 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeENPIRE: Agentic Robot Policy Self-Improvement in the Real World
Jun 18, 2026Achieving dexterous robotic manipulation in the real world heavily relies on human supervision and algorithm engineering, which becomes a central bottleneck in the pursuit of general physical intelligence. Although emerging coding agents can generate code to automate algorithm search, their successes remain largely confined in digital environments. We conjecture that the missing abstraction to automate robotics research is a repeatable feedback loop for real-world policy improvement: reset the scene, execute a policy, verify the outcome, and refine the next iteration. To bridge this gap, we introduce ENPIRE, a harness framework for coding agents that instantiates this physical feedback routine with four core modules: an Environment module (EN) for automatic reset and verification, a Policy Improvement module (PI) that launches policy refinement, a Rollout module (R) to evaluate policies with one or multiple physical robots operating in parallel, and an Evolution module (E) in which coding agents analyze logs, consult literature, improve training infrastructure and algorithm code to address failure modes. This closed-loop system transforms real-world manipulation learning into a controllable optimization procedure, minimizing human effort while allowing fair ablations across training recipe and agent variants. Powered by ENPIRE, frontier coding agents can autonomously train a policy to achieve a 99% success rate on challenging, dexterous manipulation tasks, such as organizing a pin box, fastening a zip tie, and tool use, a process that further accelerates when we dispatch an agent team on a robot fleet. Our results suggest a practical and scalable path toward deploying coding agents to autonomously advancing robotics in the physical world.
Beyond Imitation: Reinforcement Learning-Based Sim-Real Co-Training for VLA Models
Feb 16, 2026Simulation offers a scalable and low-cost way to enrich vision-language-action (VLA) training, reducing reliance on expensive real-robot demonstrations. However, most sim-real co-training methods rely on supervised fine-tuning (SFT), which treats simulation as a static source of demonstrations and does not exploit large-scale closed-loop interaction. Consequently, real-world gains and generalization are often limited. In this paper, we propose an \underline{\textit{RL}}-based sim-real \underline{\textit{Co}}-training \modify{(RL-Co)} framework that leverages interactive simulation while preserving real-world capabilities. Our method follows a generic two-stage design: we first warm-start the policy with SFT on a mixture of real and simulated demonstrations, then fine-tune it with reinforcement learning in simulation while adding an auxiliary supervised loss on real-world data to anchor the policy and mitigate catastrophic forgetting. We evaluate our framework on four real-world tabletop manipulation tasks using two representative VLA architectures, OpenVLA and $π_{0.5}$, and observe consistent improvements over real-only fine-tuning and SFT-based co-training, including +24% real-world success on OpenVLA and +20% on $π_{0.5}$. Beyond higher success rates, RL co-training yields stronger generalization to unseen task variations and substantially improved real-world data efficiency, providing a practical and scalable pathway for leveraging simulation to enhance real-robot deployment.
BFM-Zero: A Promptable Behavioral Foundation Model for Humanoid Control Using Unsupervised Reinforcement Learning
Nov 06, 2025Building Behavioral Foundation Models (BFMs) for humanoid robots has the potential to unify diverse control tasks under a single, promptable generalist policy. However, existing approaches are either exclusively deployed on simulated humanoid characters, or specialized to specific tasks such as tracking. We propose BFM-Zero, a framework that learns an effective shared latent representation that embeds motions, goals, and rewards into a common space, enabling a single policy to be prompted for multiple downstream tasks without retraining. This well-structured latent space in BFM-Zero enables versatile and robust whole-body skills on a Unitree G1 humanoid in the real world, via diverse inference methods, including zero-shot motion tracking, goal reaching, and reward optimization, and few-shot optimization-based adaptation. Unlike prior on-policy reinforcement learning (RL) frameworks, BFM-Zero builds upon recent advancements in unsupervised RL and Forward-Backward (FB) models, which offer an objective-centric, explainable, and smooth latent representation of whole-body motions. We further extend BFM-Zero with critical reward shaping, domain randomization, and history-dependent asymmetric learning to bridge the sim-to-real gap. Those key design choices are quantitatively ablated in simulation. A first-of-its-kind model, BFM-Zero establishes a step toward scalable, promptable behavioral foundation models for whole-body humanoid control.
$π_\texttt{RL}$: Online RL Fine-tuning for Flow-based Vision-Language-Action Models
Oct 29, 2025


