 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMReD: A Meta-Review Dataset for Controllable Text Generation
Oct 14, 2021
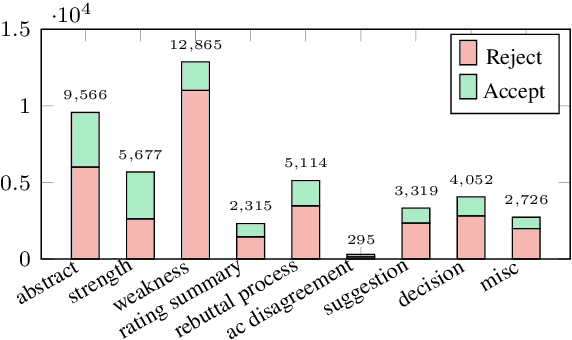
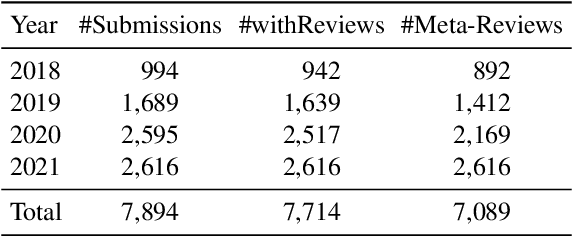
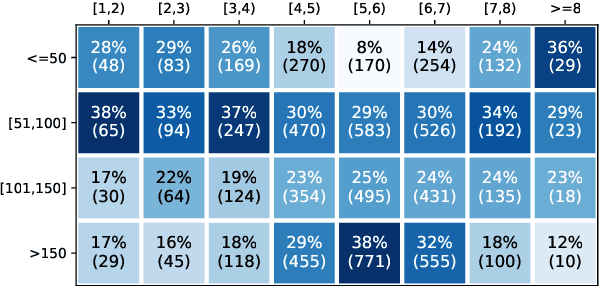
When directly using existing text generation datasets for controllable generation, we are facing the problem of not having the domain knowledge and thus the aspects that could be controlled are limited.A typical example is when using CNN/Daily Mail dataset for controllable text summarization, there is no guided information on the emphasis of summary sentences. A more useful text generator should leverage both the input text and control variables to guide the generation, which can only be built with deep understanding of the domain knowledge. Motivated by this vi-sion, our paper introduces a new text generation dataset, named MReD. Our new dataset consists of 7,089 meta-reviews and all its 45k meta-review sentences are manually annotated as one of the carefully defined 9 categories, including abstract, strength, decision, etc. We present experimental results on start-of-the-art summarization models, and propose methods for controlled generation on both extractive and abstractive models using our annotated data. By exploring various settings and analaysing the model behavior with respect to the control inputs, we demonstrate the challenges and values of our dataset. MReD allows us to have a better understanding of the meta-review corpora and enlarge the research room for controllable text generation.
DialogueCSE: Dialogue-based Contrastive Learning of Sentence Embeddings
Sep 26, 2021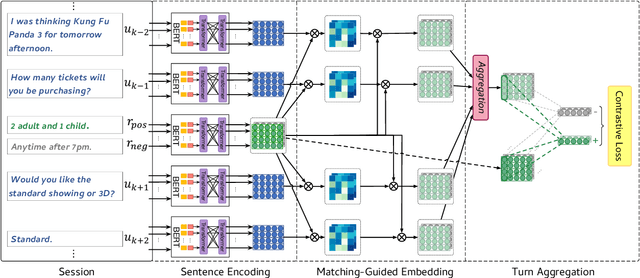
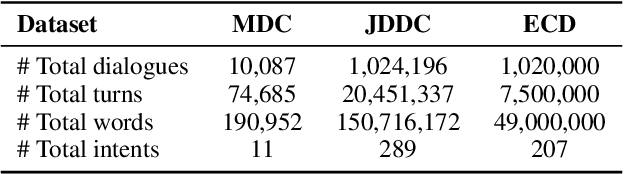
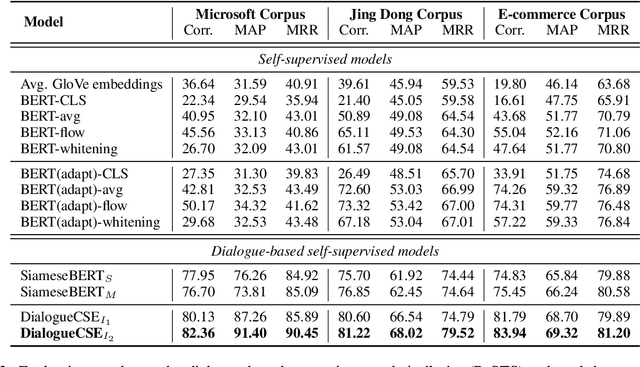
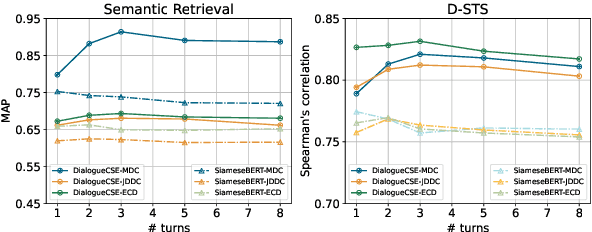
