 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Long-Horizon Task Mirage? Diagnosing Where and Why Agentic Systems Break
Apr 13, 2026Large language model (LLM) agents perform strongly on short- and mid-horizon tasks, but often break down on long-horizon tasks that require extended, interdependent action sequences. Despite rapid progress in agentic systems, these long-horizon failures remain poorly characterized, hindering principled diagnosis and comparison across domains. To address this gap, we introduce HORIZON, an initial cross-domain diagnostic benchmark for systematically constructing tasks and analyzing long-horizon failure behaviors in LLM-based agents. Using HORIZON, we evaluate state-of-the-art (SOTA) agents from multiple model families (GPT-5 variants and Claude models), collecting 3100+ trajectories across four representative agentic domains to study horizon-dependent degradation patterns. We further propose a trajectory-grounded LLM-as-a-Judge pipeline for scalable and reproducible failure attribution, and validate it with human annotation on trajectories, achieving strong agreement (inter-annotator κ=0.61; human-judge κ=0.84). Our findings offer an initial methodological step toward systematic, cross-domain analysis of long-horizon agent failures and offer practical guidance for building more reliable long-horizon agents. We release our project website at \href{https://xwang2775.github.io/horizon-leaderboard/}{HORIZON Leaderboard} and welcome contributions from the community.
How and Why LLMs Generalize: A Fine-Grained Analysis of LLM Reasoning from Cognitive Behaviors to Low-Level Patterns
Dec 30, 2025Large Language Models (LLMs) display strikingly different generalization behaviors: supervised fine-tuning (SFT) often narrows capability, whereas reinforcement-learning (RL) tuning tends to preserve it. The reasons behind this divergence remain unclear, as prior studies have largely relied on coarse accuracy metrics. We address this gap by introducing a novel benchmark that decomposes reasoning into atomic core skills such as calculation, fact retrieval, simulation, enumeration, and diagnostic, providing a concrete framework for addressing the fundamental question of what constitutes reasoning in LLMs. By isolating and measuring these core skills, the benchmark offers a more granular view of how specific cognitive abilities emerge, transfer, and sometimes collapse during post-training. Combined with analyses of low-level statistical patterns such as distributional divergence and parameter statistics, it enables a fine-grained study of how generalization evolves under SFT and RL across mathematical, scientific reasoning, and non-reasoning tasks. Our meta-probing framework tracks model behavior at different training stages and reveals that RL-tuned models maintain more stable behavioral profiles and resist collapse in reasoning skills, whereas SFT models exhibit sharper drift and overfit to surface patterns. This work provides new insights into the nature of reasoning in LLMs and points toward principles for designing training strategies that foster broad, robust generalization.
Transolver is a Linear Transformer: Revisiting Physics-Attention through the Lens of Linear Attention
Nov 11, 2025



Recent advances in Transformer-based Neural Operators have enabled significant progress in data-driven solvers for Partial Differential Equations (PDEs). Most current research has focused on reducing the quadratic complexity of attention to address the resulting low training and inference efficiency. Among these works, Transolver stands out as a representative method that introduces Physics-Attention to reduce computational costs. Physics-Attention projects grid points into slices for slice attention, then maps them back through deslicing. However, we observe that Physics-Attention can be reformulated as a special case of linear attention, and that the slice attention may even hurt the model performance. Based on these observations, we argue that its effectiveness primarily arises from the slice and deslice operations rather than interactions between slices. Building on this insight, we propose a two-step transformation to redesign Physics-Attention into a canonical linear attention, which we call Linear Attention Neural Operator (LinearNO). Our method achieves state-of-the-art performance on six standard PDE benchmarks, while reducing the number of parameters by an average of 40.0% and computational cost by 36.2%. Additionally, it delivers superior performance on two challenging, industrial-level datasets: AirfRANS and Shape-Net Car.
