 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeODTQA-FoRe: An Open-Domain Tabular Question Answering Dataset for Future Data Forecasting and Reasoning
Jun 01, 2026The rapid development of LLMs has significantly advanced tabular question answering, but most systems cannot perform future-oriented numerical prediction. To address this gap, we introduce a novel task, Open-Domain Tabular Question Answering for Future Data Forecasting and Reasoning, and propose the first dataset to cover time-series forecasting and forecast-based reasoning scenarios using real estate data. This task poses challenges in retrieving precise historical data, overcoming the forecasting limitations of LLMs, and standardizing responses for diverse queries. To solve the above challenges, we propose TimeFore, an LLM agent-based framework that decomposes the problem into three collaborative roles: a Retriever autonomously generates SQL to fetch data, a Forecaster invokes external time-series models for higher accuracy, and an Analyzer synthesizes the results to construct a precise and consistent final answer. Extensive experiments demonstrate the effectiveness of our TimeFore.
ReCoQA: A Benchmark for Tool-Augmented and Multi-Step Reasoning in Real Estate Question and Answering
Apr 20, 2026Developing agents capable of navigating fragmented, multi-source information remains challenging, primarily due to the scarcity of benchmarks reflecting hybrid workflows combining database querying with external APIs. To bridge this gap, we introduce ReCoQA, a large-scale benchmark of 29,270 real-estate instances featuring machine-verifiable supervision for intermediate steps, including structured intent labels, SQL queries, and API calls. Complementarily, we propose HIRE-Agent, a hierarchical framework instantiating an understand-plan-execute architecture as a strong baseline. By orchestrating a Front-end parser, a planning Supervisor, and execution Specialists, HIRE-Agent effectively integrates heterogeneous evidence. Extensive experiments demonstrate that HIRE-Agent constitutes a strong baseline and substantiates the necessity of hierarchical collaboration for complex, real-world reasoning tasks.
Automatic Slide Updating with User-Defined Dynamic Templates and Natural Language Instructions
Apr 20, 2026Presentation slides are a primary medium for data-driven reporting, yet keeping complex, analytics-style decks up to date remains labor-intensive. Existing automation methods mostly follow fixed template filling and cannot support dynamic updates for diverse, user-authored slide decks. We therefore define "Dynamic Slide Update via Natural Language Instructions on User-provided Templates" and introduce DynaSlide, a large-scale benchmark with 20,036 real-world instruction-execution triples (source slide, user instruction, target slide) grounded in a shared external database and built from business reporting slides under bring-your-own-template (BYO-template) conditions. To tackle this task, we propose SlideAgent, an agent-based framework that combines multimodal slide parsing, natural language instruction grounding, and tool-augmented reasoning for tables, charts, and textual conclusions. SlideAgent updates content while preserving layout and style, providing a strong reference baseline on DynaSlide. We further design end-to-end and component-level evaluation protocols that reveal key challenges and opportunities for future research. The dataset and code are available at https://github.com/XiaoZhou2024/SlideAgent.
ODUTQA-MDC: A Task for Open-Domain Underspecified Tabular QA with Multi-turn Dialogue-based Clarification
Apr 11, 2026The advancement of large language models (LLMs) has enhanced tabular question answering (Tabular QA), yet they struggle with open-domain queries exhibiting underspecified or uncertain expressions. To address this, we introduce the ODUTQA-MDC task and the first comprehensive benchmark to tackle it. This benchmark includes: (1) a large-scale ODUTQA dataset with 209 tables and 25,105 QA pairs; (2) a fine-grained labeling scheme for detailed evaluation; and (3) a dynamic clarification interface that simulates user feedback for interactive assessment. We also propose MAIC-TQA, a multi-agent framework that excels at detecting ambiguities, clarifying them through dialogue, and refining answers. Experiments validate our benchmark and framework, establishing them as a key resource for advancing conversational, underspecification-aware Tabular QA research.
RETQA: A Large-Scale Open-Domain Tabular Question Answering Dataset for Real Estate Sector
Dec 13, 2024



The real estate market relies heavily on structured data, such as property details, market trends, and price fluctuations. However, the lack of specialized Tabular Question Answering datasets in this domain limits the development of automated question-answering systems. To fill this gap, we introduce RETQA, the first large-scale open-domain Chinese Tabular Question Answering dataset for Real Estate. RETQA comprises 4,932 tables and 20,762 question-answer pairs across 16 sub-fields within three major domains: property information, real estate company finance information and land auction information. Compared with existing tabular question answering datasets, RETQA poses greater challenges due to three key factors: long-table structures, open-domain retrieval, and multi-domain queries. To tackle these challenges, we propose the SLUTQA framework, which integrates large language models with spoken language understanding tasks to enhance retrieval and answering accuracy. Extensive experiments demonstrate that SLUTQA significantly improves the performance of large language models on RETQA by in-context learning. RETQA and SLUTQA provide essential resources for advancing tabular question answering research in the real estate domain, addressing critical challenges in open-domain and long-table question-answering. The dataset and code are publicly available at \url{https://github.com/jensen-w/RETQA}.