Learning sentence embeddings from dialogues has drawn increasing attention due to its low annotation cost and high domain adaptability. Conventional approaches employ the siamese-network for this task, which obtains the sentence embeddings through modeling the context-response semantic relevance by applying a feed-forward network on top of the sentence encoders. However, as the semantic textual similarity is commonly measured through the element-wise distance metrics (e.g. cosine and L2 distance), such architecture yields a large gap between training and evaluating. In this paper, we propose DialogueCSE, a dialogue-based contrastive learning approach to tackle this issue. DialogueCSE first introduces a novel matching-guided embedding (MGE) mechanism, which generates a context-aware embedding for each candidate response embedding (i.e. the context-free embedding) according to the guidance of the multi-turn context-response matching matrices. Then it pairs each context-aware embedding with its corresponding context-free embedding and finally minimizes the contrastive loss across all pairs. We evaluate our model on three multi-turn dialogue datasets: the Microsoft Dialogue Corpus, the Jing Dong Dialogue Corpus, and the E-commerce Dialogue Corpus. Evaluation results show that our approach significantly outperforms the baselines across all three datasets in terms of MAP and Spearman's correlation measures, demonstrating its effectiveness. Further quantitative experiments show that our approach achieves better performance when leveraging more dialogue context and remains robust when less training data is provided.
LightNER: A Lightweight Generative Framework with Prompt-guided Attention for Low-resource NER
Sep 09, 2021
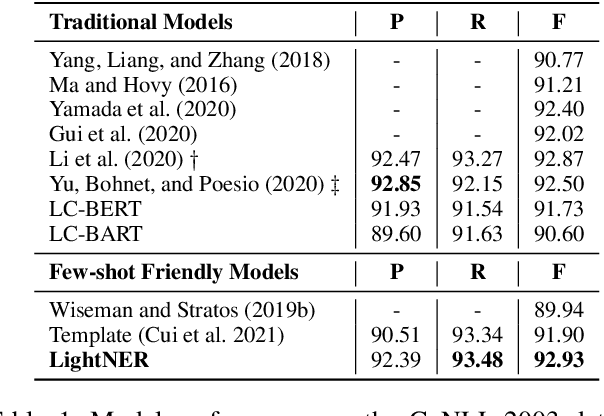
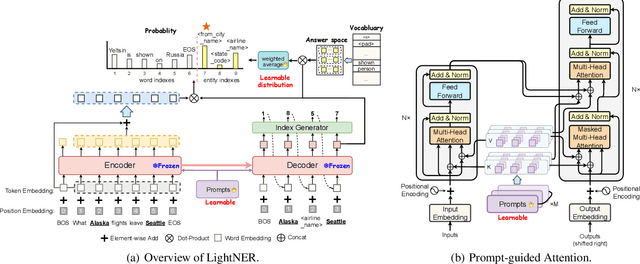
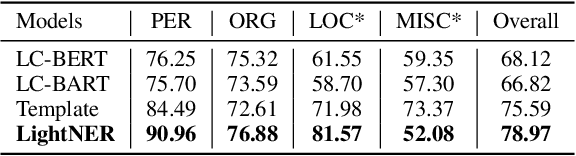
Most existing NER methods rely on extensive labeled data for model training, which struggles in the low-resource scenarios with limited training data. Recently, prompt-tuning methods for pre-trained language models have achieved remarkable performance in few-shot learning by exploiting prompts as task guidance to reduce the gap between training progress and downstream tuning. Inspired by prompt learning, we propose a novel lightweight generative framework with prompt-guided attention for low-resource NER (LightNER). Specifically, we construct the semantic-aware