 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWoVR: World Models as Reliable Simulators for Post-Training VLA Policies with RL
Feb 15, 2026Reinforcement learning (RL) promises to unlock capabilities beyond imitation learning for Vision-Language-Action (VLA) models, but its requirement for massive real-world interaction prevents direct deployment on physical robots. Recent work attempts to use learned world models as simulators for policy optimization, yet closed-loop imagined rollouts inevitably suffer from hallucination and long-horizon error accumulation. Such errors do not merely degrade visual fidelity; they corrupt the optimization signal, encouraging policies to exploit model inaccuracies rather than genuine task progress. We propose WoVR, a reliable world-model-based reinforcement learning framework for post-training VLA policies. Instead of assuming a faithful world model, WoVR explicitly regulates how RL interacts with imperfect imagined dynamics. It improves rollout stability through a controllable action-conditioned video world model, reshapes imagined interaction to reduce effective error depth via Keyframe-Initialized Rollouts, and maintains policy-simulator alignment through World Model-Policy co-evolution. Extensive experiments on LIBERO benchmarks and real-world robotic manipulation demonstrate that WoVR enables stable long-horizon imagined rollouts and effective policy optimization, improving average LIBERO success from 39.95% to 69.2% (+29.3 points) and real-robot success from 61.7% to 91.7% (+30.0 points). These results show that learned world models can serve as practical simulators for reinforcement learning when hallucination is explicitly controlled.
RLinf-USER: A Unified and Extensible System for Real-World Online Policy Learning in Embodied AI
Feb 08, 2026Online policy learning directly in the physical world is a promising yet challenging direction for embodied intelligence. Unlike simulation, real-world systems cannot be arbitrarily accelerated, cheaply reset, or massively replicated, which makes scalable data collection, heterogeneous deployment, and long-horizon effective training difficult. These challenges suggest that real-world policy learning is not only an algorithmic issue but fundamentally a systems problem. We present USER, a Unified and extensible SystEm for Real-world online policy learning. USER treats physical robots as first-class hardware resources alongside GPUs through a unified hardware abstraction layer, enabling automatic discovery, management, and scheduling of heterogeneous robots. To address cloud-edge communication, USER introduces an adaptive communication plane with tunneling-based networking, distributed data channels for traffic localization, and streaming-multiprocessor-aware weight synchronization to regulate GPU-side overhead. On top of this infrastructure, USER organizes learning as a fully asynchronous framework with a persistent, cache-aware buffer, enabling efficient long-horizon experiments with robust crash recovery and reuse of historical data. In addition, USER provides extensible abstractions for rewards, algorithms, and policies, supporting online imitation or reinforcement learning of CNN/MLP, generative policies, and large vision-language-action (VLA) models within a unified pipeline. Results in both simulation and the real world show that USER enables multi-robot coordination, heterogeneous manipulators, edge-cloud collaboration with large models, and long-running asynchronous training, offering a unified and extensible systems foundation for real-world online policy learning.
WideSeek-R1: Exploring Width Scaling for Broad Information Seeking via Multi-Agent Reinforcement Learning
Feb 04, 2026Recent advancements in Large Language Models (LLMs) have largely focused on depth scaling, where a single agent solves long-horizon problems with multi-turn reasoning and tool use. However, as tasks grow broader, the key bottleneck shifts from individual competence to organizational capability. In this work, we explore a complementary dimension of width scaling with multi-agent systems to address broad information seeking. Existing multi-agent systems often rely on hand-crafted workflows and turn-taking interactions that fail to parallelize work effectively. To bridge this gap, we propose WideSeek-R1, a lead-agent-subagent framework trained via multi-agent reinforcement learning (MARL) to synergize scalable orchestration and parallel execution. By utilizing a shared LLM with isolated contexts and specialized tools, WideSeek-R1 jointly optimizes the lead agent and parallel subagents on a curated dataset of 20k broad information-seeking tasks. Extensive experiments show that WideSeek-R1-4B achieves an item F1 score of 40.0% on the WideSearch benchmark, which is comparable to the performance of single-agent DeepSeek-R1-671B. Furthermore, WideSeek-R1-4B exhibits consistent performance gains as the number of parallel subagents increases, highlighting the effectiveness of width scaling.
$π_\texttt{RL}$: Online RL Fine-tuning for Flow-based Vision-Language-Action Models
Oct 29, 2025


