 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDep-LLM: Training-Free Depression Diagnosis via Evidence-Guided Structured Multi-factor with Reliable LLM Reasoning
Jun 09, 2026Automatic Depression Detection (ADD) from clinical interviews is a pivotal task in computational mental health, yet it remains challenging due to two critical obstacles: 1) difficulty in modeling complex but sparsely distributed depression clues within lengthy, multi-topic clinical interviews, leading to superficial and unreliable reasoning; 2) scarcity of labeled data due to clinical privacy, together with high cost of training and fine-tuning, limiting the deployment of supervised ADD systems. To jointly address these challenges, we propose Dep-LLM, a training-free framework that mirrors the step-by-step reasoning of clinical psychiatrists and operates entirely on frozen off-the-shelf foundation LLMs. Dep-LLM comprises three stages. First, a Chain-of-Thought (CoT) Depression Multi-factor Analysis module structurally decomposes the long dialogue into five clinically aligned themes and produces evidence-grounded rationales, effectively handling long-context dependencies. Second, we introduce Confidence Analysis and Modulation module that quantifies the epistemic reliability from token-level entropy of each rationale and applies an intra-label and inter-theme modulation that amplifies trustworthy signals while suppressing uncertain ones without extra training. Third, a Collaborative Multi-factor Prediction module dynamically integrates multi-factor signals weighted by confidence into the final diagnosis. Extensive experiments on the DAIC-WOZ and E-DAIC datasets demonstrate the effectiveness and generalizability of Dep-LLM: it surpasses zero-shot baseline on nearly all 21 foundation LLMs across 9 metrics such as accuracy, macro F1 and weighted-average F1, and further outperforms state-of-the-art supervised domain-specific LLMs as well as the latest closed-source commercial LLMs, while requiring no extra training.
CoDA: Towards Effective Cross-domain Knowledge Transfer via CoT-guided Domain Adaptation
Apr 21, 2026Large language models (LLMs) have achieved substantial advances in logical reasoning, yet they continue to lag behind human-level performance. In-context learning provides a viable solution that boosts the model's performance via prompting its input with expert-curated, in-domain exemplars. However, in many real-world, expertise-scarce domains, such as low-resource scientific disciplines, emerging biomedical subfields, or niche legal jurisdictions, such high-quality in-domain demonstrations are inherently limited or entirely unavailable, thereby constraining the general applicability of these approaches. To mitigate this limitation, recent efforts have explored the retrieval of cross-domain samples as surrogate in-context demonstrations. Nevertheless, the resulting gains remain modest. This is largely attributable to the pronounced domain shift between source and target distributions, which impedes the model's ability to effectively identify and exploit underlying shared structures or latent reasoning patterns. Consequently, when relying solely on raw textual prompting, LLMs struggle to abstract and transfer such cross-domain knowledge in a robust and systematic manner. To address these issues, we propose CoDA, which employs a lightweight adapter to directly intervene in the intermediate hidden states. By combining feature-based distillation of CoT-enriched reference representations with Maximum Mean Discrepancy (MMD) for kernelized distribution matching, our method aligns the latent reasoning representation of the source and target domains. Extensive experimental results on multiple logical reasoning tasks across various model families validate the efficacy of CoDA by significantly outperforming the previous state-of-the-art baselines by a large margin.
Towards Effective In-context Cross-domain Knowledge Transfer via Domain-invariant-neurons-based Retrieval
Apr 07, 2026Large language models (LLMs) have made notable progress in logical reasoning, yet still fall short of human-level performance. Current boosting strategies rely on expert-crafted in-domain demonstrations, limiting their applicability in expertise-scarce domains, such as specialized mathematical reasoning, formal logic, or legal analysis. In this work, we demonstrate the feasibility of leveraging cross-domain demonstrating examples to boost the LLMs' reasoning performance. Despite substantial domain differences, many reusable implicit logical structures are shared across domains. In order to effectively retrieve cross-domain examples for unseen domains under investigation, in this work, we further propose an effective retrieval method, called domain-invariant neurons-based retrieval (\textbf{DIN-Retrieval}). Concisely, DIN-Retrieval first summarizes a hidden representation that is universal across different domains. Then, during the inference stage, we use the DIN vector to retrieve structurally compatible cross-domain demonstrations for the in-context learning. Experimental results in multiple settings for the transfer of mathematical and logical reasoning demonstrate that our method achieves an average improvement of 1.8 over the state-of-the-art methods \footnote{Our implementation is available at https://github.com/Leon221220/DIN-Retrieval}.