A deep Convolutional Neural Network for topology optimization with strong generalization ability
Jan 23, 2019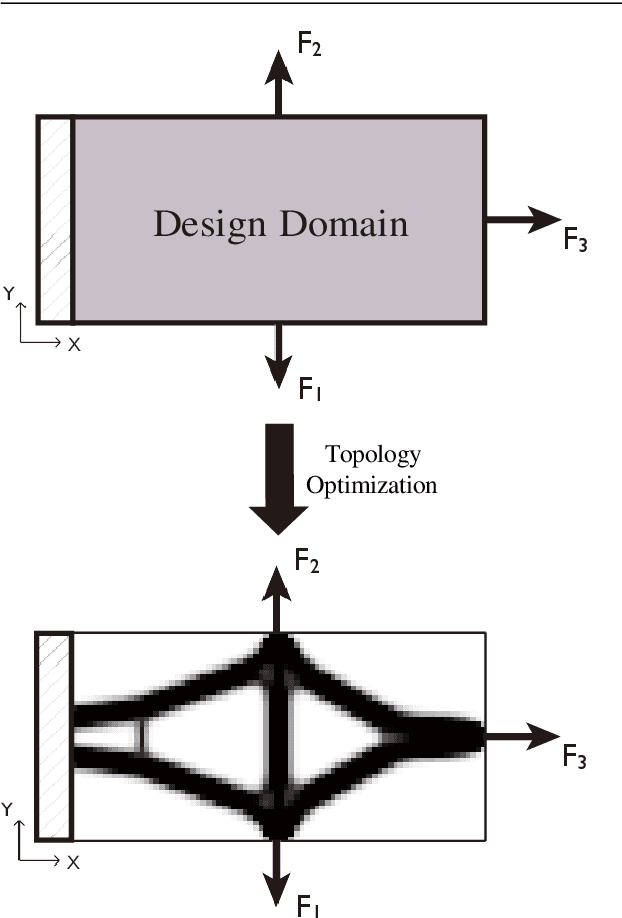
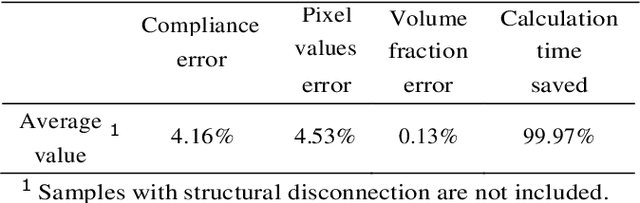
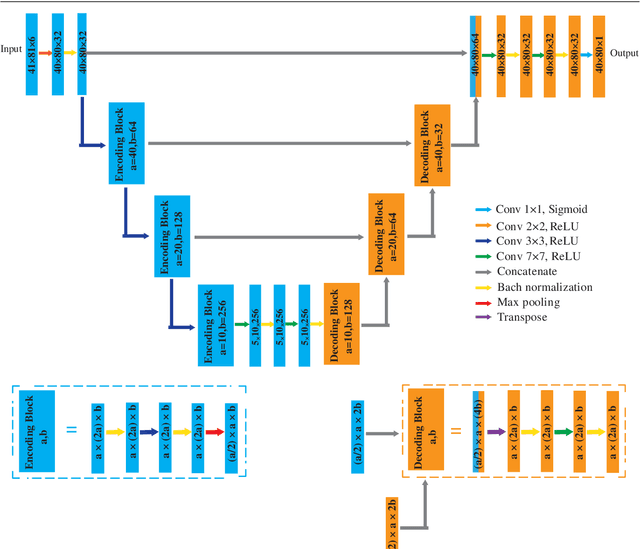

This paper proposes a deep Convolutional Neural Network(CNN) with strong generalization ability for structural topology optimization. The architecture of the neural network is made up of encoding and decoding parts, which provide down- and up-sampling operations. In addition, a popular technique, namely U-Net, was adopted to improve the performance of the proposed neural network. The input of the neural network is a well-designed tensor with each channel includes different information for the problem, and the output is the layout of the optimal structure. To train the neural network, a large dataset is generated by a conventional topology optimization approach, i.e. SIMP. The performance of the proposed method was evaluated by comparing its efficiency and accuracy with SIMP on a series of typical optimization problems. Results show that a significant reduction in computation cost was achieved with little sacrifice on the optimality of design solutions. Furthermore, the proposed method can intelligently solve problems under boundary conditions not being included in the training dataset.