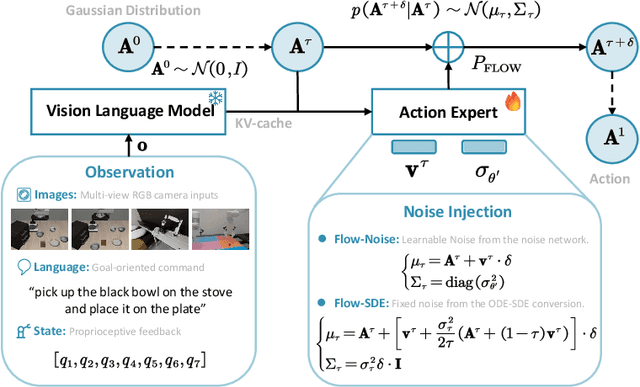
Vision-Language-Action (VLA) models enable robots to understand and perform complex tasks from multimodal input. Although recent work explores using reinforcement learning (RL) to automate the laborious data collection process in scaling supervised fine-tuning (SFT), applying large-scale RL to flow-based VLAs (e.g., $\pi_0$, $\pi_{0.5}$) remains challenging due to intractable action log-likelihoods from iterative denoising. We address this challenge with $\pi_{\text{RL}}$, an open-source framework for training flow-based VLAs in parallel simulation. $\pi_{\text{RL}}$ implements two RL algorithms: (1) {Flow-Noise} models the denoising process as a discrete-time MDP with a learnable noise network for exact log-likelihood computation. (2) {Flow-SDE} integrates denoising with agent-environment interaction, formulating a two-layer MDP that employs ODE-to-SDE conversion for efficient RL exploration. We evaluate $\pi_{\text{RL}}$ on LIBERO and ManiSkill benchmarks. On LIBERO, $\pi_{\text{RL}}$ boosts few-shot SFT models $\pi_0$ and $\pi_{0.5}$ from 57.6% to 97.6% and from 77.1% to 98.3%, respectively. In ManiSkill, we train $\pi_{\text{RL}}$ in 320 parallel environments, improving $\pi_0$ from 41.6% to 85.7% and $\pi_{0.5}$ from 40.0% to 84.8% across 4352 pick-and-place tasks, demonstrating scalable multitask RL under heterogeneous simulation. Overall, $\pi_{\text{RL}}$ achieves significant performance gains and stronger generalization over SFT-models, validating the effectiveness of online RL for flow-based VLAs.
RLinf: Flexible and Efficient Large-scale Reinforcement Learning via Macro-to-Micro Flow Transformation
Sep 19, 2025

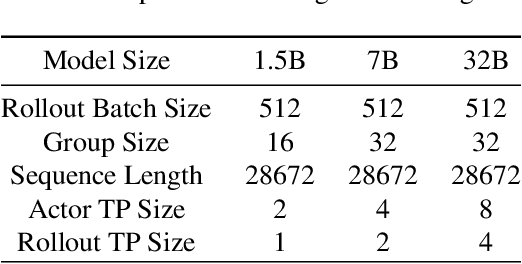
Reinforcement learning (RL) has demonstrated immense potential in advancing artificial general intelligence, agentic intelligence, and embodied intelligence. However, the inherent heterogeneity and dynamicity of RL workflows often lead to low hardware utilization and slow training on existing systems. In this paper, we present RLinf, a high-performance RL training system based on our key observation that the major roadblock to efficient RL training lies in system flexibility. To maximize flexibility and efficiency, RLinf is built atop a novel RL system design paradigm called macro-to-micro flow transformation (M2Flow), which automatically breaks down high-level, easy-to-compose RL workflows at both the temporal and spatial dimensions, and recomposes them into optimized execution flows. Supported by RLinf worker's adaptive communication capability, we devise context switching and elastic pipelining to realize M2Flow transformation, and a profiling-guided scheduling policy to generate optimal execution plans. Extensive evaluations on both reasoning RL and embodied RL tasks demonstrate that RLinf consistently outperforms state-of-the-art systems, achieving 1.1x-2.13x speedup in end-to-end training throughput.
You Only Cache Once: Decoder-Decoder Architectures for Language Models
May 08, 2024We introduce a decoder-decoder architecture, YOCO, for large language models, which only caches key-value pairs once. It consists of two components, i.e., a cross-decoder stacked upon a self-decoder. The self-decoder efficiently encodes global key-value (KV) caches that are reused by the cross-decoder via cross-attention. The overall model behaves like a decoder-only Transformer, although YOCO only caches once. The design substantially reduces GPU memory demands, yet retains global attention capability. Additionally, the computation flow enables prefilling to early exit without changing the final output, thereby significantly speeding up the prefill stage. Experimental results demonstrate that YOCO achieves favorable performance compared to Transformer in various settings of scaling up model size and number of training tokens. We also extend YOCO to 1M context length with near-perfect needle retrieval accuracy. The profiling results show that YOCO improves inference memory, prefill latency, and throughput by orders of magnitude across context lengths and model sizes. Code is available at https://aka.ms/YOCO.
Efficient Large Language Models: A Survey
Dec 23, 2023