Reason Analogically via Cross-domain Prior Knowledge: An Empirical Study of Cross-domain Knowledge Transfer for In-Context Learning
Apr 07, 2026Despite its success, existing in-context learning (ICL) relies on in-domain expert demonstrations, limiting its applicability when expert annotations are scarce. We posit that different domains may share underlying reasoning structures, enabling source-domain demonstrations to improve target-domain inference despite semantic mismatch. To test this hypothesis, we conduct a comprehensive empirical study of different retrieval methods to validate the feasibility of achieving cross-domain knowledge transfer under the in-context learning setting. Our results demonstrate conditional positive transfer in cross-domain ICL. We identify a clear example absorption threshold: beyond it, positive transfer becomes more likely, and additional demonstrations yield larger gains. Further analysis suggests that these gains stem from reasoning structure repair by retrieved cross-domain examples, rather than semantic cues. Overall, our study validates the feasibility of leveraging cross-domain knowledge transfer to improve cross-domain ICL performance, motivating the community to explore designing more effective retrieval approaches for this novel direction.\footnote{Our implementation is available at https://github.com/littlelaska/ICL-TF4LR}
From Long to Lean: Performance-aware and Adaptive Chain-of-Thought Compression via Multi-round Refinement
Sep 26, 2025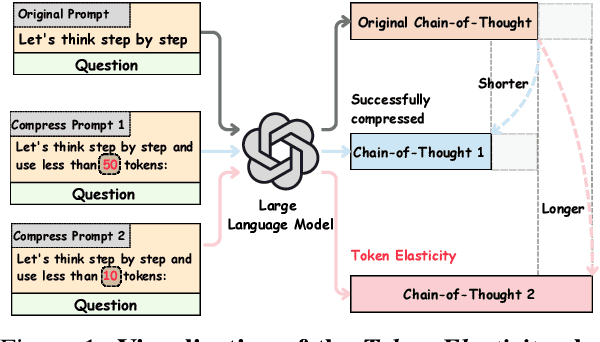
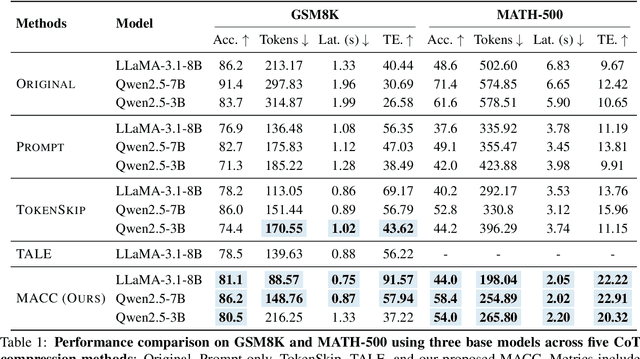
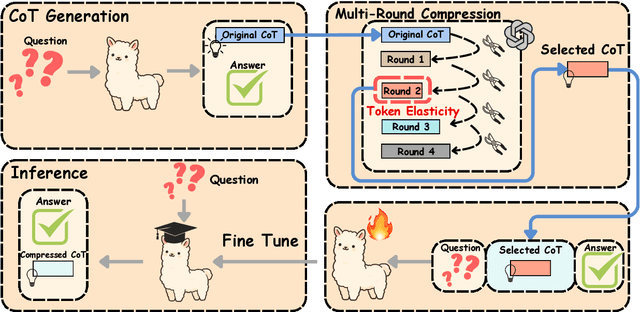
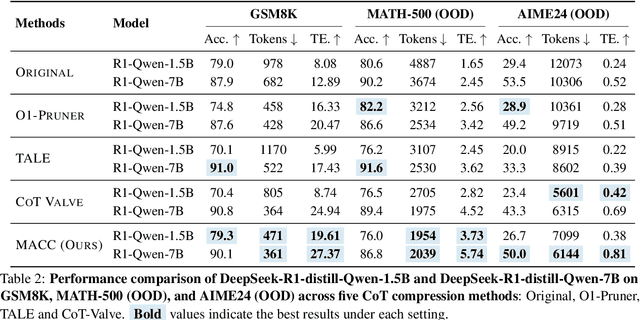
Chain-of-Thought (CoT) reasoning improves performance on complex tasks but introduces significant inference latency due to verbosity. We propose Multiround Adaptive Chain-of-Thought Compression (MACC), a framework that leverages the token elasticity phenomenon--where overly small token budgets can paradoxically increase output length--to progressively compress CoTs via multiround refinement. This adaptive strategy allows MACC to determine the optimal compression depth for each input. Our method achieves an average accuracy improvement of 5.6 percent over state-of-the-art baselines, while also reducing CoT length by an average of 47 tokens and significantly lowering latency. Furthermore, we show that test-time performance--accuracy and token length--can be reliably predicted using interpretable features like perplexity and compression rate on the training set. Evaluated across different models, our method enables efficient model selection and forecasting without repeated fine-tuning, demonstrating that CoT compression is both effective and predictable. Our code will be released in https://github.com/Leon221220/MACC.
