 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-view X-ray Image Synthesis with Multiple Domain Disentanglement from CT Scans
Apr 18, 2024



X-ray images play a vital role in the intraoperative processes due to their high resolution and fast imaging speed and greatly promote the subsequent segmentation, registration and reconstruction. However, over-dosed X-rays superimpose potential risks to human health to some extent. Data-driven algorithms from volume scans to X-ray images are restricted by the scarcity of paired X-ray and volume data. Existing methods are mainly realized by modelling the whole X-ray imaging procedure. In this study, we propose a learning-based approach termed CT2X-GAN to synthesize the X-ray images in an end-to-end manner using the content and style disentanglement from three different image domains. Our method decouples the anatomical structure information from CT scans and style information from unpaired real X-ray images/ digital reconstructed radiography (DRR) images via a series of decoupling encoders. Additionally, we introduce a novel consistency regularization term to improve the stylistic resemblance between synthesized X-ray images and real X-ray images. Meanwhile, we also impose a supervised process by computing the similarity of computed real DRR and synthesized DRR images. We further develop a pose attention module to fully strengthen the comprehensive information in the decoupled content code from CT scans, facilitating high-quality multi-view image synthesis in the lower 2D space. Extensive experiments were conducted on the publicly available CTSpine1K dataset and achieved 97.8350, 0.0842 and 3.0938 in terms of FID, KID and defined user-scored X-ray similarity, respectively. In comparison with 3D-aware methods ($\pi$-GAN, EG3D), CT2X-GAN is superior in improving the synthesis quality and realistic to the real X-ray images.
Is GPT-3 a Psychopath? Evaluating Large Language Models from a Psychological Perspective
Dec 20, 2022Are large language models (LLMs) like GPT-3 psychologically safe? In this work, we design unbiased prompts to evaluate LLMs systematically from a psychological perspective. Firstly, we test the personality traits of three different LLMs with Short Dark Triad (SD-3) and Big Five Inventory (BFI). We find all of them show higher scores on SD-3 than the human average, indicating a relatively darker personality. Furthermore, LLMs like InstructGPT and FLAN-T5, which are fine-tuned with safety metrics, do not necessarily have more positive personalities. They score higher on Machiavellianism and Narcissism than GPT-3. Secondly, we test the LLMs in GPT-3 series on well-being tests to study the impact of fine-tuning with more training data. Interestingly, we observe a continuous increase in well-being scores from GPT-3 to InstructGPT. Following the observations, we show that instruction-finetune FLAN-T5 with positive answers in BFI can effectively improve the model from a psychological perspective. Finally, we call on the community to evaluate and improve LLMs' safety systematically instead of at the sentence level only.
Is GPT-3 a Good Data Annotator?
Dec 20, 2022



GPT-3 (Generative Pre-trained Transformer 3) is a large-scale autoregressive language model developed by OpenAI, which has demonstrated impressive few-shot performance on a wide range of natural language processing (NLP) tasks. Hence, an intuitive application is to use it for data annotation. In this paper, we investigate whether GPT-3 can be used as a good data annotator for NLP tasks. Data annotation is the process of labeling data that could be used to train machine learning models. It is a crucial step in the development of NLP systems, as it allows the model to learn the relationship between the input data and the desired output. Given the impressive language capabilities of GPT-3, it is natural to wonder whether it can be used to effectively annotate data for NLP tasks. In this paper, we evaluate the performance of GPT-3 as a data annotator by comparing it with traditional data annotation methods and analyzing its output on a range of tasks. Through this analysis, we aim to provide insight into the potential of GPT-3 as a general-purpose data annotator in NLP.
Towards Robust Low-Resource Fine-Tuning with Multi-View Compressed Representations
Nov 16, 2022Due to the huge amount of parameters, fine-tuning of pretrained language models (PLMs) is prone to overfitting in the low resource scenarios. In this work, we present a novel method that operates on the hidden representations of a PLM to reduce overfitting. During fine-tuning, our method inserts random autoencoders between the hidden layers of a PLM, which transform activations from the previous layers into a multi-view compressed representation before feeding it into the upper layers. The autoencoders are plugged out after fine-tuning, so our method does not add extra parameters or increase computation cost during inference. Our method demonstrates promising performance improvement across a wide range of sequence- and token-level low-resource NLP tasks.
