 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuarkMedBench: A Real-World Scenario Driven Benchmark for Evaluating Large Language Models
Mar 14, 2026While Large Language Models (LLMs) excel on standardized medical exams, high scores often fail to translate to high-quality responses for real-world medical queries. Current evaluations rely heavily on multiple-choice questions, failing to capture the unstructured, ambiguous, and long-tail complexities inherent in genuine user inquiries. To bridge this gap, we introduce QuarkMedBench, an ecologically valid benchmark tailored for real-world medical LLM assessment. We compiled a massive dataset spanning Clinical Care, Wellness Health, and Professional Inquiry, comprising 20,821 single-turn queries and 3,853 multi-turn sessions. To objectively evaluate open-ended answers, we propose an automated scoring framework that integrates multi-model consensus with evidence-based retrieval to dynamically generate 220,617 fine-grained scoring rubrics (~9.8 per query). During evaluation, hierarchical weighting and safety constraints structurally quantify medical accuracy, key-point coverage, and risk interception, effectively mitigating the high costs and subjectivity of human grading. Experimental results demonstrate that the generated rubrics achieve a 91.8% concordance rate with clinical expert blind audits, establishing highly dependable medical reliability. Crucially, baseline evaluations on this benchmark reveal significant performance disparities among state-of-the-art models when navigating real-world clinical nuances, highlighting the limitations of conventional exam-based metrics. Ultimately, QuarkMedBench establishes a rigorous, reproducible yardstick for measuring LLM performance on complex health issues, while its framework inherently supports dynamic knowledge updates to prevent benchmark obsolescence.
Quark Medical Alignment: A Holistic Multi-Dimensional Alignment and Collaborative Optimization Paradigm
Feb 12, 2026While reinforcement learning for large language model alignment has progressed rapidly in recent years, transferring these paradigms to high-stakes medical question answering reveals a fundamental paradigm mismatch. Reinforcement Learning from Human Feedback relies on preference annotations that are prohibitively expensive and often fail to reflect the absolute correctness of medical facts. Reinforcement Learning from Verifiable Rewards lacks effective automatic verifiers and struggles to handle complex clinical contexts. Meanwhile, medical alignment requires the simultaneous optimization of correctness, safety, and compliance, yet multi-objective heterogeneous reward signals are prone to scale mismatch and optimization conflicts.To address these challenges, we propose a robust medical alignment paradigm. We first construct a holistic multi-dimensional medical alignment matrix that decomposes alignment objectives into four categories: fundamental capabilities, expert knowledge, online feedback, and format specifications. Within each category, we establish a closed loop of where observable metrics inform attributable diagnosis, which in turn drives optimizable rewards, thereby providing fine-grained, high-resolution supervision signals for subsequent iterative optimization. To resolve gradient domination and optimization instability problem caused by heterogeneous signals, we further propose a unified optimization mechanism. This mechanism employs Reference-Frozen Normalization to align reward scales and implements a Tri-Factor Adaptive Dynamic Weighting strategy to achieve collaborative optimization that is weakness-oriented, risk-prioritized, and redundancy-reducing. Experimental results demonstrate the effectiveness of our proposed paradigm in real-world medical scenario evaluations, establishing a new paradigm for complex alignment in vertical domains.
