 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLooping Back to Move Forward: Recursive Transformers for Efficient and Flexible Large Multimodal Models
Feb 09, 2026Large Multimodal Models (LMMs) have achieved remarkable success in vision-language tasks, yet their vast parameter counts are often underutilized during both training and inference. In this work, we embrace the idea of looping back to move forward: reusing model parameters through recursive refinement to extract stronger multimodal representations without increasing model size. We propose RecursiveVLM, a recursive Transformer architecture tailored for LMMs. Two key innovations enable effective looping: (i) a Recursive Connector that aligns features across recursion steps by fusing intermediate-layer hidden states and applying modality-specific projections, respecting the distinct statistical structures of vision and language tokens; (ii) a Monotonic Recursion Loss that supervises every step and guarantees performance improves monotonically with recursion depth. This design transforms recursion into an on-demand refinement mechanism: delivering strong results with few loops on resource-constrained devices and progressively improving outputs when more computation resources are available. Experiments show consistent gains of +3% over standard Transformers and +7% over vanilla recursive baselines, demonstrating that strategic looping is a powerful path toward efficient, deployment-adaptive LMMs.
Ming-Omni: A Unified Multimodal Model for Perception and Generation
Jun 11, 2025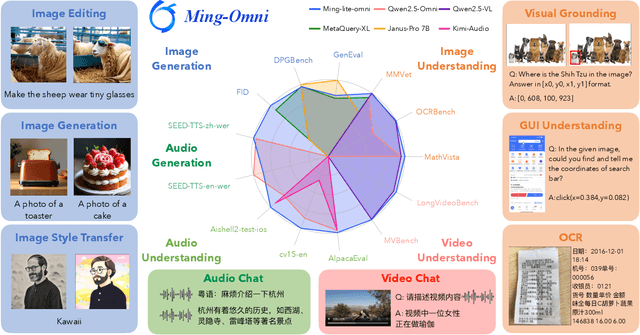
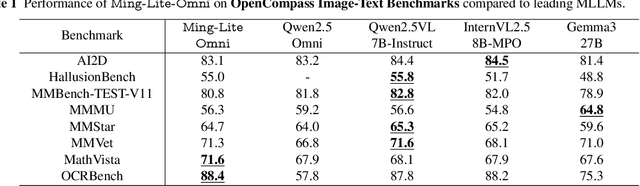
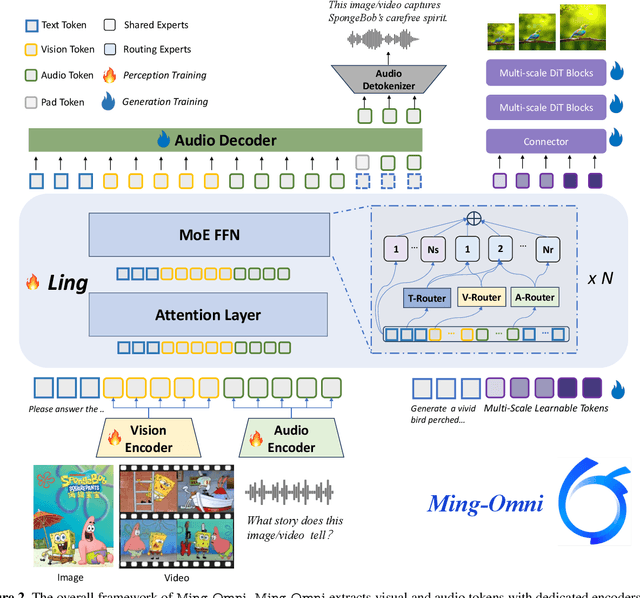
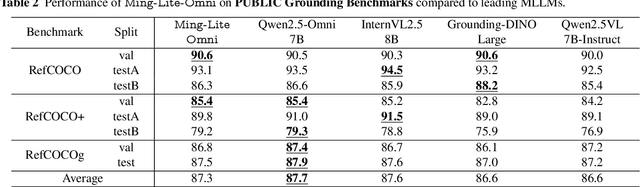
We propose Ming-Omni, a unified multimodal model capable of processing images, text, audio, and video, while demonstrating strong proficiency in both speech and image generation. Ming-Omni employs dedicated encoders to extract tokens from different modalities, which are then processed by Ling, an MoE architecture equipped with newly proposed modality-specific routers. This design enables a single model to efficiently process and fuse multimodal inputs within a unified framework, thereby facilitating diverse tasks without requiring separate models, task-specific fine-tuning, or structural redesign. Importantly, Ming-Omni extends beyond conventional multimodal models by supporting audio and image generation. This is achieved through the integration of an advanced audio decoder for natural-sounding speech and Ming-Lite-Uni for high-quality image generation, which also allow the model to engage in context-aware chatting, perform text-to-speech conversion, and conduct versatile image editing. Our experimental results showcase Ming-Omni offers a powerful solution for unified perception and generation across all modalities. Notably, our proposed Ming-Omni is the first open-source model we are aware of to match GPT-4o in modality support, and we release all code and model weights to encourage further research and development in the community.