answer space of entity categories for prompt learning to generate the entity span sequence and entity categories without any label-specific classifiers. We further propose prompt-guided attention by incorporating continuous prompts into the self-attention layer to re-modulate the attention and adapt pre-trained weights. Note that we only tune those continuous prompts with the whole parameter of the pre-trained language model fixed, thus, making our approach lightweight and flexible for low-resource scenarios and can better transfer knowledge across domains. Experimental results show that LightNER can obtain comparable performance in the standard supervised setting and outperform strong baselines in low-resource settings by tuning only a small part of the parameters.
MELM: Data Augmentation with Masked Entity Language Modeling for Cross-lingual NER
Aug 31, 2021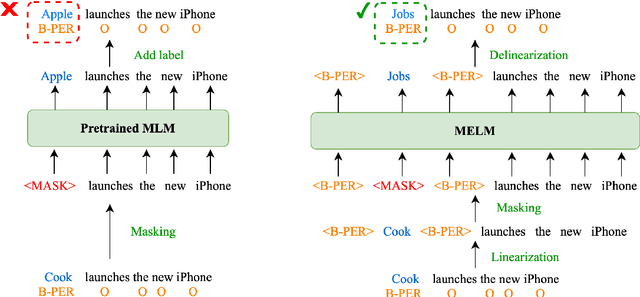
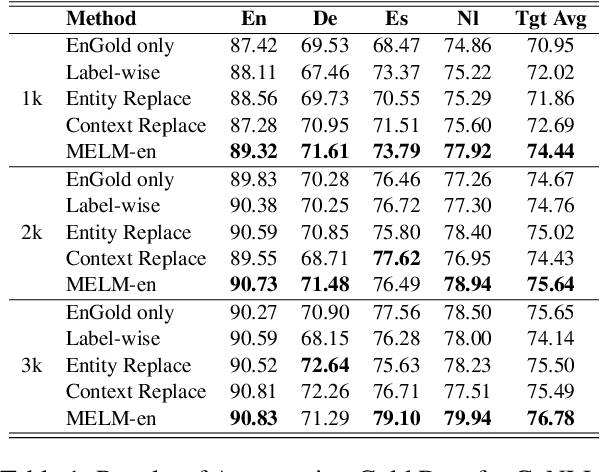
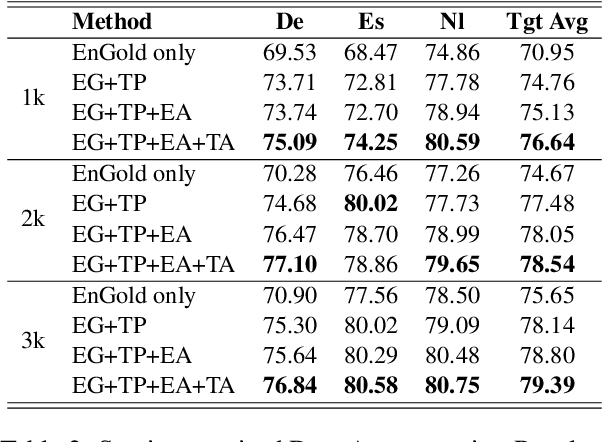

Data augmentation for cross-lingual NER requires fine-grained control over token labels of the augmented text. Existing augmentation approach based on masked language modeling may replace a labeled entity with words of a different class, which makes the augmented sentence incompatible with the original label sequence, and thus hurts the performance.We propose a data augmentation framework with Masked-Entity Language Modeling (MELM) which effectively ensures the replacing entities fit the original labels. Specifically, MELM linearizes NER labels into sentence context, and thus the fine-tuned MELM is able to predict masked tokens by explicitly conditioning on their labels. Our MELM is agnostic to the source of data to be augmented. Specifically, when MELM is applied to augment training data of the source language, it achieves up to 3.5% F1 score improvement for cross-lingual NER. When unlabeled target data is available and MELM can be further applied to augment pseudo-labeled target data, the performance gain reaches 5.7%. Moreover, MELM consistently outperforms multiple baseline methods for data augmentation.
