 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiFi-SR: A Unified Generative Transformer-Convolutional Adversarial Network for High-Fidelity Speech Super-Resolution
Jan 17, 2025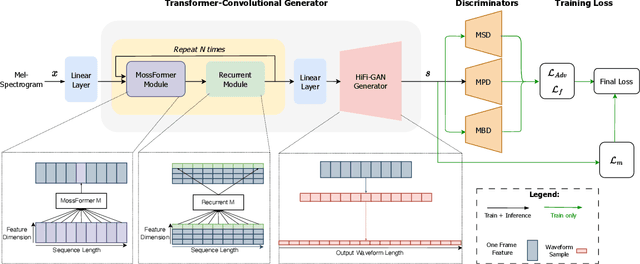
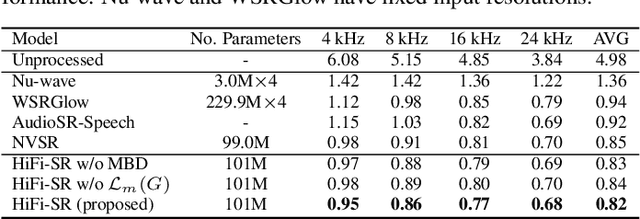

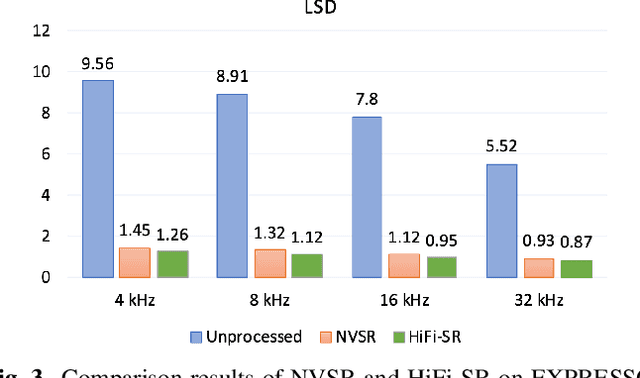
The application of generative adversarial networks (GANs) has recently advanced speech super-resolution (SR) based on intermediate representations like mel-spectrograms. However, existing SR methods that typically rely on independently trained and concatenated networks may lead to inconsistent representations and poor speech quality, especially in out-of-domain scenarios. In this work, we propose HiFi-SR, a unified network that leverages end-to-end adversarial training to achieve high-fidelity speech super-resolution. Our model features a unified transformer-convolutional generator designed to seamlessly handle both the prediction of latent representations and their conversion into time-domain waveforms. The transformer network serves as a powerful encoder, converting low-resolution mel-spectrograms into latent space representations, while the convolutional network upscales these representations into high-resolution waveforms. To enhance high-frequency fidelity, we incorporate a multi-band, multi-scale time-frequency discriminator, along with a multi-scale mel-reconstruction loss in the adversarial training process. HiFi-SR is versatile, capable of upscaling any input speech signal between 4 kHz and 32 kHz to a 48 kHz sampling rate. Experimental results demonstrate that HiFi-SR significantly outperforms existing speech SR methods across both objective metrics and ABX preference tests, for both in-domain and out-of-domain scenarios (https://github.com/modelscope/ClearerVoice-Studio).
YuLan-Mini: An Open Data-efficient Language Model
Dec 24, 2024



Effective pre-training of large language models (LLMs) has been challenging due to the immense resource demands and the complexity of the technical processes involved. This paper presents a detailed technical report on YuLan-Mini, a highly capable base model with 2.42B parameters that achieves top-tier performance among models of similar parameter scale. Our pre-training approach focuses on enhancing training efficacy through three key technical contributions: an elaborate data pipeline combines data cleaning with data schedule strategies, a robust optimization method to mitigate training instability, and an effective annealing approach that incorporates targeted data selection and long context training. Remarkably, YuLan-Mini, trained on 1.08T tokens, achieves performance comparable to industry-leading models that require significantly more data. To facilitate reproduction, we release the full details of the data composition for each training phase. Project details can be accessed at the following link: https://github.com/RUC-GSAI/YuLan-Mini.
Hierarchical Control of Emotion Rendering in Speech Synthesis
Dec 17, 2024



