 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTEAM: Self-Supervised Temporal Ensemble Advantage Modeling for Real-World Robot Learning
Jun 29, 2026Real-world robot learning increasingly relies on heterogeneous data, but demonstrations and rollouts often mix useful progress with stalls, corrections, and suboptimal behavior. Effective policy learning therefore requires frame-level advantages that distinguish reliable local progress from failures and regressions. We propose Self-supervised Temporal Ensemble Advantage Modeling (STEAM), a label-free method that learns such advantages from expert demonstrations. STEAM trains an ensemble of temporal-offset predictors on frame pairs within expert trajectories, using the normalized temporal offset between two frames as a self-supervised signal. Each predictor maps a frame pair to a distribution over temporal offsets, which is converted into a scalar advantage. STEAM then takes the minimum advantage across the ensemble to score mixed-quality rollout data conservatively. Across real-world bimanual towel folding, chip checkout, cola restocking, and single-arm pick-and-place tasks, STEAM identifies stalls, failures, and recoveries. When combined with CFGRL, STEAM further improves policy success rate by 59%, 54.3%, 23% and 16.2% over baselines, respectively.
Ghost Attractor Networks: Basin-Structured Dynamical Decoders for Closed-Loop Sequential Generation
Jun 16, 2026Sequential output generation with large-scale Transformer and diffusion decoders pays a memory cost that grows with sequence length, plus iterative per-step computation. Replacing them with small feed-forward decoders restores efficiency but produces unstructured latent representations that limit closed-loop control: phase-conditioned action generation and cross-step latent carry-over both require a latent geometry with stable basins. This article proposes Ghost Attractor Networks, a theoretically derived dynamical decoder whose latent evolves under a learned potential with drift and produces a basin-attractor structure by construction. Three desiderata (multi-modality, decoder-level single-pass switching, and constant memory) motivate the potential-drift form, and mode transitions arise as saddle-node bifurcations with ghost-attractor escape. A hierarchical phase-space decomposition separates first-order basin convergence from second-order proprioceptive refinement. Empirically, a Ghost trained end-to-end with a behavioral-cloning and contrastive objective exhibits the predicted gradient-flow contraction in its potential, with the gradient norm decaying by 67 percent across five integration steps on 1430 held-out samples. Ghost is evaluated as a robotic action decoder. A 2.3-million-parameter Ghost matches the offline accuracy of a 1.07-billion-parameter Diffusion Transformer at 462 times fewer parameters and 32 times lower latency, and beats five alternative 2M-parameter decoders (MLP, Neural ODE, CVAE, Transformer, 1-step Diffusion) on offline mean squared error by 5.9 to 29 percent. On the LIBERO-10 closed-loop benchmark, phase conditioning on Ghost's basin-structured latent yields a 13.5 percentage-point success-rate gain over a feed-forward MLP baseline, and persistent-latent ensembling reaches a 95.7 percent final success rate.
Agentic Neuro-Symbolic Planning and Commissioning for Human-in-the-Loop Industrial Robotics with Digital Twins
Jun 06, 2026Flexible robotic automation requires systems that interpret operator intent, verify physical feasibility, and recover from execution failures across both the planning and execution stages. This paper proposes an agentic neuro-symbolic framework for human-in-the-loop industrial robotics, in which LLMs are used for tasks that require language understanding or contextual reasoning, while all verification, sequencing, and execution remain deterministic. The framework adapts the Planner-Generator-Evaluator (PGE) harness pattern from software engineering into a Specifier-Designer-Inspector (SDI) architecture for industrial robotics, combined with LangGraph-based dynamic routing for failure recovery. A two-tier recovery mechanism addresses structure-level replanning through context-aware orchestration and execution-level geometric failures through deterministic recovery skills. A Unity3D digital twin supports human inspection, modification, and re-verification prior to physical execution. Evaluated on natural-language commands across multiple difficulty levels against ten baselines, the proposed method achieves the highest task success. Ablation results confirm that structured command expansion, symbolic verification, selective LLM routing, and recovery skills are each individually necessary.
