 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-Aware Token Importance Estimation in Spiking Transformers
May 10, 2026Spiking transformers have shown strong potential for neuromorphic vision, yet their token processing across multiple spiking steps still introduces substantial redundancy and inference cost. Existing token reduction methods mainly rely on response based cues, such as activation magnitude, firing statistics, or feature similarity. Although effective, these criteria do not explicitly characterize token importance from the perspective of temporally evolving class evidence. In spiking transformers, token representations are progressively formed across multiple spiking steps rather than determined at a single instant, suggesting that token importance should be evaluated not only by instantaneous responses but also by temporal uncertainty patterns. Our key observation is that tokens exhibit heterogeneous uncertainty trajectories over time, and that their temporally aggregated uncertainty statistics provide an effective cue for distinguishing informative tokens from redundant ones. Motivated by this, we propose Uncert, a training free and plug and play token importance estimation framework for spiking transformers. Specifically, Uncert models token wise class evidence with a Dirichlet distribution and summarizes each token temporal uncertainty using its mean and fluctuation across spiking steps, yielding an uncertainty aware importance score for token reduction during inference. Experiments on both static and neuromorphic benchmarks show that Uncert achieves favorable accuracy and efficiency tradeoffs, with the most consistent gains observed under token pruning. Further analysis reveals a clear empirical connection between temporal uncertainty patterns and token contribution, offering new insights into token dynamics in spiking transformers.
High-Speed Full-Color HDR Imaging via Unwrapping Modulo-Encoded Spike Streams
Apr 16, 2026Conventional RGB-based high dynamic range (HDR) imaging faces a fundamental trade-off between motion artifacts in multi-exposure captures and irreversible information loss in single-shot techniques. Modulo sensors offer a promising alternative by encoding theoretically unbounded dynamic range into wrapped measurements. However, existing modulo solutions remain bottlenecked by iterative unwrapping overhead and hardware constraints limiting them to low-speed, grayscale capture. In this work, we present a complete modulo-based HDR imaging system that enables high-speed, full-color HDR acquisition by synergistically advancing both the sensing formulation and the unwrapping algorithm. At the core of our approach is an exposure-decoupled formulation of modulo imaging that allows multiple measurements to be interleaved in time, preserving a clean, observation-wise measurement model. Building upon this, we introduce an iteration-free unwrapping algorithm that integrates diffusion-based generative priors with the physical least absolute remainder property of modulo images, supporting highly efficient, physics-consistent HDR reconstruction. Finally, to validate the practical viability of our system, we demonstrate a proof-of-concept hardware implementation based on modulo-encoded spike streams. This setup preserves the native high temporal resolution of spike cameras, achieving 1000 FPS full-color imaging while reducing output data bandwidth from approximately 20 Gbps to 6 Gbps. Extensive evaluations indicate that our coordinated approach successfully overcomes key systemic bottlenecks, demonstrating the feasibility of deploying modulo imaging in dynamic scenarios.
Ge$^\text{2}$mS-T: Multi-Dimensional Grouping for Ultra-High Energy Efficiency in Spiking Transformer
Apr 10, 2026Spiking Neural Networks (SNNs) offer superior energy efficiency over Artificial Neural Networks (ANNs). However, they encounter significant deficiencies in training and inference metrics when applied to Spiking Vision Transformers (S-ViTs). Existing paradigms including ANN-SNN Conversion and Spatial-Temporal Backpropagation (STBP) suffer from inherent limitations, precluding concurrent optimization of memory, accuracy and energy consumption. To address these issues, we propose Ge$^\text{2}$mS-T, a novel architecture implementing grouped computation across temporal, spatial and network structure dimensions. Specifically, we introduce the Grouped-Exponential-Coding-based IF (ExpG-IF) model, enabling lossless conversion with constant training overhead and precise regulation for spike patterns. Additionally, we develop Group-wise Spiking Self-Attention (GW-SSA) to reduce computational complexity via multi-scale token grouping and multiplication-free operations within a hybrid attention-convolution framework. Experiments confirm that our method can achieve superior performance with ultra-high energy efficiency on challenging benchmarks. To our best knowledge, this is the first work to systematically establish multi-dimensional grouped computation for resolving the triad of memory overhead, learning capability and energy budget in S-ViTs.