CBLUE: A Chinese Biomedical Language Understanding Evaluation Benchmark
Jul 06, 2021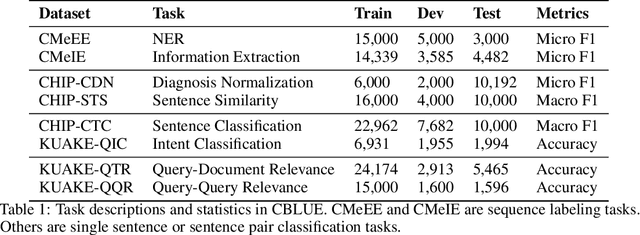
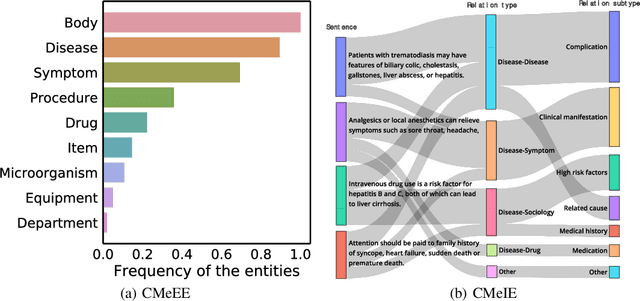
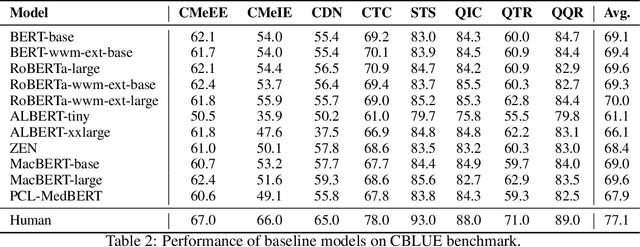
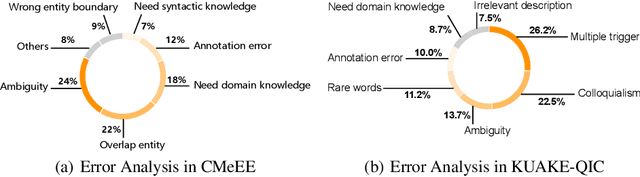
Artificial Intelligence (AI), along with the recent progress in biomedical language understanding, is gradually changing medical practice. With the development of biomedical language understanding benchmarks, AI applications are widely used in the medical field. However, most benchmarks are limited to English, which makes it challenging to replicate many of the successes in English for other languages. To facilitate research in this direction, we collect real-world biomedical data and present the first Chinese Biomedical Language Understanding Evaluation (CBLUE) benchmark: a collection of natural language understanding tasks including named entity recognition, information extraction, clinical diagnosis normalization, single-sentence/sentence-pair classification, and an associated online platform for model evaluation, comparison, and analysis. To establish evaluation on these tasks, we report empirical results with the current 11 pre-trained Chinese models, and experimental results show that state-of-the-art neural models perform by far worse than the human ceiling. Our benchmark is released at \url{https://tianchi.aliyun.com/dataset/dataDetail?dataId=95414&lang=en-us}.