Vision-Guided Dual-Arm Humanoid Robotic Disassembly of End-of-Life 18650 Lithium-ion Battery Packs
Jun 06, 2026The growing volume of retired lithium-ion battery packs from electric vehicles and portable electronics calls for automated disassembly that is safe, flexible, and selective down to the individual cell. Existing robotic systems, however, mostly assume known pack poses, external fixtures, or specialised tooling, leaving fixture-free cell-level disassembly under pose uncertainty largely unsolved. This paper presents a vision-guided dual-arm pipeline that disassembles a 21-cell 18650 pack from an arbitrary initial pose using only general-purpose parallel-jaw grippers, RGB-D sensing, and a pre-trained grasp detector. Pose uncertainty is absorbed by a learn-and-filter perception stack with discrete look-and-move wrist-camera corrections, while a mid-task support transfer between the two arms extends the effective workspace without any external clamp. The pipeline achieves an 8/10 end-to-end success rate, a cell-localisation root-mean-square error of $2.4$\,mm, and a mean cycle time of 6.0\,minutes per pack, providing a practical, fixture-free building block for industrial battery recycling.
Aligned but Fragile: Enhancing LLM Safety Robustness via Zeroth-Order Optimization
May 28, 2026Safety alignment for large language models (LLMs) aims to reduce harmful or unsafe behavior while preserving general utility. However, recent findings reveal that alignment effects can be fragile: lightweight post-alignment manipulations, such as parameter noise, activation noise, or quantization, can easily weaken the intended safety behavior. Prior efforts to improve robustness have primarily focused on data curation, modified alignment objectives, and safety-critical parameter identification, leaving the role of the optimizer itself largely unexplored. In this paper, we are the first to study the robustness of safety alignment from the perspective of the base optimizer. This optimizer-centric view naturally points to zeroth-order optimization, which provides a robustness-oriented signal by evaluating safety alignment under perturbations. Based on this insight, we propose a hybrid framework that first performs standard first-order safety alignment and then applies zeroth-order refinement to improve robustness. Both theoretically and empirically, we show that only a few zeroth-order refinement steps can enhance robustness while preserving safety alignment. We further improve the efficiency of zeroth-order refinement by exploiting its inherent perturbation-based evaluations to estimate layer-wise robustness sensitivity, enabling the refinement process to concentrate updates on robustness-critical layers with modest training overhead.
Automotive Engineering-Centric Agentic AI Workflow Framework
Apr 09, 2026Engineering workflows such as design optimization, simulation-based diagnosis, control tuning, and model-based systems engineering (MBSE) are iterative, constraint-driven, and shaped by prior decisions. Yet many AI methods still treat these activities as isolated tasks rather than as parts of a broader workflow. This paper presents Agentic Engineering Intelligence (AEI), an industrial vision framework that models engineering workflows as constrained, history-aware sequential decision processes in which AI agents support engineer-supervised interventions over engineering toolchains. AEI links an offline phase for engineering data processing and workflow-memory construction with an online phase for workflow-state estimation, retrieval, and decision support. A control-theoretic interpretation is also possible, in which engineering objectives act as reference signals, agents act as workflow controllers, and toolchains provide feedback for intervention selection. Representative automotive use cases in suspension design, reinforcement learning tuning, multimodal engineering knowledge reuse, aerodynamic exploration, and MBSE show how diverse workflows can be expressed within a common formulation. Overall, the paper positions engineering AI as a problem of process-level intelligence and outlines a practical roadmap for future empirical validation in industrial settings.
Toward Generalizable Graph Learning for 3D Engineering AI: Explainable Workflows for CAE Mode Shape Classification and CFD Field Prediction
Apr 09, 2026Automotive engineering development increasingly relies on heterogeneous 3D data, including finite element (FE) models, body-in-white (BiW) representations, CAD geometry, and CFD meshes. At the same time, engineering teams face growing pressure to shorten development cycles, improve performance and accelerate innovation. Although artificial intelligence (AI) is increasingly explored in this domain, many current methods remain task-specific, difficult to interpret, and hard to reuse across development stages. This paper presents a practical graph learning framework for 3D engineering AI, in which heterogeneous engineering assets are converted into physics-aware graph representations and processed by Graph Neural Networks (GNNs). The framework is designed to support both classification and prediction tasks. The framework is validated on two automotive applications: CAE vibration mode shape classification and CFD aerodynamic field prediction. For CAE vibration mode classification, a region-aware BiW graph supports explainable mode classification across vehicle and FE variants under label scarcity. For CFD aerodynamic field prediction, a physics-informed surrogate predicts pressure and wall shear stress (WSS) across aerodynamic body shape variants, while symmetry preserving down sampling retains accuracy with lower computational cost. The framework also outlines data generation guidance that can help engineers identify which additional simulations or labels are valuable to collect next. These results demonstrate a practical and reusable engineering AI workflow for more trustworthy CAE and CFD decision support.
