 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeODTQA-FoRe: An Open-Domain Tabular Question Answering Dataset for Future Data Forecasting and Reasoning
Jun 01, 2026The rapid development of LLMs has significantly advanced tabular question answering, but most systems cannot perform future-oriented numerical prediction. To address this gap, we introduce a novel task, Open-Domain Tabular Question Answering for Future Data Forecasting and Reasoning, and propose the first dataset to cover time-series forecasting and forecast-based reasoning scenarios using real estate data. This task poses challenges in retrieving precise historical data, overcoming the forecasting limitations of LLMs, and standardizing responses for diverse queries. To solve the above challenges, we propose TimeFore, an LLM agent-based framework that decomposes the problem into three collaborative roles: a Retriever autonomously generates SQL to fetch data, a Forecaster invokes external time-series models for higher accuracy, and an Analyzer synthesizes the results to construct a precise and consistent final answer. Extensive experiments demonstrate the effectiveness of our TimeFore.
Automatic Slide Updating with User-Defined Dynamic Templates and Natural Language Instructions
Apr 20, 2026Presentation slides are a primary medium for data-driven reporting, yet keeping complex, analytics-style decks up to date remains labor-intensive. Existing automation methods mostly follow fixed template filling and cannot support dynamic updates for diverse, user-authored slide decks. We therefore define "Dynamic Slide Update via Natural Language Instructions on User-provided Templates" and introduce DynaSlide, a large-scale benchmark with 20,036 real-world instruction-execution triples (source slide, user instruction, target slide) grounded in a shared external database and built from business reporting slides under bring-your-own-template (BYO-template) conditions. To tackle this task, we propose SlideAgent, an agent-based framework that combines multimodal slide parsing, natural language instruction grounding, and tool-augmented reasoning for tables, charts, and textual conclusions. SlideAgent updates content while preserving layout and style, providing a strong reference baseline on DynaSlide. We further design end-to-end and component-level evaluation protocols that reveal key challenges and opportunities for future research. The dataset and code are available at https://github.com/XiaoZhou2024/SlideAgent.
ReCoQA: A Benchmark for Tool-Augmented and Multi-Step Reasoning in Real Estate Question and Answering
Apr 20, 2026Developing agents capable of navigating fragmented, multi-source information remains challenging, primarily due to the scarcity of benchmarks reflecting hybrid workflows combining database querying with external APIs. To bridge this gap, we introduce ReCoQA, a large-scale benchmark of 29,270 real-estate instances featuring machine-verifiable supervision for intermediate steps, including structured intent labels, SQL queries, and API calls. Complementarily, we propose HIRE-Agent, a hierarchical framework instantiating an understand-plan-execute architecture as a strong baseline. By orchestrating a Front-end parser, a planning Supervisor, and execution Specialists, HIRE-Agent effectively integrates heterogeneous evidence. Extensive experiments demonstrate that HIRE-Agent constitutes a strong baseline and substantiates the necessity of hierarchical collaboration for complex, real-world reasoning tasks.
ODUTQA-MDC: A Task for Open-Domain Underspecified Tabular QA with Multi-turn Dialogue-based Clarification
Apr 11, 2026The advancement of large language models (LLMs) has enhanced tabular question answering (Tabular QA), yet they struggle with open-domain queries exhibiting underspecified or uncertain expressions. To address this, we introduce the ODUTQA-MDC task and the first comprehensive benchmark to tackle it. This benchmark includes: (1) a large-scale ODUTQA dataset with 209 tables and 25,105 QA pairs; (2) a fine-grained labeling scheme for detailed evaluation; and (3) a dynamic clarification interface that simulates user feedback for interactive assessment. We also propose MAIC-TQA, a multi-agent framework that excels at detecting ambiguities, clarifying them through dialogue, and refining answers. Experiments validate our benchmark and framework, establishing them as a key resource for advancing conversational, underspecification-aware Tabular QA research.
TLCCSP: A Scalable Framework for Enhancing Time Series Forecasting with Time-Lagged Cross-Correlations
Aug 09, 2025