Document-level Relation Extraction as Semantic Segmentation
Jun 07, 2021
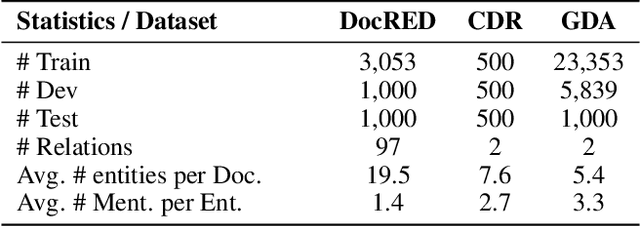
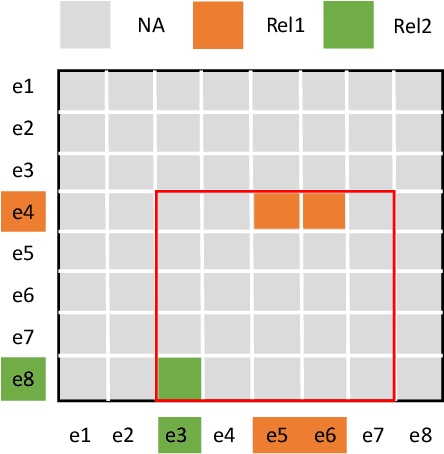
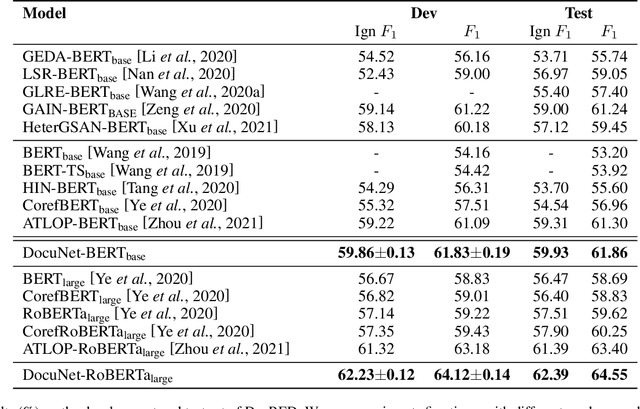
Document-level relation extraction aims to extract relations among multiple entity pairs from a document. Previously proposed graph-based or transformer-based models utilize the entities independently, regardless of global information among relational triples. This paper approaches the problem by predicting an entity-level relation matrix to capture local and global information, parallel to the semantic segmentation task in computer vision. Herein, we propose a Document U-shaped Network for document-level relation extraction. Specifically, we leverage an encoder module to capture the context information of entities and a U-shaped segmentation module over the image-style feature map to capture global interdependency among triples. Experimental results show that our approach can obtain state-of-the-art performance on three benchmark datasets DocRED, CDR, and GDA.
On the Effectiveness of Adapter-based Tuning for Pretrained Language Model Adaptation
Jun 06, 2021
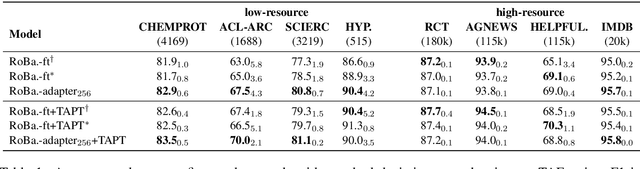
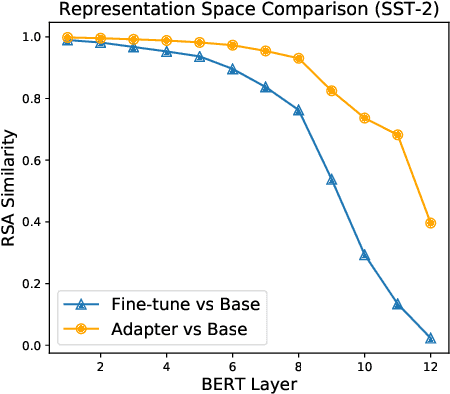
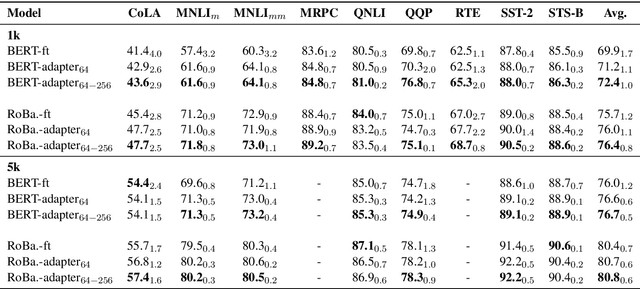
Adapter-based tuning has recently arisen as an alternative to fine-tuning. It works by adding light-weight adapter modules to a pretrained language model (PrLM) and only updating the parameters of adapter modules when learning on a downstream task. As such, it adds only a few trainable parameters per new task, allowing a high degree of parameter sharing. Prior studies have shown that adapter-based tuning often achieves comparable results to