EvoMoE: Expert Evolution in Mixture of Experts for Multimodal Large Language Models
May 28, 2025Recent advancements have shown that the Mixture of Experts (MoE) approach significantly enhances the capacity of large language models (LLMs) and improves performance on downstream tasks. Building on these promising results, multi-modal large language models (MLLMs) have increasingly adopted MoE techniques. However, existing multi-modal MoE tuning methods typically face two key challenges: expert uniformity and router rigidity. Expert uniformity occurs because MoE experts are often initialized by simply replicating the FFN parameters from LLMs, leading to homogenized expert functions and weakening the intended diversification of the MoE architecture. Meanwhile, router rigidity stems from the prevalent use of static linear routers for expert selection, which fail to distinguish between visual and textual tokens, resulting in similar expert distributions for image and text. To address these limitations, we propose EvoMoE, an innovative MoE tuning framework. EvoMoE introduces a meticulously designed expert initialization strategy that progressively evolves multiple robust experts from a single trainable expert, a process termed expert evolution that specifically targets severe expert homogenization. Furthermore, we introduce the Dynamic Token-aware Router (DTR), a novel routing mechanism that allocates input tokens to appropriate experts based on their modality and intrinsic token values. This dynamic routing is facilitated by hypernetworks, which dynamically generate routing weights tailored for each individual token. Extensive experiments demonstrate that EvoMoE significantly outperforms other sparse MLLMs across a variety of multi-modal benchmarks, including MME, MMBench, TextVQA, and POPE. Our results highlight the effectiveness of EvoMoE in enhancing the performance of MLLMs by addressing the critical issues of expert uniformity and router rigidity.
DeepMath-Creative: A Benchmark for Evaluating Mathematical Creativity of Large Language Models
May 13, 2025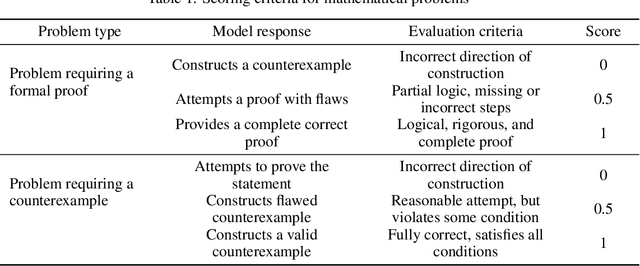
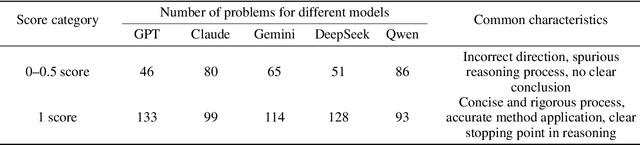
To advance the mathematical proficiency of large language models (LLMs), the DeepMath team has launched an open-source initiative aimed at developing an open mathematical LLM and systematically evaluating its mathematical creativity. This paper represents the initial contribution of this initiative. While recent developments in mathematical LLMs have predominantly emphasized reasoning skills, as evidenced by benchmarks on elementary to undergraduate-level mathematical tasks, the creative capabilities of these models have received comparatively little attention, and evaluation datasets remain scarce. To address this gap, we propose an evaluation criteria for mathematical creativity and introduce DeepMath-Creative, a novel, high-quality benchmark comprising constructive problems across algebra, geometry, analysis, and other domains. We conduct a systematic evaluation of mainstream LLMs' creative problem-solving abilities using this dataset. Experimental results show that even under lenient scoring criteria -- emphasizing core solution components and disregarding minor inaccuracies, such as small logical gaps, incomplete justifications, or redundant explanations -- the best-performing model, O3 Mini, achieves merely 70% accuracy, primarily on basic undergraduate-level constructive tasks. Performance declines sharply on more complex problems, with models failing to provide substantive strategies for open problems. These findings suggest that, although current LLMs display a degree of constructive proficiency on familiar and lower-difficulty problems, such performance is likely attributable to the recombination of memorized patterns rather than authentic creative insight or novel synthesis.