Large Language Models (LLMs) have demonstrated remarkable capabilities in important tasks such as natural language understanding, language generation, and complex reasoning and have the potential to make a substantial impact on our society. Such capabilities, however, come with the considerable resources they demand, highlighting the strong need to develop effective techniques for addressing their efficiency challenges. In this survey, we provide a systematic and comprehensive review of efficient LLMs research. We organize the literature in a taxonomy consisting of three main categories, covering distinct yet interconnected efficient LLMs topics from model-centric, data-centric, and framework-centric perspective, respectively. We have also created a GitHub repository where we compile the papers featured in this survey at https://github.com/AIoT-MLSys-Lab/EfficientLLMs, and will actively maintain this repository and incorporate new research as it emerges. We hope our survey can serve as a valuable resource to help researchers and practitioners gain a systematic understanding of the research developments in efficient LLMs and inspire them to contribute to this important and exciting field.
AutoTaskFormer: Searching Vision Transformers for Multi-task Learning
Apr 20, 2023



Vision Transformers have shown great performance in single tasks such as classification and segmentation. However, real-world problems are not isolated, which calls for vision transformers that can perform multiple tasks concurrently. Existing multi-task vision transformers are handcrafted and heavily rely on human expertise. In this work, we propose a novel one-shot neural architecture search framework, dubbed AutoTaskFormer (Automated Multi-Task Vision TransFormer), to automate this process. AutoTaskFormer not only identifies the weights to share across multiple tasks automatically, but also provides thousands of well-trained vision transformers with a wide range of parameters (e.g., number of heads and network depth) for deployment under various resource constraints. Experiments on both small-scale (2-task Cityscapes and 3-task NYUv2) and large-scale (16-task Taskonomy) datasets show that AutoTaskFormer outperforms state-of-the-art handcrafted vision transformers in multi-task learning. The entire code and models will be open-sourced.
ElasticViT: Conflict-aware Supernet Training for Deploying Fast Vision Transformer on Diverse Mobile Devices
Mar 21, 2023



Neural Architecture Search (NAS) has shown promising performance in the automatic design of vision transformers (ViT) exceeding 1G FLOPs. However, designing lightweight and low-latency ViT models for diverse mobile devices remains a big challenge. In this work, we propose ElasticViT, a two-stage NAS approach that trains a high-quality ViT supernet over a very large search space that supports a wide range of mobile devices, and then searches an optimal sub-network (subnet) for direct deployment. However, prior supernet training methods that rely on uniform sampling suffer from the gradient conflict issue: the sampled subnets can have vastly different model sizes (e.g., 50M vs. 2G FLOPs), leading to different optimization directions and inferior performance. To address this challenge, we propose two novel sampling techniques: complexity-aware sampling and performance-aware sampling. Complexity-aware sampling limits the FLOPs difference among the subnets sampled across adjacent training steps, while covering different-sized subnets in the search space. Performance-aware sampling further selects subnets that have good accuracy, which can reduce gradient conflicts and improve supernet quality. Our discovered models, ElasticViT models, achieve top-1 accuracy from 67.2% to 80.0% on ImageNet from 60M to 800M FLOPs without extra retraining, outperforming all prior CNNs and ViTs in terms of accuracy and latency. Our tiny and small models are also the first ViT models that surpass state-of-the-art CNNs with significantly lower latency on mobile devices. For instance, ElasticViT-S1 runs 2.62x faster than EfficientNet-B0 with 0.1% higher accuracy.
SpaceEvo: Hardware-Friendly Search Space Design for Efficient INT8 Inference
Mar 15, 2023The combination of Neural Architecture Search (NAS) and quantization has proven successful in automatically designing low-FLOPs INT8 quantized neural networks (QNN). However, directly applying NAS to design accurate QNN models that achieve low latency on real-world devices leads to inferior performance. In this work, we find that the poor INT8 latency is due to the quantization-unfriendly issue: the operator and configuration (e.g., channel width) choices in prior art search spaces lead to diverse quantization efficiency and can slow down the INT8 inference speed. To address this challenge, we propose SpaceEvo, an automatic method for designing a dedicated, quantization-friendly search space for each target hardware. The key idea of SpaceEvo is to automatically search hardware-preferred operators and configurations to construct the search space, guided by a metric called Q-T score to quantify how quantization-friendly a candidate search space is. We further train a quantized-for-all supernet over our discovered search space, enabling the searched models to be directly deployed without extra retraining or quantization. Our discovered models establish new SOTA INT8 quantized accuracy under various latency constraints, achieving up to 10.1% accuracy improvement on ImageNet than prior art CNNs under the same latency. Extensive experiments on diverse edge devices demonstrate that SpaceEvo consistently outperforms existing manually-designed search spaces with up to 2.5x faster speed while achieving the same accuracy.