Hierarchical Deep Deterministic Policy Gradient for Autonomous Maze Navigation of Mobile Robots
Aug 07, 2025Maze navigation is a fundamental challenge in robotics, requiring agents to traverse complex environments efficiently. While the Deep Deterministic Policy Gradient (DDPG) algorithm excels in control tasks, its performance in maze navigation suffers from sparse rewards, inefficient exploration, and long-horizon planning difficulties, often leading to low success rates and average rewards, sometimes even failing to achieve effective navigation. To address these limitations, this paper proposes an efficient Hierarchical DDPG (HDDPG) algorithm, which includes high-level and low-level policies. The high-level policy employs an advanced DDPG framework to generate intermediate subgoals from a long-term perspective and on a higher temporal scale. The low-level policy, also powered by the improved DDPG algorithm, generates primitive actions by observing current states and following the subgoal assigned by the high-level policy. The proposed method enhances stability with off-policy correction, refining subgoal assignments by relabeling historical experiences. Additionally, adaptive parameter space noise is utilized to improve exploration, and a reshaped intrinsic-extrinsic reward function is employed to boost learning efficiency. Further optimizations, including gradient clipping and Xavier initialization, are employed to improve robustness. The proposed algorithm is rigorously evaluated through numerical simulation experiments executed using the Robot Operating System (ROS) and Gazebo. Regarding the three distinct final targets in autonomous maze navigation tasks, HDDPG significantly overcomes the limitations of standard DDPG and its variants, improving the success rate by at least 56.59% and boosting the average reward by a minimum of 519.03 compared to baseline algorithms.
DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
Jan 05, 2024



The rapid development of open-source large language models (LLMs) has been truly remarkable. However, the scaling law described in previous literature presents varying conclusions, which casts a dark cloud over scaling LLMs. We delve into the study of scaling laws and present our distinctive findings that facilitate scaling of large scale models in two commonly used open-source configurations, 7B and 67B. Guided by the scaling laws, we introduce DeepSeek LLM, a project dedicated to advancing open-source language models with a long-term perspective. To support the pre-training phase, we have developed a dataset that currently consists of 2 trillion tokens and is continuously expanding. We further conduct supervised fine-tuning (SFT) and Direct Preference Optimization (DPO) on DeepSeek LLM Base models, resulting in the creation of DeepSeek Chat models. Our evaluation results demonstrate that DeepSeek LLM 67B surpasses LLaMA-2 70B on various benchmarks, particularly in the domains of code, mathematics, and reasoning. Furthermore, open-ended evaluations reveal that DeepSeek LLM 67B Chat exhibits superior performance compared to GPT-3.5.
Breaking the Curse of Quality Saturation with User-Centric Ranking
May 24, 2023



A key puzzle in search, ads, and recommendation is that the ranking model can only utilize a small portion of the vastly available user interaction data. As a result, increasing data volume, model size, or computation FLOPs will quickly suffer from diminishing returns. We examined this problem and found that one of the root causes may lie in the so-called ``item-centric'' formulation, which has an unbounded vocabulary and thus uncontrolled model complexity. To mitigate quality saturation, we introduce an alternative formulation named ``user-centric ranking'', which is based on a transposed view of the dyadic user-item interaction data. We show that this formulation has a promising scaling property, enabling us to train better-converged models on substantially larger data sets.
Students' Voices on Generative AI: Perceptions, Benefits, and Challenges in Higher Education
Apr 29, 2023This study explores university students' perceptions of generative AI (GenAI) technologies, such as ChatGPT, in higher education, focusing on familiarity, their willingness to engage, potential benefits and challenges, and effective integration. A survey of 399 undergraduate and postgraduate students from various disciplines in Hong Kong revealed a generally positive attitude towards GenAI in teaching and learning. Students recognized the potential for personalized learning support, writing and brainstorming assistance, and research and analysis capabilities. However, concerns about accuracy, privacy, ethical issues, and the impact on personal development, career prospects, and societal values were also expressed. According to John Biggs' 3P model, student perceptions significantly influence learning approaches and outcomes. By understanding students' perceptions, educators and policymakers can tailor GenAI technologies to address needs and concerns while promoting effective learning outcomes. Insights from this study can inform policy development around the integration of GenAI technologies into higher education. By understanding students' perceptions and addressing their concerns, policymakers can create well-informed guidelines and strategies for the responsible and effective implementation of GenAI tools, ultimately enhancing teaching and learning experiences in higher education.