Hierarchical Vectorization for Portrait Images
May 24, 2022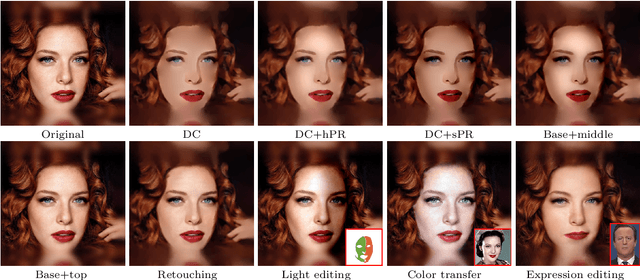
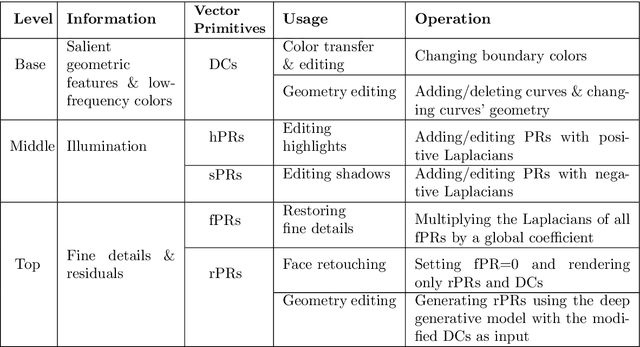
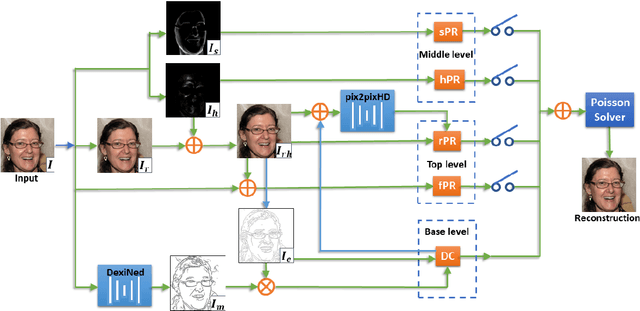
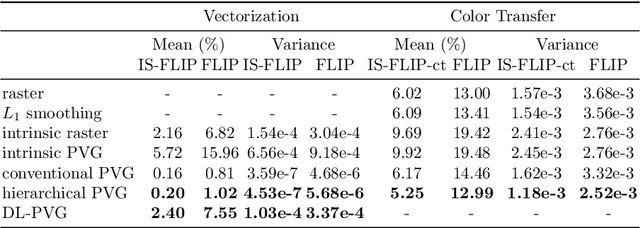
Aiming at developing intuitive and easy-to-use portrait editing tools, we propose a novel vectorization method that can automatically convert raster images into a 3-tier hierarchical representation. The base layer consists of a set of sparse diffusion curves (DC) which characterize salient geometric features and low-frequency colors and provide means for semantic color transfer and facial expression editing. The middle level encodes specular highlights and shadows to large and editable Poisson regions (PR) and allows the user to directly adjust illumination via tuning the strength and/or changing shape of PR. The top level contains two types of pixel-sized PRs for high-frequency residuals and fine details such as pimples and pigmentation. We also train a deep generative model that can produce high-frequency residuals automatically. Thanks to the meaningful organization of vector primitives, editing portraits becomes easy and intuitive. In particular, our method supports color transfer, facial expression editing, highlight and shadow editing and automatic retouching. Thanks to the linearity of the Laplace operator, we introduce alpha blending, linear dodge and linear burn to vector editing and show that they are effective in editing highlights and shadows. To quantitatively evaluate the results, we extend the commonly used FLIP metric (which measures differences between two images) by considering illumination. The new metric, called illumination-sensitive FLIP or IS-FLIP, can effectively capture the salient changes in color transfer results, and is more consistent with human perception than FLIP and other quality measures on portrait images. We evaluate our method on the FFHQR dataset and show that our method is effective for common portrait editing tasks, such as retouching, light editing, color transfer and expression editing. We will make the code and trained models publicly available.