fine-tuning. However, existing work only focuses on the parameter-efficient aspect of adapter-based tuning while lacking further investigation on its effectiveness. In this paper, we study the latter. We first show that adapter-based tuning better mitigates forgetting issues than fine-tuning since it yields representations with less deviation from those generated by the initial PrLM. We then empirically compare the two tuning methods on several downstream NLP tasks and settings. We demonstrate that 1) adapter-based tuning outperforms fine-tuning on low-resource and cross-lingual tasks; 2) it is more robust to overfitting and less sensitive to changes in learning rates.
Preview, Attend and Review: Schema-Aware Curriculum Learning for Multi-Domain Dialog State Tracking
Jun 01, 2021
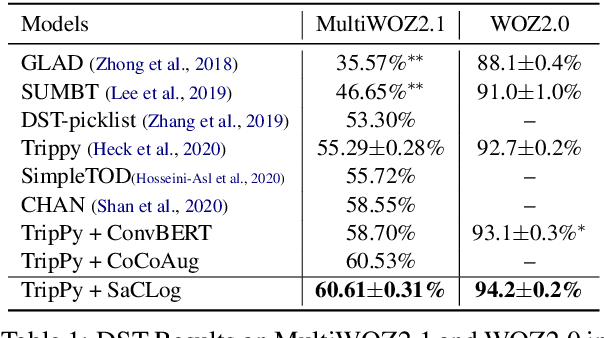
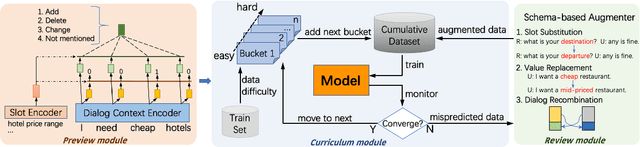
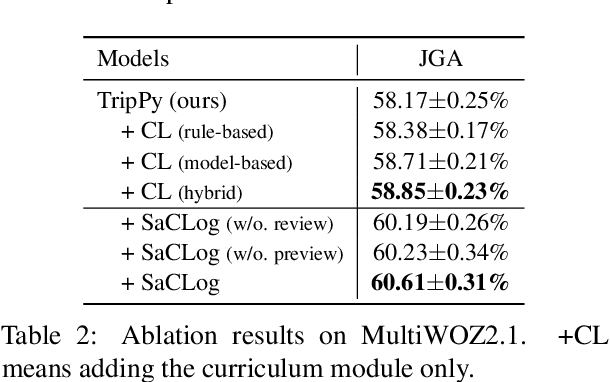
Existing dialog state tracking (DST) models are trained with dialog data in a random order, neglecting rich structural information in a dataset. In this paper, we propose to use curriculum learning (CL) to better leverage both the curriculum structure and schema structure for task-oriented dialogs. Specifically, we propose a model-agnostic framework called Schema-aware Curriculum Learning for Dialog State Tracking (SaCLog), which consists of a preview module that pre-trains a DST model with schema information, a curriculum module that optimizes the model with CL, and a review module that augments mispredicted data to reinforce the CL training. We show that our proposed approach improves DST performance over both a transformer-based and RNN-based DST model (TripPy and TRADE) and achieves new state-of-the-art results on WOZ2.0 and MultiWOZ2.1.