CBLUE: A Chinese Biomedical Language Understanding Evaluation Benchmark
Jul 06, 2021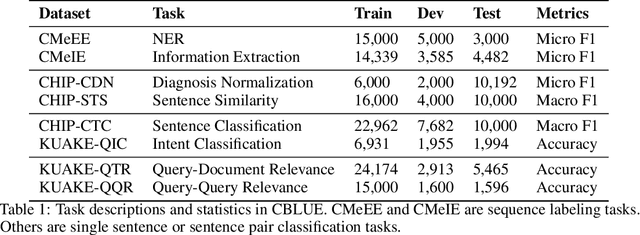
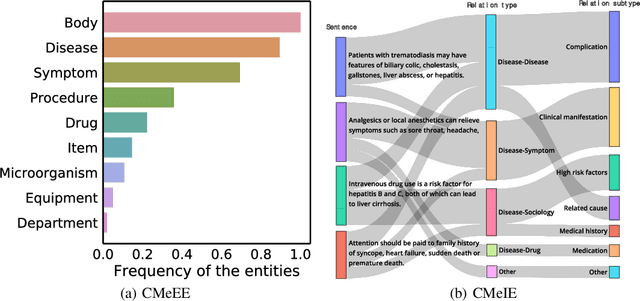
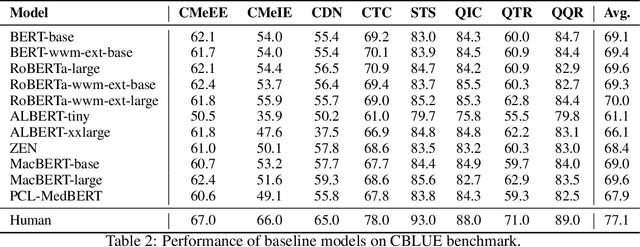
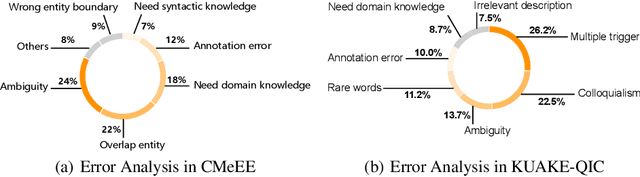
Artificial Intelligence (AI), along with the recent progress in biomedical language understanding, is gradually changing medical practice. With the development of biomedical language understanding benchmarks, AI applications are widely used in the medical field. However, most benchmarks are limited to English, which makes it challenging to replicate many of the successes in English for other languages. To facilitate research in this direction, we collect real-world biomedical data and present the first Chinese Biomedical Language Understanding Evaluation (CBLUE) benchmark: a collection of natural language understanding tasks including named entity recognition, information extraction, clinical diagnosis normalization, single-sentence/sentence-pair classification, and an associated online platform for model evaluation, comparison, and analysis. To establish evaluation on these tasks, we report empirical results with the current 11 pre-trained Chinese models, and experimental results show that state-of-the-art neural models perform by far worse than the human ceiling. Our benchmark is released at \url{https://tianchi.aliyun.com/dataset/dataDetail?dataId=95414&lang=en-us}.
Conceptualized Representation Learning for Chinese Biomedical Text Mining
Aug 25, 2020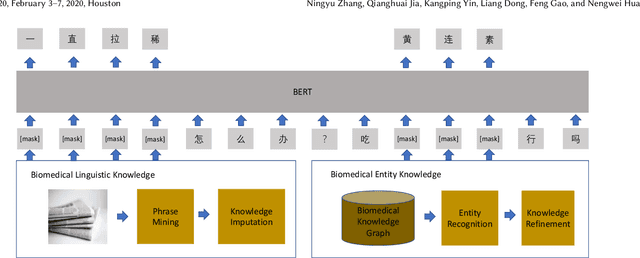

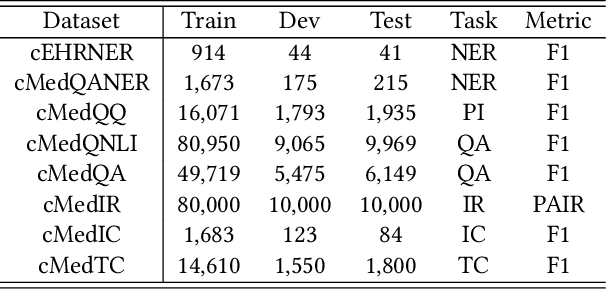
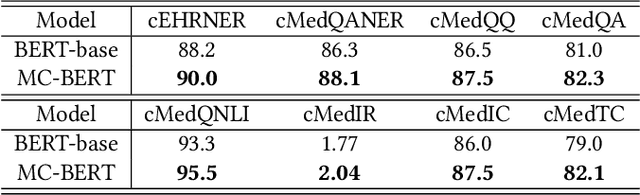
Biomedical text mining is becoming increasingly important as the number of biomedical documents and web data rapidly grows. Recently, word representation models such as BERT has gained popularity among researchers. However, it is difficult to estimate their performance on datasets containing biomedical texts as the word distributions of general and biomedical corpora are quite different. Moreover, the medical domain has long-tail concepts and terminologies that are difficult to be learned via language models. For the Chinese biomedical text, it is more difficult due to its complex structure and the variety of phrase combinations. In this paper, we investigate how the recently introduced pre-trained language model BERT can be adapted for Chinese biomedical corpora and propose a novel conceptualized representation learning approach. We also release a new Chinese Biomedical Language Understanding Evaluation benchmark (\textbf{ChineseBLUE}). We examine the effectiveness of Chinese pre-trained models: BERT, BERT-wwm, RoBERTa, and our approach. Experimental results on the benchmark show that our approach could bring significant gain. We release the pre-trained model on GitHub: https://github.com/alibaba-research/ChineseBLUE.