A Semi-Synthetic Dataset Generation Framework for Causal Inference in Recommender Systems
Feb 23, 2022
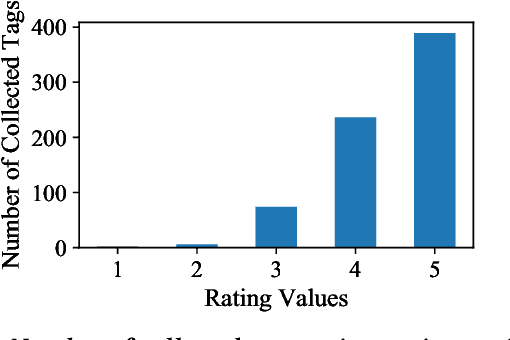
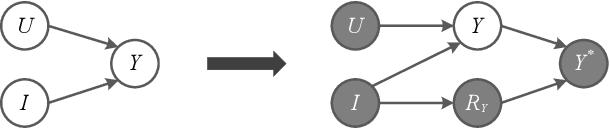
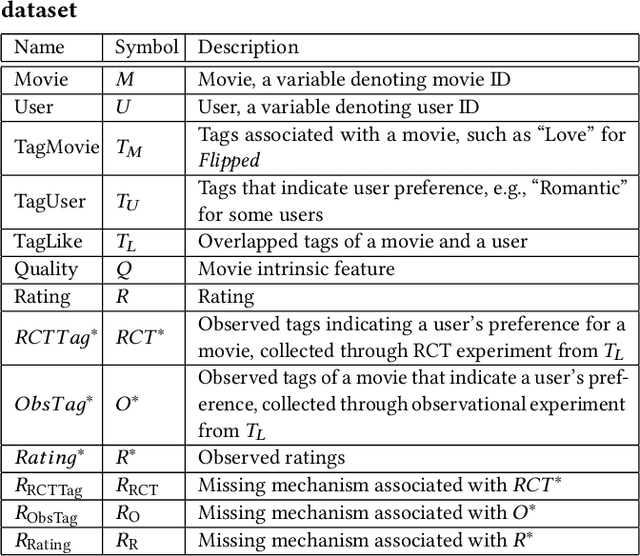
Accurate recommendation and reliable explanation are two key issues for modern recommender systems. However, most recommendation benchmarks only concern the prediction of user-item ratings while omitting the underlying causes behind the ratings. For example, the widely-used Yahoo!R3 dataset contains little information on the causes of the user-movie ratings. A solution could be to conduct surveys and require the users to provide such information. In practice, the user surveys can hardly avoid compliance issues and sparse user responses, which greatly hinders the exploration of causality-based recommendation. To better support the studies of causal inference and further explanations in recommender systems, we propose a novel semi-synthetic data generation framework for recommender systems where causal graphical models with missingness are employed to describe the causal mechanism of practical recommendation scenarios. To illustrate the use of our framework, we construct a semi-synthetic dataset with Causal Tags And Ratings (CTAR), based on the movies as well as their descriptive tags and rating information collected from a famous movie rating website. Using the collected data and the causal graph, the user-item-ratings and their corresponding user-item-tags are automatically generated, which provides the reasons (selected tags) why the user rates the items. Descriptive statistics and baseline results regarding the CTAR dataset are also reported. The proposed data generation framework is not limited to recommendation, and the released APIs can be used to generate customized datasets for other research tasks.
Causal Analysis Framework for Recommendation
Jan 18, 2022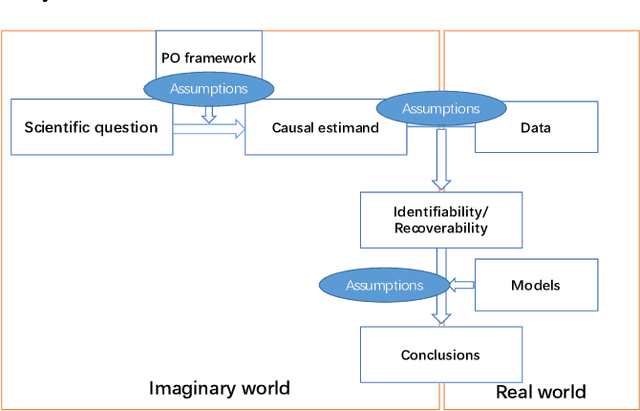
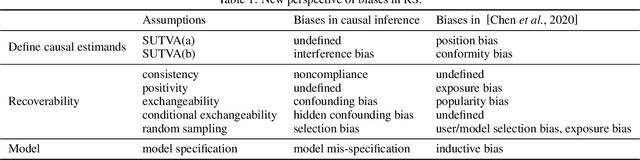
Recently, recommendation based on causal inference has gained much attention in the industrial community. The introduction of causal techniques into recommender systems (RS) has brought great development to this field and has gradually become a trend. However, a unified causal analysis framework has not been established yet. On one hand, the existing causal methods in RS lack a clear causal and mathematical formalization on the scientific questions of interest. Many confusions need to be clarified: what exactly is being estimated, for what purpose, in which scenario, by which technique, and under what plausible assumptions. On the other hand, technically speaking, the existence of various biases is the main obstacle to drawing causal conclusions from observed data. Yet, formal definitions of the biases in RS are still not clear. Both of the limitations greatly hinder the development of RS. In this paper, we attempt to give a causal analysis framework to accommodate different scenarios in RS, thereby providing a principled and rigorous operational guideline for causal recommendation. We first propose a step-by-step guideline on how to clarify and investigate problems in RS using causal concepts. Then, we provide a new taxonomy and give a formal definition of various biases in RS from the perspective of violating what assumptions are adopted in standard causal analysis. Finally, we find that many problems in RS can be well formalized into a few scenarios using the proposed causal analysis framework.
