 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Imitation: Reinforcement Learning-Based Sim-Real Co-Training for VLA Models
Feb 16, 2026Simulation offers a scalable and low-cost way to enrich vision-language-action (VLA) training, reducing reliance on expensive real-robot demonstrations. However, most sim-real co-training methods rely on supervised fine-tuning (SFT), which treats simulation as a static source of demonstrations and does not exploit large-scale closed-loop interaction. Consequently, real-world gains and generalization are often limited. In this paper, we propose an \underline{\textit{RL}}-based sim-real \underline{\textit{Co}}-training \modify{(RL-Co)} framework that leverages interactive simulation while preserving real-world capabilities. Our method follows a generic two-stage design: we first warm-start the policy with SFT on a mixture of real and simulated demonstrations, then fine-tune it with reinforcement learning in simulation while adding an auxiliary supervised loss on real-world data to anchor the policy and mitigate catastrophic forgetting. We evaluate our framework on four real-world tabletop manipulation tasks using two representative VLA architectures, OpenVLA and $π_{0.5}$, and observe consistent improvements over real-only fine-tuning and SFT-based co-training, including +24% real-world success on OpenVLA and +20% on $π_{0.5}$. Beyond higher success rates, RL co-training yields stronger generalization to unseen task variations and substantially improved real-world data efficiency, providing a practical and scalable pathway for leveraging simulation to enhance real-robot deployment.
RLinf-USER: A Unified and Extensible System for Real-World Online Policy Learning in Embodied AI
Feb 08, 2026Online policy learning directly in the physical world is a promising yet challenging direction for embodied intelligence. Unlike simulation, real-world systems cannot be arbitrarily accelerated, cheaply reset, or massively replicated, which makes scalable data collection, heterogeneous deployment, and long-horizon effective training difficult. These challenges suggest that real-world policy learning is not only an algorithmic issue but fundamentally a systems problem. We present USER, a Unified and extensible SystEm for Real-world online policy learning. USER treats physical robots as first-class hardware resources alongside GPUs through a unified hardware abstraction layer, enabling automatic discovery, management, and scheduling of heterogeneous robots. To address cloud-edge communication, USER introduces an adaptive communication plane with tunneling-based networking, distributed data channels for traffic localization, and streaming-multiprocessor-aware weight synchronization to regulate GPU-side overhead. On top of this infrastructure, USER organizes learning as a fully asynchronous framework with a persistent, cache-aware buffer, enabling efficient long-horizon experiments with robust crash recovery and reuse of historical data. In addition, USER provides extensible abstractions for rewards, algorithms, and policies, supporting online imitation or reinforcement learning of CNN/MLP, generative policies, and large vision-language-action (VLA) models within a unified pipeline. Results in both simulation and the real world show that USER enables multi-robot coordination, heterogeneous manipulators, edge-cloud collaboration with large models, and long-running asynchronous training, offering a unified and extensible systems foundation for real-world online policy learning.
$π_\texttt{RL}$: Online RL Fine-tuning for Flow-based Vision-Language-Action Models
Oct 29, 2025


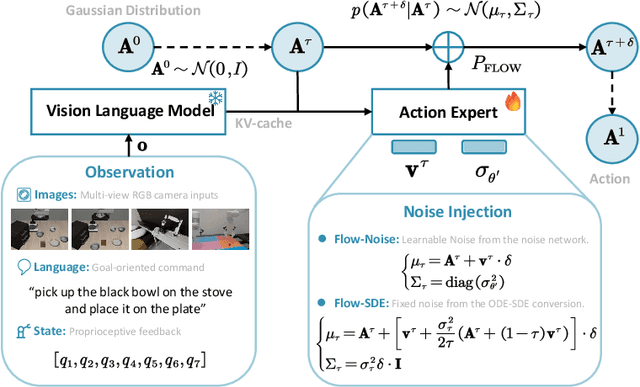
Vision-Language-Action (VLA) models enable robots to understand and perform complex tasks from multimodal input. Although recent work explores using reinforcement learning (RL) to automate the laborious data collection process in scaling supervised fine-tuning (SFT), applying large-scale RL to flow-based VLAs (e.g., $\pi_0$, $\pi_{0.5}$) remains challenging due to intractable action log-likelihoods from iterative denoising. We address this challenge with $\pi_{\text{RL}}$, an open-source framework for training flow-based VLAs in parallel simulation. $\pi_{\text{RL}}$ implements two RL algorithms: (1) {Flow-Noise} models the denoising process as a discrete-time MDP with a learnable noise network for exact log-likelihood computation. (2) {Flow-SDE} integrates denoising with agent-environment interaction, formulating a two-layer MDP that employs ODE-to-SDE conversion for efficient RL exploration. We evaluate $\pi_{\text{RL}}$ on LIBERO and ManiSkill benchmarks. On LIBERO, $\pi_{\text{RL}}$ boosts few-shot SFT models $\pi_0$ and $\pi_{0.5}$ from 57.6% to 97.6% and from 77.1% to 98.3%, respectively. In ManiSkill, we train $\pi_{\text{RL}}$ in 320 parallel environments, improving $\pi_0$ from 41.6% to 85.7% and $\pi_{0.5}$ from 40.0% to 84.8% across 4352 pick-and-place tasks, demonstrating scalable multitask RL under heterogeneous simulation. Overall, $\pi_{\text{RL}}$ achieves significant performance gains and stronger generalization over SFT-models, validating the effectiveness of online RL for flow-based VLAs.
RLinf: Flexible and Efficient Large-scale Reinforcement Learning via Macro-to-Micro Flow Transformation
Sep 19, 2025

Reinforcement learning (RL) has demonstrated immense potential in advancing artificial general intelligence, agentic intelligence, and embodied intelligence. However, the inherent heterogeneity and dynamicity of RL workflows often lead to low hardware utilization and slow training on existing systems. In this paper, we present RLinf, a high-performance RL training system based on our key observation that the major roadblock to efficient RL training lies in system flexibility. To maximize flexibility and efficiency, RLinf is built atop a novel RL system design paradigm called macro-to-micro flow transformation (M2Flow), which automatically breaks down high-level, easy-to-compose RL workflows at both the temporal and spatial dimensions, and recomposes them into optimized execution flows. Supported by RLinf worker's adaptive communication capability, we devise context switching and elastic pipelining to realize M2Flow transformation, and a profiling-guided scheduling policy to generate optimal execution plans. Extensive evaluations on both reasoning RL and embodied RL tasks demonstrate that RLinf consistently outperforms state-of-the-art systems, achieving 1.1x-2.13x speedup in end-to-end training throughput.
Multi-UAV Behavior-based Formation with Static and Dynamic Obstacles Avoidance via Reinforcement Learning
Oct 24, 2024



Formation control of multiple Unmanned Aerial Vehicles (UAVs) is vital for practical applications. This paper tackles the task of behavior-based UAV formation while avoiding static and dynamic obstacles during directed flight. We present a two-stage reinforcement learning (RL) training pipeline to tackle the challenge of multi-objective optimization, large exploration spaces, and the sim-to-real gap. The first stage searches in a simplified scenario for a linear utility function that balances all task objectives simultaneously, whereas the second stage applies the utility function in complex scenarios, utilizing curriculum learning to navigate large exploration spaces. Additionally, we apply an attention-based observation encoder to enhance formation maintenance and manage varying obstacle quantity. Experiments in simulation and real world demonstrate that our method outperforms planning-based and RL-based baselines regarding collision-free rate and formation maintenance in scenarios with static, dynamic, and mixed obstacles.