Brain-Inspired Multimodal Spiking Neural Network for Image-Text Retrieval
Mar 25, 2026Spiking neural networks (SNNs) have recently shown strong potential in unimodal visual and textual tasks, yet building a directly trained, low-energy, and high-performance SNN for multimodal applications such as image-text retrieval (ITR) remains highly challenging. Existing artificial neural network (ANN)-based methods often pursue richer unimodal semantics using deeper and more complex architectures, while overlooking cross-modal interaction, retrieval latency, and energy efficiency. To address these limitations, we present a brain-inspired Cross-Modal Spike Fusion network (CMSF) and apply it to ITR for the first time. The proposed spike fusion mechanism integrates unimodal features at the spike level, generating enhanced multimodal representations that act as soft supervisory signals to refine unimodal spike embeddings, effectively mitigating semantic loss within CMSF. Despite requiring only two time steps, CMSF achieves top-tier retrieval accuracy, surpassing state-of-the-art ANN counterparts while maintaining exceptionally low energy consumption and high retrieval speed. This work marks a significant step toward multimodal SNNs, offering a brain-inspired framework that unifies temporal dynamics with cross-modal alignment and provides new insights for future spiking-based multimodal research. The code is available at https://github.com/zxt6174/CMSF.
A Latency Coding Framework for Deep Spiking Neural Networks with Ultra-Low Latency
Mar 24, 2026Spiking neural networks (SNNs) offer a biologically inspired computing paradigm with significant potential for energy-efficient neural processing. Among neural coding schemes of SNNs, Time-To-First-Spike (TTFS) coding, which encodes information through the precise timing of a neuron's first spike, provides exceptional energy efficiency and biological plausibility. Despite its theoretical advantages, existing TTFS models lack efficient training methods, suffering from high inference latency and limited performance. In this work, we present a comprehensive framework, which enables the efficient training of deep TTFS-coded SNNs by employing backpropagation throuh time (BPTT) algorithm. We name the generalized TTFS coding method in our framework as latency coding. The framework includes: (1) a latency encoding (LE) module with feature extraction and straight-through estimators to address severe information loss in direct intensity-to-latency mapping and ensure smooth gradient flow; (2) relaxation of the strict single-spike constraint of traditional TTFS, allowing neurons of intermediate layers to fire multiple times to mitigating gradient vanishing in deep networks; (3) a temporal adaptive decision (TAD) loss function that dynamically weights supervision signals based on sample-dependent confidence, resolving the incompatibility between latency coding and standard cross-entropy loss. Experimental results demonstrate that our method achieves state-of-the-art accuracy in comparison to existing TTFS-coded SNNs with ultra-low inference latency and superior energy efficiency. The framework also demonstrates improved robustness against input corruptions. Our study investigates the characteristics and potential of latency coding in scenarios demanding rapid response, providing valuable insights for further exploiting the temporal learning capabilities of SNNs.
Error Amplification Limits ANN-to-SNN Conversion in Continuous Control
Jan 29, 2026Spiking Neural Networks (SNNs) can achieve competitive performance by converting already existing well-trained Artificial Neural Networks (ANNs), avoiding further costly training. This property is particularly attractive in Reinforcement Learning (RL), where training through environment interaction is expensive and potentially unsafe. However, existing conversion methods perform poorly in continuous control, where suitable baselines are largely absent. We identify error amplification as the key cause: small action approximation errors become temporally correlated across decision steps, inducing cumulative state distribution shift and severe performance degradation. To address this issue, we propose Cross-Step Residual Potential Initialization (CRPI), a lightweight training-free mechanism that carries over residual membrane potentials across decision steps to suppress temporally correlated errors. Experiments on continuous control benchmarks with both vector and visual observations demonstrate that CRPI can be integrated into existing conversion pipelines and substantially recovers lost performance. Our results highlight continuous control as a critical and challenging benchmark for ANN-to-SNN conversion, where small errors can be strongly amplified and impact performance.
General Self-Prediction Enhancement for Spiking Neurons
Jan 29, 2026Spiking Neural Networks (SNNs) are highly energy-efficient due to event-driven, sparse computation, but their training is challenged by spike non-differentiability and trade-offs among performance, efficiency, and biological plausibility. Crucially, mainstream SNNs ignore predictive coding, a core cortical mechanism where the brain predicts inputs and encodes errors for efficient perception. Inspired by this, we propose a self-prediction enhanced spiking neuron method that generates an internal prediction current from its input-output history to modulate membrane potential. This design offers dual advantages, it creates a continuous gradient path that alleviates vanishing gradients and boosts training stability and accuracy, while also aligning with biological principles, which resembles distal dendritic modulation and error-driven synaptic plasticity. Experiments show consistent performance gains across diverse architectures, neuron types, time steps, and tasks demonstrating broad applicability for enhancing SNNs.