Flexible Portrait Image Editing with Fine-Grained Control
Apr 04, 2022


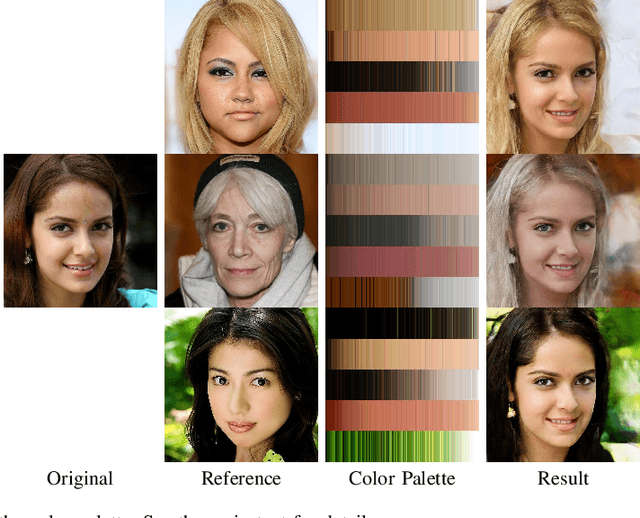
We develop a new method for portrait image editing, which supports fine-grained editing of geometries, colors, lights and shadows using a single neural network model. We adopt a novel asymmetric conditional GAN architecture: the generators take the transformed conditional inputs, such as edge maps, color palette, sliders and masks, that can be directly edited by the user; the discriminators take the conditional inputs in the way that can guide controllable image generation more effectively. Taking color editing as an example, we feed color palettes (which can be edited easily) into the generator, and color maps (which contain positional information of colors) into the discriminator. We also design a region-weighted discriminator so that higher weights are assigned to more important regions, like eyes and skin. Using a color palette, the user can directly specify the desired colors of hair, skin, eyes, lip and background. Color sliders allow the user to blend colors in an intuitive manner. The user can also edit lights and shadows by modifying the corresponding masks. We demonstrate the effectiveness of our method by evaluating it on the CelebAMask-HQ dataset with a wide range of tasks, including geometry/color/shadow/light editing, hand-drawn sketch to image translation, and color transfer. We also present ablation studies to justify our design.
Knowledge Based Multilingual Language Model
Nov 22, 2021
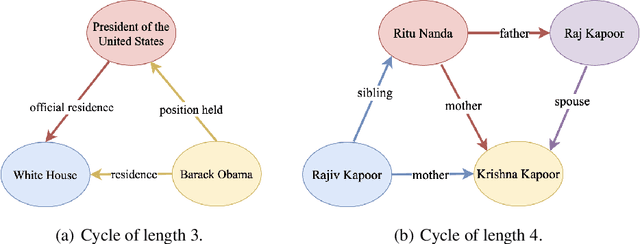
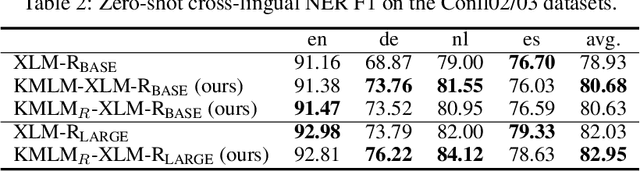
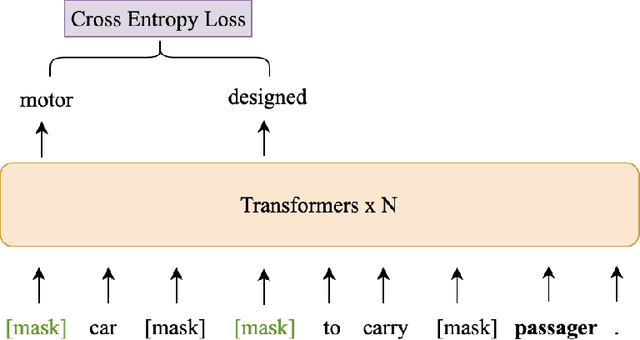
Knowledge enriched language representation learning has shown promising performance across various knowledge-intensive NLP tasks. However, existing knowledge based language models are all trained with monolingual knowledge graph data, which limits their application to more languages. In this work, we present a novel framework to pretrain knowledge based multilingual language models (KMLMs). We first generate a large amount of code-switched synthetic sentences and reasoning-based multilingual training data using the Wikidata knowledge graphs. Then based on the intra- and inter-sentence structures of the generated data, we design pretraining tasks to facilitate knowledge learning, which allows the language models to not only memorize the factual knowledge but also learn useful logical patterns. Our pretrained KMLMs demonstrate significant performance improvements on a wide range of knowledge-intensive cross-lingual NLP tasks, including named entity recognition, factual knowledge retrieval, relation classification, and a new task designed by us, namely, logic reasoning. Our code and pretrained language models will be made publicly available.