Panther: Illuminate the Sight of Multimodal LLMs with Instruction-Guided Visual Prompts
Nov 22, 2024



Multimodal large language models (MLLMs) are closing the gap to human visual perception capability rapidly, while, still lag behind on attending to subtle images details or locating small objects precisely, etc. Common schemes to tackle these issues include deploying multiple vision encoders or operating on original high-resolution images. Few studies have concentrated on taking the textual instruction into improving visual representation, resulting in losing focus in some vision-centric tasks, a phenomenon we herein termed as Amblyopia. In this work, we introduce Panther, a MLLM that closely adheres to user instruction and locates targets of interests precisely, with the finesse of a black panther. Specifically, Panther comprises three integral components: Panther-VE, Panther-Bridge, and Panther-Decoder. Panther-VE integrates user instruction information at the early stages of the vision encoder, thereby extracting the most relevant and useful visual representations. The Panther-Bridge module, equipped with powerful filtering capabilities, significantly reduces redundant visual information, leading to a substantial savings in training costs. The Panther-Decoder is versatile and can be employed with any decoder-only architecture of LLMs without discrimination. Experimental results, particularly on vision-centric benchmarks, have demonstrated the effectiveness of Panther.
Multi-Modal Prompt Learning on Blind Image Quality Assessment
Apr 23, 2024



Image Quality Assessment (IQA) models benefit significantly from semantic information, which allows them to treat different types of objects distinctly. Currently, leveraging semantic information to enhance IQA is a crucial research direction. Traditional methods, hindered by a lack of sufficiently annotated data, have employed the CLIP image-text pretraining model as their backbone to gain semantic awareness. However, the generalist nature of these pre-trained Vision-Language (VL) models often renders them suboptimal for IQA-specific tasks. Recent approaches have attempted to address this mismatch using prompt technology, but these solutions have shortcomings. Existing prompt-based VL models overly focus on incremental semantic information from text, neglecting the rich insights available from visual data analysis. This imbalance limits their performance improvements in IQA tasks. This paper introduces an innovative multi-modal prompt-based methodology for IQA. Our approach employs carefully crafted prompts that synergistically mine incremental semantic information from both visual and linguistic data. Specifically, in the visual branch, we introduce a multi-layer prompt structure to enhance the VL model's adaptability. In the text branch, we deploy a dual-prompt scheme that steers the model to recognize and differentiate between scene category and distortion type, thereby refining the model's capacity to assess image quality. Our experimental findings underscore the effectiveness of our method over existing Blind Image Quality Assessment (BIQA) approaches. Notably, it demonstrates competitive performance across various datasets. Our method achieves Spearman Rank Correlation Coefficient (SRCC) values of 0.961(surpassing 0.946 in CSIQ) and 0.941 (exceeding 0.930 in KADID), illustrating its robustness and accuracy in diverse contexts.
RESTORE: Towards Feature Shift for Vision-Language Prompt Learning
Mar 10, 2024



Prompt learning is effective for fine-tuning foundation models to improve their generalization across a variety of downstream tasks. However, the prompts that are independently optimized along a single modality path, may sacrifice the vision-language alignment of pre-trained models in return for improved performance on specific tasks and classes, leading to poorer generalization. In this paper, we first demonstrate that prompt tuning along only one single branch of CLIP (e.g., language or vision) is the reason why the misalignment occurs. Without proper regularization across the learnable parameters in different modalities, prompt learning violates the original pre-training constraints inherent in the two-tower architecture. To address such misalignment, we first propose feature shift, which is defined as the variation of embeddings after introducing the learned prompts, to serve as an explanatory tool. We dive into its relation with generalizability and thereafter propose RESTORE, a multi-modal prompt learning method that exerts explicit constraints on cross-modal consistency. To be more specific, to prevent feature misalignment, a feature shift consistency is introduced to synchronize inter-modal feature shifts by measuring and regularizing the magnitude of discrepancy during prompt tuning. In addition, we propose a "surgery" block to avoid short-cut hacking, where cross-modal misalignment can still be severe if the feature shift of each modality varies drastically at the same rate. It is implemented as feed-forward adapters upon both modalities to alleviate the misalignment problem. Extensive experiments on 15 datasets demonstrate that our method outperforms the state-of-the-art prompt tuning methods without compromising feature alignment.