Emotional text-to-speech synthesis (TTS) aims to generate realistic emotional speech from input text. However, quantitatively controlling multi-level emotion rendering remains challenging. In this paper, we propose a diffusion-based emotional TTS framework with a novel approach for emotion intensity modeling to facilitate fine-grained control over emotion rendering at the phoneme, word, and utterance levels. We introduce a hierarchical emotion distribution (ED) extractor that captures a quantifiable ED embedding across different speech segment levels. Additionally, we explore various acoustic features and assess their impact on emotion intensity modeling. During TTS training, the hierarchical ED embedding effectively captures the variance in emotion intensity from the reference audio and correlates it with linguistic and speaker information. The TTS model not only generates emotional speech during inference, but also quantitatively controls the emotion rendering over the speech constituents. Both objective and subjective evaluations demonstrate the effectiveness of our framework in terms of speech quality, emotional expressiveness, and hierarchical emotion control.
RETQA: A Large-Scale Open-Domain Tabular Question Answering Dataset for Real Estate Sector
Dec 13, 2024



The real estate market relies heavily on structured data, such as property details, market trends, and price fluctuations. However, the lack of specialized Tabular Question Answering datasets in this domain limits the development of automated question-answering systems. To fill this gap, we introduce RETQA, the first large-scale open-domain Chinese Tabular Question Answering dataset for Real Estate. RETQA comprises 4,932 tables and 20,762 question-answer pairs across 16 sub-fields within three major domains: property information, real estate company finance information and land auction information. Compared with existing tabular question answering datasets, RETQA poses greater challenges due to three key factors: long-table structures, open-domain retrieval, and multi-domain queries. To tackle these challenges, we propose the SLUTQA framework, which integrates large language models with spoken language understanding tasks to enhance retrieval and answering accuracy. Extensive experiments demonstrate that SLUTQA significantly improves the performance of large language models on RETQA by in-context learning. RETQA and SLUTQA provide essential resources for advancing tabular question answering research in the real estate domain, addressing critical challenges in open-domain and long-table question-answering. The dataset and code are publicly available at \url{https://github.com/jensen-w/RETQA}.
MaterialPicker: Multi-Modal Material Generation with Diffusion Transformers
Dec 04, 2024



High-quality material generation is key for virtual environment authoring and inverse rendering. We propose MaterialPicker, a multi-modal material generator leveraging a Diffusion Transformer (DiT) architecture, improving and simplifying the creation of high-quality materials from text prompts and/or photographs. Our method can generate a material based on an image crop of a material sample, even if the captured surface is distorted, viewed at an angle or partially occluded, as is often the case in photographs of natural scenes. We further allow the user to specify a text prompt to provide additional guidance for the generation. We finetune a pre-trained DiT-based video generator into a material generator, where each material map is treated as a frame in a video sequence. We evaluate our approach both quantitatively and qualitatively and show that it enables more diverse material generation and better distortion correction than previous work.
Enhancing Visual Reasoning with Autonomous Imagination in Multimodal Large Language Models
Nov 27, 2024

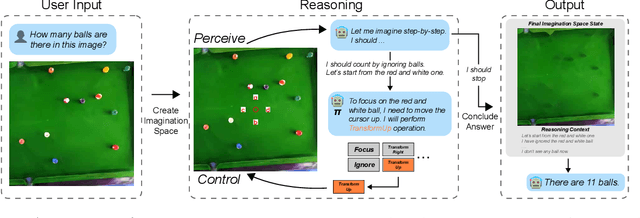

There have been recent efforts to extend the Chain-of-Thought (CoT) paradigm to Multimodal Large Language Models (MLLMs) by finding visual clues in the input scene, advancing the visual reasoning ability of MLLMs. However, current approaches are specially designed for the tasks where clue finding plays a major role in the whole reasoning process, leading to the difficulty in handling complex visual scenes where clue finding does not actually simplify the whole reasoning task. To deal with this challenge, we propose a new visual reasoning paradigm enabling MLLMs to autonomously modify the input scene to new ones based on its reasoning status, such that CoT is reformulated as conducting simple closed-loop decision-making and reasoning steps under a sequence of imagined visual scenes, leading to natural and general CoT construction. To implement this paradigm, we introduce a novel plug-and-play imagination space, where MLLMs conduct visual modifications through operations like focus, ignore, and transform based on their native reasoning ability without specific training. We validate our approach through a benchmark spanning dense counting, simple jigsaw puzzle solving, and object placement, challenging the reasoning ability beyond clue finding. The results verify that while existing techniques fall short, our approach enables MLLMs to effectively reason step by step through autonomous imagination. Project page: https://future-item.github.io/autoimagine-site.
ARM: Appearance Reconstruction Model for Relightable 3D Generation
Nov 16, 2024