$π_\texttt{RL}$: Online RL Fine-tuning for Flow-based Vision-Language-Action Models
Oct 29, 2025


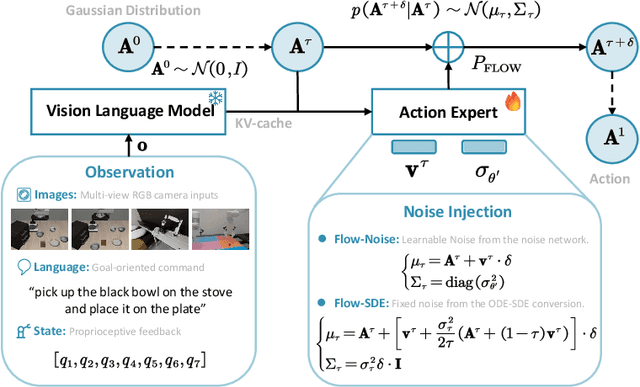
Vision-Language-Action (VLA) models enable robots to understand and perform complex tasks from multimodal input. Although recent work explores using reinforcement learning (RL) to automate the laborious data collection process in scaling supervised fine-tuning (SFT), applying large-scale RL to flow-based VLAs (e.g., $\pi_0$, $\pi_{0.5}$) remains challenging due to intractable action log-likelihoods from iterative denoising. We address this challenge with $\pi_{\text{RL}}$, an open-source framework for training flow-based VLAs in parallel simulation. $\pi_{\text{RL}}$ implements two RL algorithms: (1) {Flow-Noise} models the denoising process as a discrete-time MDP with a learnable noise network for exact log-likelihood computation. (2) {Flow-SDE} integrates denoising with agent-environment interaction, formulating a two-layer MDP that employs ODE-to-SDE conversion for efficient RL exploration. We evaluate $\pi_{\text{RL}}$ on LIBERO and ManiSkill benchmarks. On LIBERO, $\pi_{\text{RL}}$ boosts few-shot SFT models $\pi_0$ and $\pi_{0.5}$ from 57.6% to 97.6% and from 77.1% to 98.3%, respectively. In ManiSkill, we train $\pi_{\text{RL}}$ in 320 parallel environments, improving $\pi_0$ from 41.6% to 85.7% and $\pi_{0.5}$ from 40.0% to 84.8% across 4352 pick-and-place tasks, demonstrating scalable multitask RL under heterogeneous simulation. Overall, $\pi_{\text{RL}}$ achieves significant performance gains and stronger generalization over SFT-models, validating the effectiveness of online RL for flow-based VLAs.
RLinf: Flexible and Efficient Large-scale Reinforcement Learning via Macro-to-Micro Flow Transformation
Sep 19, 2025

Reinforcement learning (RL) has demonstrated immense potential in advancing artificial general intelligence, agentic intelligence, and embodied intelligence. However, the inherent heterogeneity and dynamicity of RL workflows often lead to low hardware utilization and slow training on existing systems. In this paper, we present RLinf, a high-performance RL training system based on our key observation that the major roadblock to efficient RL training lies in system flexibility. To maximize flexibility and efficiency, RLinf is built atop a novel RL system design paradigm called macro-to-micro flow transformation (M2Flow), which automatically breaks down high-level, easy-to-compose RL workflows at both the temporal and spatial dimensions, and recomposes them into optimized execution flows. Supported by RLinf worker's adaptive communication capability, we devise context switching and elastic pipelining to realize M2Flow transformation, and a profiling-guided scheduling policy to generate optimal execution plans. Extensive evaluations on both reasoning RL and embodied RL tasks demonstrate that RLinf consistently outperforms state-of-the-art systems, achieving 1.1x-2.13x speedup in end-to-end training throughput.
Module-Aware Parameter-Efficient Machine Unlearning on Transformers
Aug 24, 2025Transformer has become fundamental to a vast series of pre-trained large models that have achieved remarkable success across diverse applications. Machine unlearning, which focuses on efficiently removing specific data influences to comply with privacy regulations, shows promise in restricting updates to influence-critical parameters. However, existing parameter-efficient unlearning methods are largely devised in a module-oblivious manner, which tends to inaccurately identify these parameters and leads to inferior unlearning performance for Transformers. In this paper, we propose {\tt MAPE-Unlearn}, a module-aware parameter-efficient machine unlearning approach that uses a learnable pair of masks to pinpoint influence-critical parameters in the heads and filters of Transformers. The learning objective of these masks is derived by desiderata of unlearning and optimized through an efficient algorithm featured by a greedy search with a warm start. Extensive experiments on various Transformer models and datasets demonstrate the effectiveness and robustness of {\tt MAPE-Unlearn} for unlearning.