On the Effectiveness of Adapter-based Tuning for Pretrained Language Model Adaptation
Jun 06, 2021
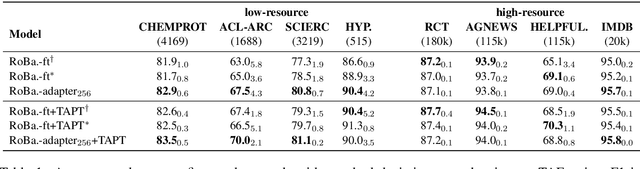
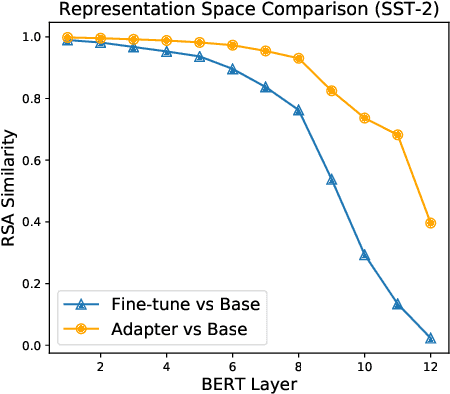
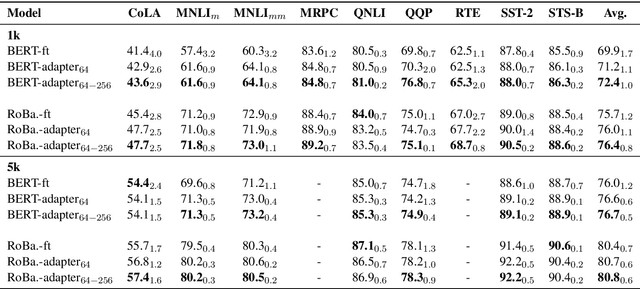
Adapter-based tuning has recently arisen as an alternative to fine-tuning. It works by adding light-weight adapter modules to a pretrained language model (PrLM) and only updating the parameters of adapter modules when learning on a downstream task. As such, it adds only a few trainable parameters per new task, allowing a high degree of parameter sharing. Prior studies have shown that adapter-based tuning often achieves comparable results to fine-tuning. However, existing work only focuses on the parameter-efficient aspect of adapter-based tuning while lacking further investigation on its effectiveness. In this paper, we study the latter. We first show that adapter-based tuning better mitigates forgetting issues than fine-tuning since it yields representations with less deviation from those generated by the initial PrLM. We then empirically compare the two tuning methods on several downstream NLP tasks and settings. We demonstrate that 1) adapter-based tuning outperforms fine-tuning on low-resource and cross-lingual tasks; 2) it is more robust to overfitting and less sensitive to changes in learning rates.
Towards Multi-Sense Cross-Lingual Alignment of Contextual Embeddings
Mar 11, 2021
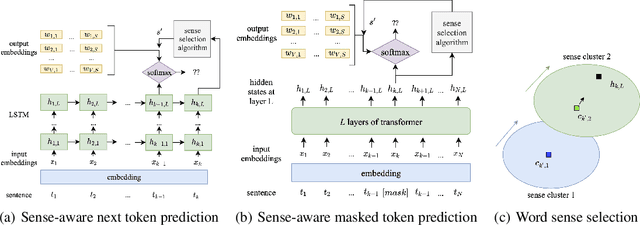
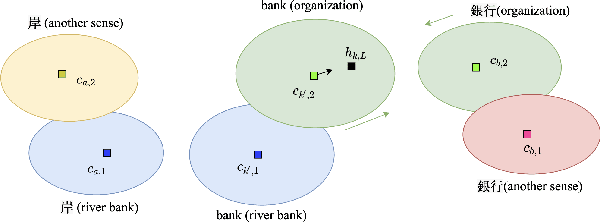
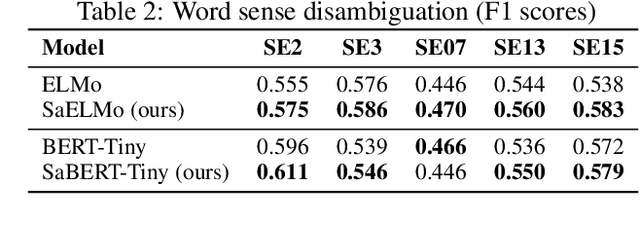
Cross-lingual word embeddings (CLWE) have been proven useful in many cross-lingual tasks. However, most existing approaches to learn CLWE including the ones with contextual embeddings are sense agnostic. In this work, we propose a novel framework to align contextual embeddings at the sense level by leveraging cross-lingual signal from bilingual dictionaries only. We operationalize our framework by first proposing a novel sense-aware cross entropy loss to model word senses explicitly. The monolingual ELMo and BERT models pretrained with our sense-aware cross entropy loss demonstrate significant performance improvement for word sense disambiguation tasks. We then propose a sense alignment objective on top of the sense-aware cross entropy loss for cross-lingual model pretraining, and pretrain cross-lingual models for several language pairs (English to German/Spanish/Japanese/Chinese). Compared with the best baseline results, our cross-lingual models achieve 0.52%, 2.09% and 1.29% average performance improvements on zero-shot cross-lingual NER, sentiment classification and XNLI tasks, respectively.