Recent image-to-3D reconstruction models have greatly advanced geometry generation, but they still struggle to faithfully generate realistic appearance. To address this, we introduce ARM, a novel method that reconstructs high-quality 3D meshes and realistic appearance from sparse-view images. The core of ARM lies in decoupling geometry from appearance, processing appearance within the UV texture space. Unlike previous methods, ARM improves texture quality by explicitly back-projecting measurements onto the texture map and processing them in a UV space module with a global receptive field. To resolve ambiguities between material and illumination in input images, ARM introduces a material prior that encodes semantic appearance information, enhancing the robustness of appearance decomposition. Trained on just 8 H100 GPUs, ARM outperforms existing methods both quantitatively and qualitatively.
Self-Calibrated Listwise Reranking with Large Language Models
Nov 07, 2024



Large language models (LLMs), with advanced linguistic capabilities, have been employed in reranking tasks through a sequence-to-sequence approach. In this paradigm, multiple passages are reranked in a listwise manner and a textual reranked permutation is generated. However, due to the limited context window of LLMs, this reranking paradigm requires a sliding window strategy to iteratively handle larger candidate sets. This not only increases computational costs but also restricts the LLM from fully capturing all the comparison information for all candidates. To address these challenges, we propose a novel self-calibrated listwise reranking method, which aims to leverage LLMs to produce global relevance scores for ranking. To achieve it, we first propose the relevance-aware listwise reranking framework, which incorporates explicit list-view relevance scores to improve reranking efficiency and enable global comparison across the entire candidate set. Second, to ensure the comparability of the computed scores, we propose self-calibrated training that uses point-view relevance assessments generated internally by the LLM itself to calibrate the list-view relevance assessments. Extensive experiments and comprehensive analysis on the BEIR benchmark and TREC Deep Learning Tracks demonstrate the effectiveness and efficiency of our proposed method.
Exploring the Design Space of Visual Context Representation in Video MLLMs
Oct 17, 2024



Video Multimodal Large Language Models (MLLMs) have shown remarkable capability of understanding the video semantics on various downstream tasks. Despite the advancements, there is still a lack of systematic research on visual context representation, which refers to the scheme to select frames from a video and further select the tokens from a frame. In this paper, we explore the design space for visual context representation, and aim to improve the performance of video MLLMs by finding more effective representation schemes. Firstly, we formulate the task of visual context representation as a constrained optimization problem, and model the language modeling loss as a function of the number of frames and the number of embeddings (or tokens) per frame, given the maximum visual context window size. Then, we explore the scaling effects in frame selection and token selection respectively, and fit the corresponding function curve by conducting extensive empirical experiments. We examine the effectiveness of typical selection strategies and present empirical findings to determine the two factors. Furthermore, we study the joint effect of frame selection and token selection, and derive the optimal formula for determining the two factors. We demonstrate that the derived optimal settings show alignment with the best-performed results of empirical experiments. Our code and model are available at: https://github.com/RUCAIBox/Opt-Visor.
GS^3: Efficient Relighting with Triple Gaussian Splatting
Oct 15, 2024We present a spatial and angular Gaussian based representation and a triple splatting process, for real-time, high-quality novel lighting-and-view synthesis from multi-view point-lit input images. To describe complex appearance, we employ a Lambertian plus a mixture of angular Gaussians as an effective reflectance function for each spatial Gaussian. To generate self-shadow, we splat all spatial Gaussians towards the light source to obtain shadow values, which are further refined by a small multi-layer perceptron. To compensate for other effects like global illumination, another network is trained to compute and add a per-spatial-Gaussian RGB tuple. The effectiveness of our representation is demonstrated on 30 samples with a wide variation in geometry (from solid to fluffy) and appearance (from translucent to anisotropic), as well as using different forms of input data, including rendered images of synthetic/reconstructed objects, photographs captured with a handheld camera and a flash, or from a professional lightstage. We achieve a training time of 40-70 minutes and a rendering speed of 90 fps on a single commodity GPU. Our results compare favorably with state-of-the-art techniques in terms of quality/performance. Our code and data are publicly available at https://GSrelight.github.io/.
* Accepted to SIGGRAPH Asia 2024. Project page: https://gsrelight.github.io/