Sinkhorn Distance Minimization for Knowledge Distillation
Feb 27, 2024



Knowledge distillation (KD) has been widely adopted to compress large language models (LLMs). Existing KD methods investigate various divergence measures including the Kullback-Leibler (KL), reverse Kullback-Leibler (RKL), and Jensen-Shannon (JS) divergences. However, due to limitations inherent in their assumptions and definitions, these measures fail to deliver effective supervision when few distribution overlap exists between the teacher and the student. In this paper, we show that the aforementioned KL, RKL, and JS divergences respectively suffer from issues of mode-averaging, mode-collapsing, and mode-underestimation, which deteriorates logits-based KD for diverse NLP tasks. We propose the Sinkhorn Knowledge Distillation (SinKD) that exploits the Sinkhorn distance to ensure a nuanced and precise assessment of the disparity between teacher and student distributions. Besides, profit by properties of the Sinkhorn metric, we can get rid of sample-wise KD that restricts the perception of divergence in each teacher-student sample pair. Instead, we propose a batch-wise reformulation to capture geometric intricacies of distributions across samples in the high-dimensional space. Comprehensive evaluation on GLUE and SuperGLUE, in terms of comparability, validity, and generalizability, highlights our superiority over state-of-the-art methods on all kinds of LLMs with encoder-only, encoder-decoder, and decoder-only architectures.
MMICT: Boosting Multi-Modal Fine-Tuning with In-Context Examples
Dec 12, 2023



Although In-Context Learning (ICL) brings remarkable performance gains to Large Language Models (LLMs), the improvements remain lower than fine-tuning on downstream tasks. This paper introduces Multi-Modal In-Context Tuning (MMICT), a novel multi-modal fine-tuning paradigm that boosts multi-modal fine-tuning by fully leveraging the promising ICL capability of multi-modal LLMs (MM-LLMs). We propose the Multi-Modal Hub (M-Hub), a unified module that captures various multi-modal features according to different inputs and objectives. Based on M-Hub, MMICT enables MM-LLMs to learn from in-context visual-guided textual features and subsequently generate outputs conditioned on the textual-guided visual features. Moreover, leveraging the flexibility of M-Hub, we design a variety of in-context demonstrations. Extensive experiments on a diverse range of downstream multi-modal tasks demonstrate that MMICT significantly outperforms traditional fine-tuning strategy and the vanilla ICT method that directly takes the concatenation of all information from different modalities as input.
Less is More: Learning Reference Knowledge Using No-Reference Image Quality Assessment
Dec 01, 2023Image Quality Assessment (IQA) with reference images have achieved great success by imitating the human vision system, in which the image quality is effectively assessed by comparing the query image with its pristine reference image. However, for the images in the wild, it is quite difficult to access accurate reference images. We argue that it is possible to learn reference knowledge under the No-Reference Image Quality Assessment (NR-IQA) setting, which is effective and efficient empirically. Concretely, by innovatively introducing a novel feature distillation method in IQA, we propose a new framework to learn comparative knowledge from non-aligned reference images. And then, to achieve fast convergence and avoid overfitting, we further propose an inductive bias regularization. Such a framework not only solves the congenital defects of NR-IQA but also improves the feature extraction framework, enabling it to express more abundant quality information. Surprisingly, our method utilizes less input while obtaining a more significant improvement compared to the teacher models. Extensive experiments on eight standard NR-IQA datasets demonstrate the superior performance to the state-of-the-art NR-IQA methods, i.e., achieving the PLCC values of 0.917 (vs. 0.884 in LIVEC) and 0.686 (vs. 0.661 in LIVEFB).