DAGA: Data Augmentation with a Generation Approach for Low-resource Tagging Tasks
Nov 03, 2020

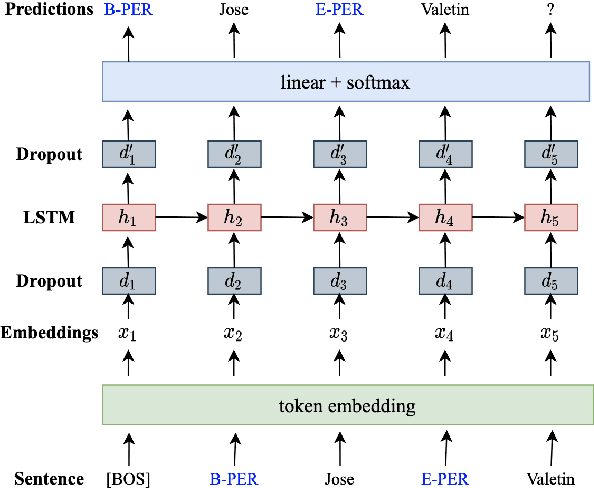
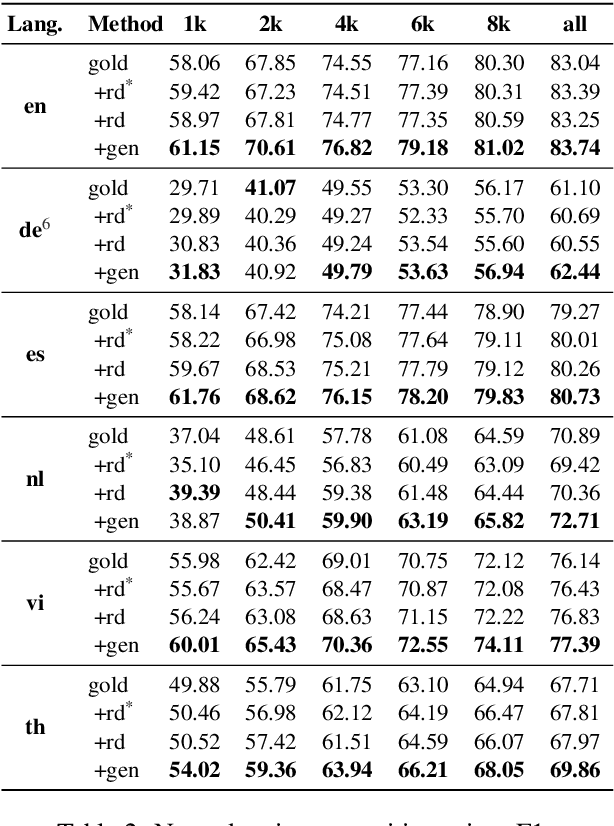
Data augmentation techniques have been widely used to improve machine learning performance as they enhance the generalization capability of models. In this work, to generate high quality synthetic data for low-resource tagging tasks, we propose a novel augmentation method with language models trained on the linearized labeled sentences. Our method is applicable to both supervised and semi-supervised settings. For the supervised settings, we conduct extensive experiments on named entity recognition (NER), part of speech (POS) tagging and end-to-end target based sentiment analysis (E2E-TBSA) tasks. For the semi-supervised settings, we evaluate our method on the NER task under the conditions of given unlabeled data only and unlabeled data plus a knowledge base. The results show that our method can consistently outperform the baselines, particularly when the given gold training data are less.