StructuralLM: Structural Pre-training for Form Understanding
May 24, 2021
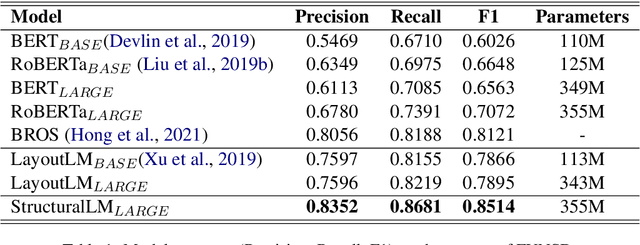
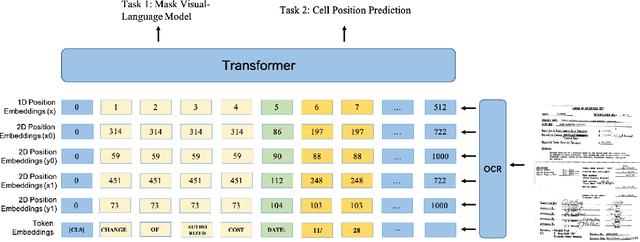
Large pre-trained language models achieve state-of-the-art results when fine-tuned on downstream NLP tasks. However, they almost exclusively focus on text-only representation, while neglecting cell-level layout information that is important for form image understanding. In this paper, we propose a new pre-training approach, StructuralLM, to jointly leverage cell and layout information from scanned documents. Specifically, we pre-train StructuralLM with two new designs to make the most of the interactions of cell and layout information: 1) each cell as a semantic unit; 2) classification of cell positions. The pre-trained StructuralLM achieves new state-of-the-art results in different types of downstream tasks, including form understanding (from 78.95 to 85.14), document visual question answering (from 72.59 to 83.94) and document image classification (from 94.43 to 96.08).
Leveraging Online Shopping Behaviors as a Proxy for Personal Lifestyle Choices: New Insights into Chronic Disease Prevention Literacy
Apr 30, 2021


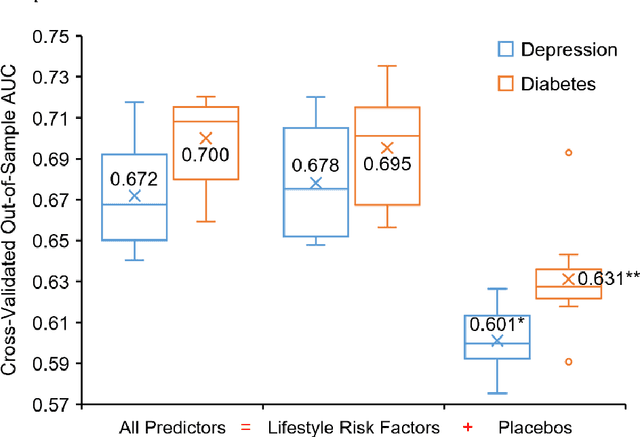
Ubiquitous internet access is reshaping the way we live, but it is accompanied by unprecedented challenges to prevent chronic diseases planted in long exposure to unhealthy lifestyles. This paper proposes leveraging online shopping behaviors as a proxy for personal lifestyle choices to freshen chronic disease prevention literacy targeted for times when e-commerce user experience has been assimilated into most people's daily life. Here, retrospective longitudinal query logs and purchase records from millions of online shoppers were accessed, constructing a broad spectrum of lifestyle features covering assorted product categories and buyer personas. Using the lifestyle-related information preceding their first purchases of prescription drugs, we could determine associations between online shoppers' past lifestyle choices and if they suffered from a particular chronic disease. Novel lifestyle risk factors were discovered in two exemplars -- depression and diabetes, most of which showed cognitive congruence with existing healthcare knowledge. Further, such empirical findings could be adopted to locate online shoppers at high risk of chronic diseases with fair accuracy (e.g., [area under the receiver operating characteristic curve] AUC=0.68 for depression and AUC=0.70 for diabetes), closely matching the performance of screening surveys benchmarked against medical diagnosis. Unobtrusive chronic disease surveillance via e-commerce sites may soon meet consenting individuals in the digital space they already inhabit.