 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTex3D: Objects as Attack Surfaces via Adversarial 3D Textures for Vision-Language-Action Models
Apr 02, 2026Vision-language-action (VLA) models have shown strong performance in robotic manipulation, yet their robustness to physically realizable adversarial attacks remains underexplored. Existing studies reveal vulnerabilities through language perturbations and 2D visual attacks, but these attack surfaces are either less representative of real deployment or limited in physical realism. In contrast, adversarial 3D textures pose a more physically plausible and damaging threat, as they are naturally attached to manipulated objects and are easier to deploy in physical environments. Bringing adversarial 3D textures to VLA systems is nevertheless nontrivial. A central obstacle is that standard 3D simulators do not provide a differentiable optimization path from the VLA objective function back to object appearance, making it difficult to optimize through an end-to-end manner. To address this, we introduce Foreground-Background Decoupling (FBD), which enables differentiable texture optimization through dual-renderer alignment while preserving the original simulation environment. To further ensure that the attack remains effective across long-horizon and diverse viewpoints in the physical world, we propose Trajectory-Aware Adversarial Optimization (TAAO), which prioritizes behaviorally critical frames and stabilizes optimization with a vertex-based parameterization. Built on these designs, we present Tex3D, the first framework for end-to-end optimization of 3D adversarial textures directly within the VLA simulation environment. Experiments in both simulation and real-robot settings show that Tex3D significantly degrades VLA performance across multiple manipulation tasks, achieving task failure rates of up to 96.7\%. Our empirical results expose critical vulnerabilities of VLA systems to physically grounded 3D adversarial attacks and highlight the need for robustness-aware training.
WoVR: World Models as Reliable Simulators for Post-Training VLA Policies with RL
Feb 15, 2026Reinforcement learning (RL) promises to unlock capabilities beyond imitation learning for Vision-Language-Action (VLA) models, but its requirement for massive real-world interaction prevents direct deployment on physical robots. Recent work attempts to use learned world models as simulators for policy optimization, yet closed-loop imagined rollouts inevitably suffer from hallucination and long-horizon error accumulation. Such errors do not merely degrade visual fidelity; they corrupt the optimization signal, encouraging policies to exploit model inaccuracies rather than genuine task progress. We propose WoVR, a reliable world-model-based reinforcement learning framework for post-training VLA policies. Instead of assuming a faithful world model, WoVR explicitly regulates how RL interacts with imperfect imagined dynamics. It improves rollout stability through a controllable action-conditioned video world model, reshapes imagined interaction to reduce effective error depth via Keyframe-Initialized Rollouts, and maintains policy-simulator alignment through World Model-Policy co-evolution. Extensive experiments on LIBERO benchmarks and real-world robotic manipulation demonstrate that WoVR enables stable long-horizon imagined rollouts and effective policy optimization, improving average LIBERO success from 39.95% to 69.2% (+29.3 points) and real-robot success from 61.7% to 91.7% (+30.0 points). These results show that learned world models can serve as practical simulators for reinforcement learning when hallucination is explicitly controlled.
RLinf: Flexible and Efficient Large-scale Reinforcement Learning via Macro-to-Micro Flow Transformation
Sep 19, 2025
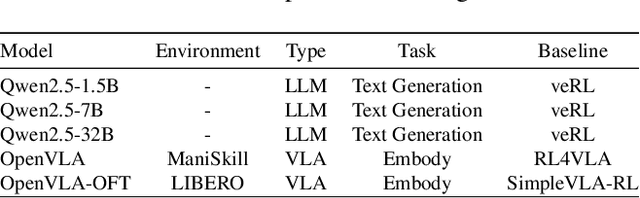

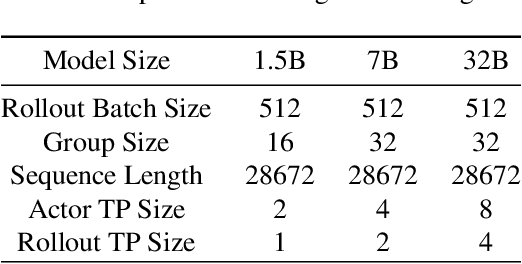
Reinforcement learning (RL) has demonstrated immense potential in advancing artificial general intelligence, agentic intelligence, and embodied intelligence. However, the inherent heterogeneity and dynamicity of RL workflows often lead to low hardware utilization and slow training on existing systems. In this paper, we present RLinf, a high-performance RL training system based on our key observation that the major roadblock to efficient RL training lies in system flexibility. To maximize flexibility and efficiency, RLinf is built atop a novel RL system design paradigm called macro-to-micro flow transformation (M2Flow), which automatically breaks down high-level, easy-to-compose RL workflows at both the temporal and spatial dimensions, and recomposes them into optimized execution flows. Supported by RLinf worker's adaptive communication capability, we devise context switching and elastic pipelining to realize M2Flow transformation, and a profiling-guided scheduling policy to generate optimal execution plans. Extensive evaluations on both reasoning RL and embodied RL tasks demonstrate that RLinf consistently outperforms state-of-the-art systems, achieving 1.1x-2.13x speedup in end-to-end training throughput.
ACMo: Attribute Controllable Motion Generation
Mar 14, 2025Attributes such as style, fine-grained text, and trajectory are specific conditions for describing motion. However, existing methods often lack precise user control over motion attributes and suffer from limited generalizability to unseen motions. This work introduces an Attribute Controllable Motion generation architecture, to address these challenges via decouple any conditions and control them separately. Firstly, we explored the Attribute Diffusion Model to imporve text-to-motion performance via decouple text and motion learning, as the controllable model relies heavily on the pre-trained model. Then, we introduce Motion Adpater to quickly finetune previously unseen motion patterns. Its motion prompts inputs achieve multimodal text-to-motion generation that captures user-specified styles. Finally, we propose a LLM Planner to bridge the gap between unseen attributes and dataset-specific texts via local knowledage for user-friendly interaction. Our approach introduces the capability for motion prompts for stylize generation, enabling fine-grained and user-friendly attribute control while providing performance comparable to state-of-the-art methods. Project page: https://mjwei3d.github.io/ACMo/