Learning in Order! A Sequential Strategy to Learn Invariant Features for Multimodal Sentiment Analysis
Sep 05, 2024



This work proposes a novel and simple sequential learning strategy to train models on videos and texts for multimodal sentiment analysis. To estimate sentiment polarities on unseen out-of-distribution data, we introduce a multimodal model that is trained either in a single source domain or multiple source domains using our learning strategy. This strategy starts with learning domain invariant features from text, followed by learning sparse domain-agnostic features from videos, assisted by the selected features learned in text. Our experimental results demonstrate that our model achieves significantly better performance than the state-of-the-art approaches on average in both single-source and multi-source settings. Our feature selection procedure favors the features that are independent to each other and are strongly correlated with their polarity labels. To facilitate research on this topic, the source code of this work will be publicly available upon acceptance.
Advancing Biomedical Text Mining with Community Challenges
Mar 07, 2024The field of biomedical research has witnessed a significant increase in the accumulation of vast amounts of textual data from various sources such as scientific literatures, electronic health records, clinical trial reports, and social media. However, manually processing and analyzing these extensive and complex resources is time-consuming and inefficient. To address this challenge, biomedical text mining, also known as biomedical natural language processing, has garnered great attention. Community challenge evaluation competitions have played an important role in promoting technology innovation and interdisciplinary collaboration in biomedical text mining research. These challenges provide platforms for researchers to develop state-of-the-art solutions for data mining and information processing in biomedical research. In this article, we review the recent advances in community challenges specific to Chinese biomedical text mining. Firstly, we collect the information of these evaluation tasks, such as data sources and task types. Secondly, we conduct systematic summary and comparative analysis, including named entity recognition, entity normalization, attribute extraction, relation extraction, event extraction, text classification, text similarity, knowledge graph construction, question answering, text generation, and large language model evaluation. Then, we summarize the potential clinical applications of these community challenge tasks from translational informatics perspective. Finally, we discuss the contributions and limitations of these community challenges, while highlighting future directions in the era of large language models.
Toward Robust Multimodal Learning using Multimodal Foundational Models
Jan 20, 2024Existing multimodal sentiment analysis tasks are highly rely on the assumption that the training and test sets are complete multimodal data, while this assumption can be difficult to hold: the multimodal data are often incomplete in real-world scenarios. Therefore, a robust multimodal model in scenarios with randomly missing modalities is highly preferred. Recently, CLIP-based multimodal foundational models have demonstrated impressive performance on numerous multimodal tasks by learning the aligned cross-modal semantics of image and text pairs, but the multimodal foundational models are also unable to directly address scenarios involving modality absence. To alleviate this issue, we propose a simple and effective framework, namely TRML, Toward Robust Multimodal Learning using Multimodal Foundational Models. TRML employs generated virtual modalities to replace missing modalities, and aligns the semantic spaces between the generated and missing modalities. Concretely, we design a missing modality inference module to generate virtual modaliites and replace missing modalities. We also design a semantic matching learning module to align semantic spaces generated and missing modalities. Under the prompt of complete modality, our model captures the semantics of missing modalities by leveraging the aligned cross-modal semantic space. Experiments demonstrate the superiority of our approach on three multimodal sentiment analysis benchmark datasets, CMU-MOSI, CMU-MOSEI, and MELD.
Improving Natural Language Understanding with Computation-Efficient Retrieval Representation Fusion
Jan 04, 2024Retrieval-based augmentations that aim to incorporate knowledge from an external database into language models have achieved great success in various knowledge-intensive (KI) tasks, such as question-answering and text generation. However, integrating retrievals in non-knowledge-intensive (NKI) tasks, such as text classification, is still challenging. Existing works focus on concatenating retrievals to inputs as context to form the prompt-based inputs. Unfortunately, such methods require language models to have the capability to handle long texts. Besides, inferring such concatenated data would also consume a significant amount of computational resources. To solve these challenges, we propose \textbf{ReFusion} in this paper, a computation-efficient \textbf{Re}trieval representation \textbf{Fusion} with neural architecture search. The main idea is to directly fuse the retrieval representations into the language models. Specifically, we first propose an online retrieval module that retrieves representations of similar sentences. Then, we present a retrieval fusion module including two effective ranking schemes, i.e., reranker-based scheme and ordered-mask-based scheme, to fuse the retrieval representations with hidden states. Furthermore, we use Neural Architecture Search (NAS) to seek the optimal fusion structure across different layers. Finally, we conduct comprehensive experiments, and the results demonstrate our ReFusion can achieve superior and robust performance on various NKI tasks.
Overview of the PromptCBLUE Shared Task in CHIP2023
Dec 29, 2023This paper presents an overview of the PromptCBLUE shared task (http://cips-chip.org.cn/2023/eval1) held in the CHIP-2023 Conference. This shared task reformualtes the CBLUE benchmark, and provide a good testbed for Chinese open-domain or medical-domain large language models (LLMs) in general medical natural language processing. Two different tracks are held: (a) prompt tuning track, investigating the multitask prompt tuning of LLMs, (b) probing the in-context learning capabilities of open-sourced LLMs. Many teams from both the industry and academia participated in the shared tasks, and the top teams achieved amazing test results. This paper describes the tasks, the datasets, evaluation metrics, and the top systems for both tasks. Finally, the paper summarizes the techniques and results of the evaluation of the various approaches explored by the participating teams.