Time series forecasting is critical across various domains, such as weather, finance and real estate forecasting, as accurate forecasts support informed decision-making and risk mitigation. While recent deep learning models have improved predictive capabilities, they often overlook time-lagged cross-correlations between related sequences, which are crucial for capturing complex temporal relationships. To address this, we propose the Time-Lagged Cross-Correlations-based Sequence Prediction framework (TLCCSP), which enhances forecasting accuracy by effectively integrating time-lagged cross-correlated sequences. TLCCSP employs the Sequence Shifted Dynamic Time Warping (SSDTW) algorithm to capture lagged correlations and a contrastive learning-based encoder to efficiently approximate SSDTW distances. Experimental results on weather, finance and real estate time series datasets demonstrate the effectiveness of our framework. On the weather dataset, SSDTW reduces mean squared error (MSE) by 16.01% compared with single-sequence methods, while the contrastive learning encoder (CLE) further decreases MSE by 17.88%. On the stock dataset, SSDTW achieves a 9.95% MSE reduction, and CLE reduces it by 6.13%. For the real estate dataset, SSDTW and CLE reduce MSE by 21.29% and 8.62%, respectively. Additionally, the contrastive learning approach decreases SSDTW computational time by approximately 99%, ensuring scalability and real-time applicability across multiple time series forecasting tasks.
HiGarment: Cross-modal Harmony Based Diffusion Model for Flat Sketch to Realistic Garment Image
May 29, 2025



Diffusion-based garment synthesis tasks primarily focus on the design phase in the fashion domain, while the garment production process remains largely underexplored. To bridge this gap, we introduce a new task: Flat Sketch to Realistic Garment Image (FS2RG), which generates realistic garment images by integrating flat sketches and textual guidance. FS2RG presents two key challenges: 1) fabric characteristics are solely guided by textual prompts, providing insufficient visual supervision for diffusion-based models, which limits their ability to capture fine-grained fabric details; 2) flat sketches and textual guidance may provide conflicting information, requiring the model to selectively preserve or modify garment attributes while maintaining structural coherence. To tackle this task, we propose HiGarment, a novel framework that comprises two core components: i) a multi-modal semantic enhancement mechanism that enhances fabric representation across textual and visual modalities, and ii) a harmonized cross-attention mechanism that dynamically balances information from flat sketches and text prompts, allowing controllable synthesis by generating either sketch-aligned (image-biased) or text-guided (text-biased) outputs. Furthermore, we collect Multi-modal Detailed Garment, the largest open-source dataset for garment generation. Experimental results and user studies demonstrate the effectiveness of HiGarment in garment synthesis. The code and dataset will be released.
RETQA: A Large-Scale Open-Domain Tabular Question Answering Dataset for Real Estate Sector
Dec 13, 2024



The real estate market relies heavily on structured data, such as property details, market trends, and price fluctuations. However, the lack of specialized Tabular Question Answering datasets in this domain limits the development of automated question-answering systems. To fill this gap, we introduce RETQA, the first large-scale open-domain Chinese Tabular Question Answering dataset for Real Estate. RETQA comprises 4,932 tables and 20,762 question-answer pairs across 16 sub-fields within three major domains: property information, real estate company finance information and land auction information. Compared with existing tabular question answering datasets, RETQA poses greater challenges due to three key factors: long-table structures, open-domain retrieval, and multi-domain queries. To tackle these challenges, we propose the SLUTQA framework, which integrates large language models with spoken language understanding tasks to enhance retrieval and answering accuracy. Extensive experiments demonstrate that SLUTQA significantly improves the performance of large language models on RETQA by in-context learning. RETQA and SLUTQA provide essential resources for advancing tabular question answering research in the real estate domain, addressing critical challenges in open-domain and long-table question-answering. The dataset and code are publicly available at \url{https://github.com/jensen-w/RETQA}.
Overcoming Negative Transfer by Online Selection: Distant Domain Adaptation for Fault Diagnosis
May 25, 2024



Unsupervised domain adaptation (UDA) has achieved remarkable success in fault diagnosis, bringing significant benefits to diverse industrial applications. While most UDA methods focus on cross-working condition scenarios where the source and target domains are notably similar, real-world applications often grapple with severe domain shifts. We coin the term `distant domain adaptation problem' to describe the challenge of adapting from a labeled source domain to a significantly disparate unlabeled target domain. This problem exhibits the risk of negative transfer, where extraneous knowledge from the source domain adversely affects the target domain performance. Unfortunately, conventional UDA methods often falter in mitigating this negative transfer, leading to suboptimal performance. In response to this challenge, we propose a novel Online Selective Adversarial Alignment (OSAA) approach. Central to OSAA is its ability to dynamically identify and exclude distant source samples via an online gradient masking approach, focusing primarily on source samples that closely resemble the target samples. Furthermore, recognizing the inherent complexities in bridging the source and target domains, we construct an intermediate domain to act as a transitional domain and ease the adaptation process. Lastly, we develop a class-conditional adversarial adaptation to address the label distribution disparities while learning domain invariant representation to account for potential label distribution disparities between the domains. Through detailed experiments and ablation studies on two real-world datasets, we validate the superior performance of the OSAA method over state-of-the-art methods, underscoring its significant utility in practical scenarios with severe domain shifts.
A Scope Sensitive and Result Attentive Model for Multi-Intent Spoken Language Understanding
Nov 22, 2022



