 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePretraining Frame Preservation in Autoregressive Video Memory Compression
Dec 29, 2025We present PFP, a neural network structure to compress long videos into short contexts, with an explicit pretraining objective to preserve the high-frequency details of single frames at arbitrary temporal positions. The baseline model can compress a 20-second video into a context at about 5k length, where random frames can be retrieved with perceptually preserved appearances. Such pretrained models can be directly fine-tuned as memory encoders for autoregressive video models, enabling long history memory with low context cost and relatively low fidelity loss. We evaluate the framework with ablative settings and discuss the trade-offs of possible neural architecture designs.
RenderFormer: Transformer-based Neural Rendering of Triangle Meshes with Global Illumination
May 28, 2025We present RenderFormer, a neural rendering pipeline that directly renders an image from a triangle-based representation of a scene with full global illumination effects and that does not require per-scene training or fine-tuning. Instead of taking a physics-centric approach to rendering, we formulate rendering as a sequence-to-sequence transformation where a sequence of tokens representing triangles with reflectance properties is converted to a sequence of output tokens representing small patches of pixels. RenderFormer follows a two stage pipeline: a view-independent stage that models triangle-to-triangle light transport, and a view-dependent stage that transforms a token representing a bundle of rays to the corresponding pixel values guided by the triangle-sequence from the view-independent stage. Both stages are based on the transformer architecture and are learned with minimal prior constraints. We demonstrate and evaluate RenderFormer on scenes with varying complexity in shape and light transport.
* Accepted to SIGGRAPH 2025. Project page: https://microsoft.github.io/renderformer
GS^3: Efficient Relighting with Triple Gaussian Splatting
Oct 15, 2024



We present a spatial and angular Gaussian based representation and a triple splatting process, for real-time, high-quality novel lighting-and-view synthesis from multi-view point-lit input images. To describe complex appearance, we employ a Lambertian plus a mixture of angular Gaussians as an effective reflectance function for each spatial Gaussian. To generate self-shadow, we splat all spatial Gaussians towards the light source to obtain shadow values, which are further refined by a small multi-layer perceptron. To compensate for other effects like global illumination, another network is trained to compute and add a per-spatial-Gaussian RGB tuple. The effectiveness of our representation is demonstrated on 30 samples with a wide variation in geometry (from solid to fluffy) and appearance (from translucent to anisotropic), as well as using different forms of input data, including rendered images of synthetic/reconstructed objects, photographs captured with a handheld camera and a flash, or from a professional lightstage. We achieve a training time of 40-70 minutes and a rendering speed of 90 fps on a single commodity GPU. Our results compare favorably with state-of-the-art techniques in terms of quality/performance. Our code and data are publicly available at https://GSrelight.github.io/.
* Accepted to SIGGRAPH Asia 2024. Project page: https://gsrelight.github.io/
MeshFormer: High-Quality Mesh Generation with 3D-Guided Reconstruction Model
Aug 19, 2024



Open-world 3D reconstruction models have recently garnered significant attention. However, without sufficient 3D inductive bias, existing methods typically entail expensive training costs and struggle to extract high-quality 3D meshes. In this work, we introduce MeshFormer, a sparse-view reconstruction model that explicitly leverages 3D native structure, input guidance, and training supervision. Specifically, instead of using a triplane representation, we store features in 3D sparse voxels and combine transformers with 3D convolutions to leverage an explicit 3D structure and projective bias. In addition to sparse-view RGB input, we require the network to take input and generate corresponding normal maps. The input normal maps can be predicted by 2D diffusion models, significantly aiding in the guidance and refinement of the geometry's learning. Moreover, by combining Signed Distance Function (SDF) supervision with surface rendering, we directly learn to generate high-quality meshes without the need for complex multi-stage training processes. By incorporating these explicit 3D biases, MeshFormer can be trained efficiently and deliver high-quality textured meshes with fine-grained geometric details. It can also be integrated with 2D diffusion models to enable fast single-image-to-3D and text-to-3D tasks. Project page: https://meshformer3d.github.io
DiLightNet: Fine-grained Lighting Control for Diffusion-based Image Generation
Feb 19, 2024