Time2Graph: Revisiting Time Series Modeling with Dynamic Shapelets
Nov 11, 2019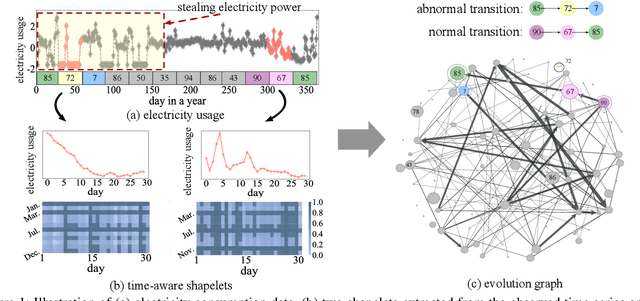
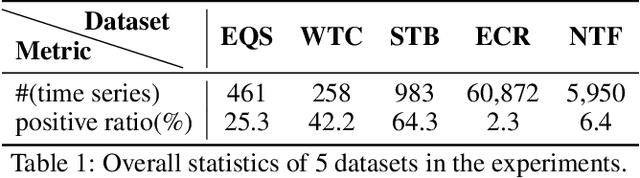
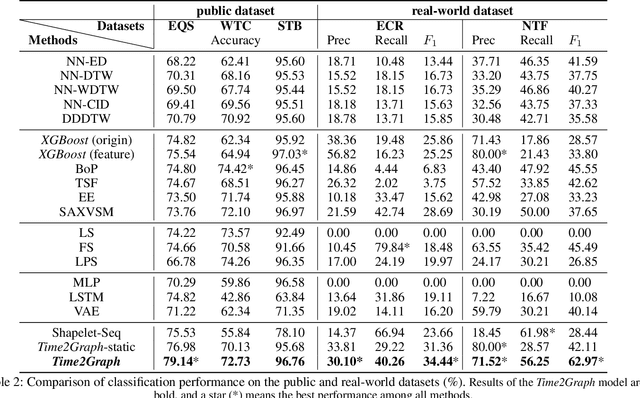
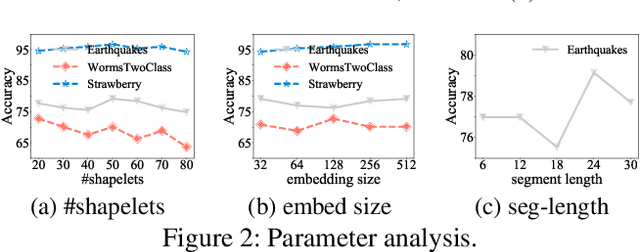
Time series modeling has attracted extensive research efforts; however, achieving both reliable efficiency and interpretability from a unified model still remains a challenging problem. Among the literature, shapelets offer interpretable and explanatory insights in the classification tasks, while most existing works ignore the differing representative power at different time slices, as well as (more importantly) the evolution pattern of shapelets. In this paper, we propose to extract time-aware shapelets by designing a two-level timing factor. Moreover, we define and construct the shapelet evolution graph, which captures how shapelets evolve over time and can be incorporated into the time series embeddings by graph embedding algorithms. To validate whether the representations obtained in this way can be applied effectively in various scenarios, we conduct experiments based on three public time series datasets, and two real-world datasets from different domains. Experimental results clearly show the improvements achieved by our approach compared with 17 state-of-the-art baselines.