Multi-Intent Spoken Language Understanding (SLU), a novel and more complex scenario of SLU, is attracting increasing attention. Unlike traditional SLU, each intent in this scenario has its specific scope. Semantic information outside the scope even hinders the prediction, which tremendously increases the difficulty of intent detection. More seriously, guiding slot filling with these inaccurate intent labels suffers error propagation problems, resulting in unsatisfied overall performance. To solve these challenges, in this paper, we propose a novel Scope-Sensitive Result Attention Network (SSRAN) based on Transformer, which contains a Scope Recognizer (SR) and a Result Attention Network (RAN). Scope Recognizer assignments scope information to each token, reducing the distraction of out-of-scope tokens. Result Attention Network effectively utilizes the bidirectional interaction between results of slot filling and intent detection, mitigating the error propagation problem. Experiments on two public datasets indicate that our model significantly improves SLU performance (5.4\% and 2.1\% on Overall accuracy) over the state-of-the-art baseline.
Capture Salient Historical Information: A Fast and Accurate Non-Autoregressive Model for Multi-turn Spoken Language Understanding
Jun 24, 2022
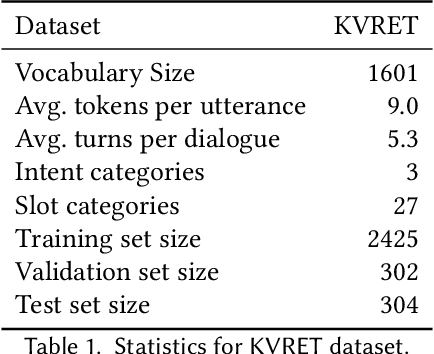
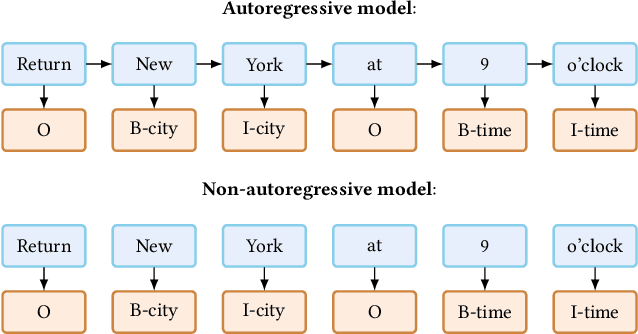
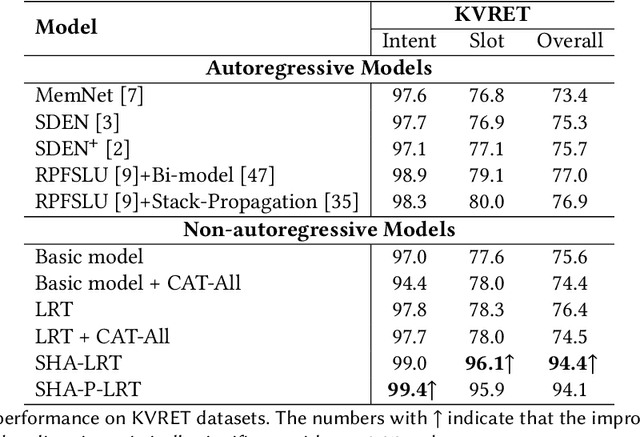
Spoken Language Understanding (SLU), a core component of the task-oriented dialogue system, expects a shorter inference facing the impatience of human users. Existing work increases inference speed by designing non-autoregressive models for single-turn SLU tasks but fails to apply to multi-turn SLU in confronting the dialogue history. The intuitive idea is to concatenate all historical utterances and utilize the non-autoregressive models directly. However, this approach seriously misses the salient historical information and suffers from the uncoordinated-slot problems. To overcome those shortcomings, we propose a novel model for multi-turn SLU named Salient History Attention with Layer-Refined Transformer (SHA-LRT), which composes of an SHA module, a Layer-Refined Mechanism (LRM), and a Slot Label Generation (SLG) task. SHA captures salient historical information for the current dialogue from both historical utterances and results via a well-designed history-attention mechanism. LRM predicts preliminary SLU results from Transformer's middle states and utilizes them to guide the final prediction, and SLG obtains the sequential dependency information for the non-autoregressive encoder. Experiments on public datasets indicate that our model significantly improves multi-turn SLU performance (17.5% on Overall) with accelerating (nearly 15 times) the inference process over the state-of-the-art baseline as well as effective on the single-turn SLU tasks.