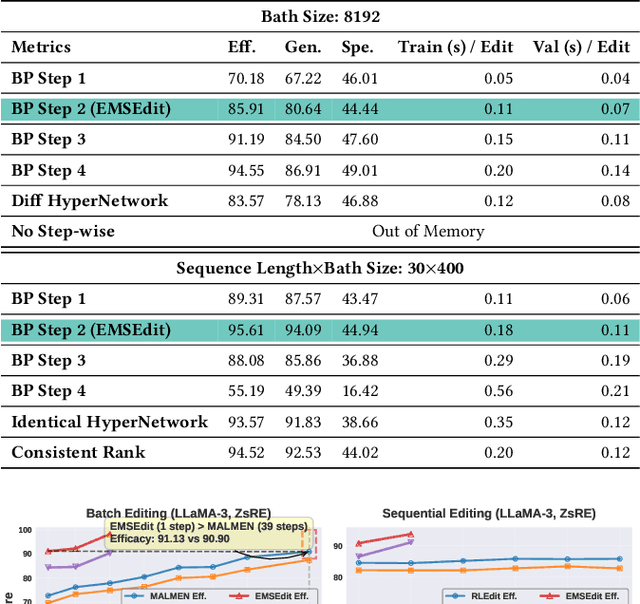
Large Language Models (LLMs) underpin many AI applications, but their static nature makes updating knowledge costly. Model editing offers an efficient alternative by injecting new information through targeted parameter modifications. In particular, meta-learning-based model editing (MLBME) methods have demonstrated notable advantages in both editing effectiveness and efficiency. Despite this, we find that MLBME exhibits suboptimal performance in low-data scenarios, and its training efficiency is bottlenecked by the computation of KL divergence. To address these, we propose $\textbf{S}$tep $\textbf{M}$ore $\textbf{Edit}$ ($\textbf{SMEdit}$), a novel MLBME method that adopts $\textbf{M}$ultiple $\textbf{B}$ackpro$\textbf{P}$agation $\textbf{S}$teps ($\textbf{MBPS}$) to improve editing performance under limited supervision and a norm regularization on weight updates to improve training efficiency. Experimental results on two datasets and two LLMs demonstrate that SMEdit outperforms prior MLBME baselines and the MBPS strategy can be seamlessly integrated into existing methods to further boost their performance. Our code will be released soon.