Driving in Spikes: An Entropy-Guided Object Detector for Spike Cameras
Nov 19, 2025Object detection in autonomous driving suffers from motion blur and saturation under fast motion and extreme lighting. Spike cameras, offer microsecond latency and ultra high dynamic range for object detection by using per pixel asynchronous integrate and fire. However, their sparse, discrete output cannot be processed by standard image-based detectors, posing a critical challenge for end to end spike stream detection. We propose EASD, an end to end spike camera detector with a dual branch design: a Temporal Based Texture plus Feature Fusion branch for global cross slice semantics, and an Entropy Selective Attention branch for object centric details. To close the data gap, we introduce DSEC Spike, the first driving oriented simulated spike detection benchmark.
$π_\texttt{RL}$: Online RL Fine-tuning for Flow-based Vision-Language-Action Models
Oct 29, 2025


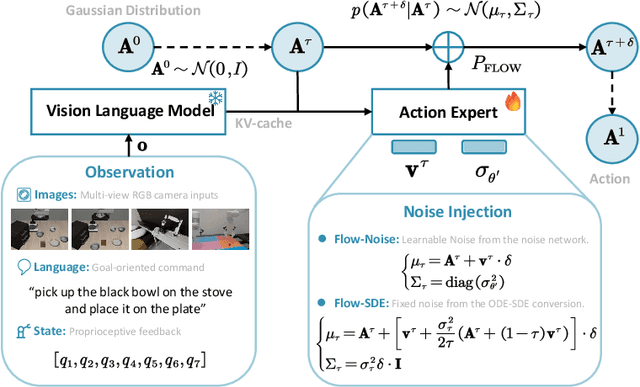
Vision-Language-Action (VLA) models enable robots to understand and perform complex tasks from multimodal input. Although recent work explores using reinforcement learning (RL) to automate the laborious data collection process in scaling supervised fine-tuning (SFT), applying large-scale RL to flow-based VLAs (e.g., $\pi_0$, $\pi_{0.5}$) remains challenging due to intractable action log-likelihoods from iterative denoising. We address this challenge with $\pi_{\text{RL}}$, an open-source framework for training flow-based VLAs in parallel simulation. $\pi_{\text{RL}}$ implements two RL algorithms: (1) {Flow-Noise} models the denoising process as a discrete-time MDP with a learnable noise network for exact log-likelihood computation. (2) {Flow-SDE} integrates denoising with agent-environment interaction, formulating a two-layer MDP that employs ODE-to-SDE conversion for efficient RL exploration. We evaluate $\pi_{\text{RL}}$ on LIBERO and ManiSkill benchmarks. On LIBERO, $\pi_{\text{RL}}$ boosts few-shot SFT models $\pi_0$ and $\pi_{0.5}$ from 57.6% to 97.6% and from 77.1% to 98.3%, respectively. In ManiSkill, we train $\pi_{\text{RL}}$ in 320 parallel environments, improving $\pi_0$ from 41.6% to 85.7% and $\pi_{0.5}$ from 40.0% to 84.8% across 4352 pick-and-place tasks, demonstrating scalable multitask RL under heterogeneous simulation. Overall, $\pi_{\text{RL}}$ achieves significant performance gains and stronger generalization over SFT-models, validating the effectiveness of online RL for flow-based VLAs.
Proxy Target: Bridging the Gap Between Discrete Spiking Neural Networks and Continuous Control
May 30, 2025



Spiking Neural Networks (SNNs) offer low-latency and energy-efficient decision making through neuromorphic hardware, making them compelling for Reinforcement Learning (RL) in resource-constrained edge devices. Recent studies in this field directly replace Artificial Neural Networks (ANNs) by SNNs in existing RL frameworks, overlooking whether the RL algorithm is suitable for SNNs. However, most RL algorithms in continuous control are designed tailored to ANNs, including the target network soft updates mechanism, which conflict with the discrete, non-differentiable dynamics of SNN spikes. We identify that this mismatch destabilizes SNN training in continuous control tasks. To bridge this gap between discrete SNN and continuous control, we propose a novel proxy target framework. The continuous and differentiable dynamics of the proxy target enable smooth updates, bypassing the incompatibility of SNN spikes, stabilizing the RL algorithms. Since the proxy network operates only during training, the SNN retains its energy efficiency during deployment without inference overhead. Extensive experiments on continuous control benchmarks demonstrate that compared to vanilla SNNs, the proxy target framework enables SNNs to achieve up to 32% higher performance across different spiking neurons. Notably, we are the first to surpass ANN performance in continuous control with simple Leaky-Integrate-and-Fire (LIF) neurons. This work motivates a new class of SNN-friendly RL algorithms tailored to SNN's characteristics, paving the way for neuromorphic agents that combine high performance with low power consumption.