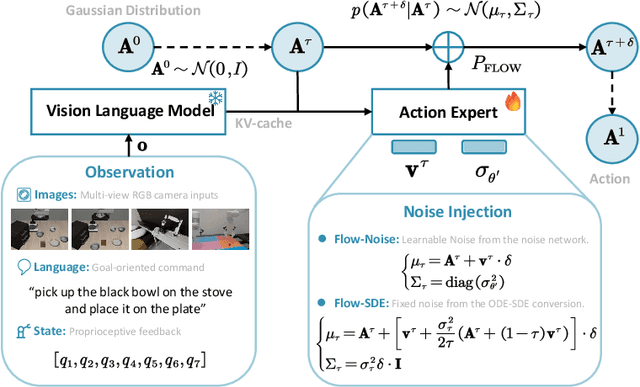
Vision-Language-Action (VLA) models enable robots to understand and perform complex tasks from multimodal input. Although recent work explores using reinforcement learning (RL) to automate the laborious data collection process in scaling supervised fine-tuning (SFT), applying large-scale RL to flow-based VLAs (e.g., $\pi_0$, $\pi_{0.5}$) remains challenging due to intractable action log-likelihoods from iterative denoising. We address this challenge with $\pi_{\text{RL}}$, an open-source framework for training flow-based VLAs in parallel simulation. $\pi_{\text{RL}}$ implements two RL algorithms: (1) {Flow-Noise} models the denoising process as a discrete-time MDP with a learnable noise network for exact log-likelihood computation. (2) {Flow-SDE} integrates denoising with agent-environment interaction, formulating a two-layer MDP that employs ODE-to-SDE conversion for efficient RL exploration. We evaluate $\pi_{\text{RL}}$ on LIBERO and ManiSkill benchmarks. On LIBERO, $\pi_{\text{RL}}$ boosts few-shot SFT models $\pi_0$ and $\pi_{0.5}$ from 57.6% to 97.6% and from 77.1% to 98.3%, respectively. In ManiSkill, we train $\pi_{\text{RL}}$ in 320 parallel environments, improving $\pi_0$ from 41.6% to 85.7% and $\pi_{0.5}$ from 40.0% to 84.8% across 4352 pick-and-place tasks, demonstrating scalable multitask RL under heterogeneous simulation. Overall, $\pi_{\text{RL}}$ achieves significant performance gains and stronger generalization over SFT-models, validating the effectiveness of online RL for flow-based VLAs.
ReinFlow: Fine-tuning Flow Matching Policy with Online Reinforcement Learning
May 29, 2025



We propose ReinFlow, a simple yet effective online reinforcement learning (RL) framework that fine-tunes a family of flow matching policies for continuous robotic control. Derived from rigorous RL theory, ReinFlow injects learnable noise into a flow policy's deterministic path, converting the flow into a discrete-time Markov Process for exact and straightforward likelihood computation. This conversion facilitates exploration and ensures training stability, enabling ReinFlow to fine-tune diverse flow model variants, including Rectified Flow [35] and Shortcut Models [19], particularly at very few or even one denoising step. We benchmark ReinFlow in representative locomotion and manipulation tasks, including long-horizon planning with visual input and sparse reward. The episode reward of Rectified Flow policies obtained an average net growth of 135.36% after fine-tuning in challenging legged locomotion tasks while saving denoising steps and 82.63% of wall time compared to state-of-the-art diffusion RL fine-tuning method DPPO [43]. The success rate of the Shortcut Model policies in state and visual manipulation tasks achieved an average net increase of 40.34% after fine-tuning with ReinFlow at four or even one denoising step, whose performance is comparable to fine-tuned DDIM policies while saving computation time for an average of 23.20%. Project webpage: https://reinflow.github.io/
Think on your feet: Seamless Transition between Human-like Locomotion in Response to Changing Commands
Feb 26, 2025



While it is relatively easier to train humanoid robots to mimic specific locomotion skills, it is more challenging to learn from various motions and adhere to continuously changing commands. These robots must accurately track motion instructions, seamlessly transition between a variety of movements, and master intermediate motions not present in their reference data. In this work, we propose a novel approach that integrates human-like motion transfer with precise velocity tracking by a series of improvements to classical imitation learning. To enhance generalization, we employ the Wasserstein divergence criterion (WGAN-div). Furthermore, a Hybrid Internal Model provides structured estimates of hidden states and velocity to enhance mobile stability and environment adaptability, while a curiosity bonus fosters exploration. Our comprehensive method promises highly human-like locomotion that adapts to varying velocity requirements, direct generalization to unseen motions and multitasking, as well as zero-shot transfer to the simulator and the real world across different terrains. These advancements are validated through simulations across various robot models and extensive real-world experiments.
Provably Efficient Partially Observable Risk-Sensitive Reinforcement Learning with Hindsight Observation
Feb 28, 2024This work pioneers regret analysis of risk-sensitive reinforcement learning in partially observable environments with hindsight observation, addressing a gap in theoretical exploration. We introduce a novel formulation that integrates hindsight observations into a Partially Observable Markov Decision Process (POMDP) framework, where the goal is to optimize accumulated reward under the entropic risk measure. We develop the first provably efficient RL algorithm tailored for this setting. We also prove by rigorous analysis that our algorithm achieves polynomial regret $\tilde{O}\left(\frac{e^{|{\gamma}|H}-1}{|{\gamma}|H}H^2\sqrt{KHS^2OA}\right)$, which outperforms or matches existing upper bounds when the model degenerates to risk-neutral or fully observable settings. We adopt the method of change-of-measure and develop a novel analytical tool of beta vectors to streamline mathematical derivations. These techniques are of particular interest to the theoretical study of reinforcement learning.