 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$π_\texttt{RL}$: Online RL Fine-tuning for Flow-based Vision-Language-Action Models
Oct 29, 2025


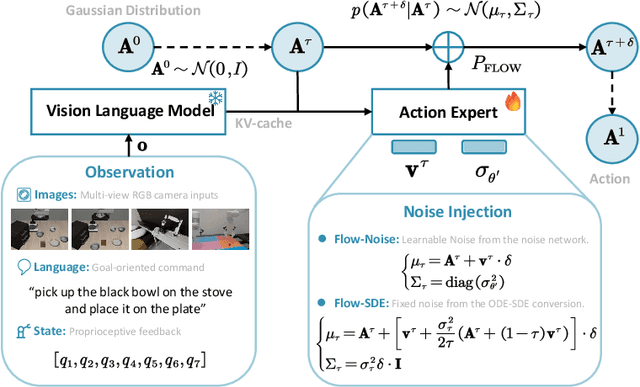
Vision-Language-Action (VLA) models enable robots to understand and perform complex tasks from multimodal input. Although recent work explores using reinforcement learning (RL) to automate the laborious data collection process in scaling supervised fine-tuning (SFT), applying large-scale RL to flow-based VLAs (e.g., $\pi_0$, $\pi_{0.5}$) remains challenging due to intractable action log-likelihoods from iterative denoising. We address this challenge with $\pi_{\text{RL}}$, an open-source framework for training flow-based VLAs in parallel simulation. $\pi_{\text{RL}}$ implements two RL algorithms: (1) {Flow-Noise} models the denoising process as a discrete-time MDP with a learnable noise network for exact log-likelihood computation. (2) {Flow-SDE} integrates denoising with agent-environment interaction, formulating a two-layer MDP that employs ODE-to-SDE conversion for efficient RL exploration. We evaluate $\pi_{\text{RL}}$ on LIBERO and ManiSkill benchmarks. On LIBERO, $\pi_{\text{RL}}$ boosts few-shot SFT models $\pi_0$ and $\pi_{0.5}$ from 57.6% to 97.6% and from 77.1% to 98.3%, respectively. In ManiSkill, we train $\pi_{\text{RL}}$ in 320 parallel environments, improving $\pi_0$ from 41.6% to 85.7% and $\pi_{0.5}$ from 40.0% to 84.8% across 4352 pick-and-place tasks, demonstrating scalable multitask RL under heterogeneous simulation. Overall, $\pi_{\text{RL}}$ achieves significant performance gains and stronger generalization over SFT-models, validating the effectiveness of online RL for flow-based VLAs.
RLinf: Flexible and Efficient Large-scale Reinforcement Learning via Macro-to-Micro Flow Transformation
Sep 19, 2025
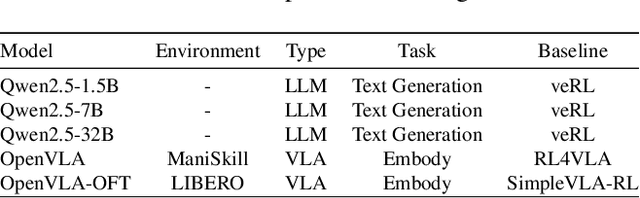

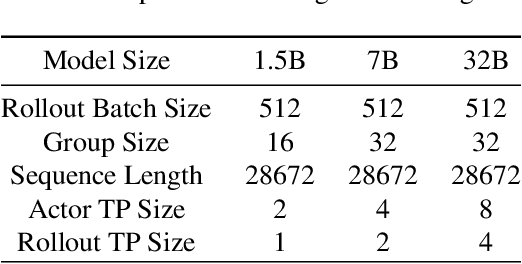
Reinforcement learning (RL) has demonstrated immense potential in advancing artificial general intelligence, agentic intelligence, and embodied intelligence. However, the inherent heterogeneity and dynamicity of RL workflows often lead to low hardware utilization and slow training on existing systems. In this paper, we present RLinf, a high-performance RL training system based on our key observation that the major roadblock to efficient RL training lies in system flexibility. To maximize flexibility and efficiency, RLinf is built atop a novel RL system design paradigm called macro-to-micro flow transformation (M2Flow), which automatically breaks down high-level, easy-to-compose RL workflows at both the temporal and spatial dimensions, and recomposes them into optimized execution flows. Supported by RLinf worker's adaptive communication capability, we devise context switching and elastic pipelining to realize M2Flow transformation, and a profiling-guided scheduling policy to generate optimal execution plans. Extensive evaluations on both reasoning RL and embodied RL tasks demonstrate that RLinf consistently outperforms state-of-the-art systems, achieving 1.1x-2.13x speedup in end-to-end training throughput.
HetHub: A Heterogeneous distributed hybrid training system for large-scale models
May 25, 2024The development of large-scale models relies on a vast number of computing resources. For example, the GPT-4 model (1.8 trillion parameters) requires 25000 A100 GPUs for its training. It is a challenge to build a large-scale cluster with a type of GPU-accelerator. Using multiple types of GPU-accelerators to construct a cluster is an effective way to solve the problem of insufficient homogeneous GPU-accelerators. However, the existing distributed training systems for large-scale models only support homogeneous GPU-accelerators, not heterogeneous GPU-accelerators. To address the problem, this paper proposes a distributed training system with hybrid parallelism support on heterogeneous GPU-accelerators for large-scale models. It introduces a distributed unified communicator to realize the communication between heterogeneous GPU-accelerators, a distributed performance predictor, and an automatic hybrid parallel module to develop and train models efficiently with heterogeneous GPU-accelerators. Compared to the distributed training system with homogeneous GPU-accelerators, our system can support six different combinations of heterogeneous GPU-accelerators and the optimal performance of heterogeneous GPU-accelerators has achieved at least 90% of the theoretical upper bound performance of homogeneous GPU-accelerators.