This paper presents a novel method for exerting fine-grained lighting control during text-driven diffusion-based image generation. While existing diffusion models already have the ability to generate images under any lighting condition, without additional guidance these models tend to correlate image content and lighting. Moreover, text prompts lack the necessary expressional power to describe detailed lighting setups. To provide the content creator with fine-grained control over the lighting during image generation, we augment the text-prompt with detailed lighting information in the form of radiance hints, i.e., visualizations of the scene geometry with a homogeneous canonical material under the target lighting. However, the scene geometry needed to produce the radiance hints is unknown. Our key observation is that we only need to guide the diffusion process, hence exact radiance hints are not necessary; we only need to point the diffusion model in the right direction. Based on this observation, we introduce a three stage method for controlling the lighting during image generation. In the first stage, we leverage a standard pretrained diffusion model to generate a provisional image under uncontrolled lighting. Next, in the second stage, we resynthesize and refine the foreground object in the generated image by passing the target lighting to a refined diffusion model, named DiLightNet, using radiance hints computed on a coarse shape of the foreground object inferred from the provisional image. To retain the texture details, we multiply the radiance hints with a neural encoding of the provisional synthesized image before passing it to DiLightNet. Finally, in the third stage, we resynthesize the background to be consistent with the lighting on the foreground object. We demonstrate and validate our lighting controlled diffusion model on a variety of text prompts and lighting conditions.
One-2-3-45++: Fast Single Image to 3D Objects with Consistent Multi-View Generation and 3D Diffusion
Nov 14, 2023



Recent advancements in open-world 3D object generation have been remarkable, with image-to-3D methods offering superior fine-grained control over their text-to-3D counterparts. However, most existing models fall short in simultaneously providing rapid generation speeds and high fidelity to input images - two features essential for practical applications. In this paper, we present One-2-3-45++, an innovative method that transforms a single image into a detailed 3D textured mesh in approximately one minute. Our approach aims to fully harness the extensive knowledge embedded in 2D diffusion models and priors from valuable yet limited 3D data. This is achieved by initially finetuning a 2D diffusion model for consistent multi-view image generation, followed by elevating these images to 3D with the aid of multi-view conditioned 3D native diffusion models. Extensive experimental evaluations demonstrate that our method can produce high-quality, diverse 3D assets that closely mirror the original input image. Our project webpage: https://sudo-ai-3d.github.io/One2345plus_page.
Zero123++: a Single Image to Consistent Multi-view Diffusion Base Model
Oct 23, 2023



We report Zero123++, an image-conditioned diffusion model for generating 3D-consistent multi-view images from a single input view. To take full advantage of pretrained 2D generative priors, we develop various conditioning and training schemes to minimize the effort of finetuning from off-the-shelf image diffusion models such as Stable Diffusion. Zero123++ excels in producing high-quality, consistent multi-view images from a single image, overcoming common issues like texture degradation and geometric misalignment. Furthermore, we showcase the feasibility of training a ControlNet on Zero123++ for enhanced control over the generation process. The code is available at https://github.com/SUDO-AI-3D/zero123plus.
Relighting Neural Radiance Fields with Shadow and Highlight Hints
Aug 25, 2023



This paper presents a novel neural implicit radiance representation for free viewpoint relighting from a small set of unstructured photographs of an object lit by a moving point light source different from the view position. We express the shape as a signed distance function modeled by a multi layer perceptron. In contrast to prior relightable implicit neural representations, we do not disentangle the different reflectance components, but model both the local and global reflectance at each point by a second multi layer perceptron that, in addition, to density features, the current position, the normal (from the signed distace function), view direction, and light position, also takes shadow and highlight hints to aid the network in modeling the corresponding high frequency light transport effects. These hints are provided as a suggestion, and we leave it up to the network to decide how to incorporate these in the final relit result. We demonstrate and validate our neural implicit representation on synthetic and real scenes exhibiting a wide variety of shapes, material properties, and global illumination light transport.
* Accepted to SIGGRAPH 2023. Author's version. Project page: https://nrhints.github.io/
DiFT: Differentiable Differential Feature Transform for Multi-View Stereo
Mar 16, 2022
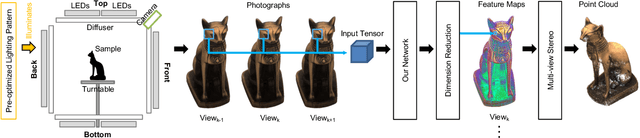
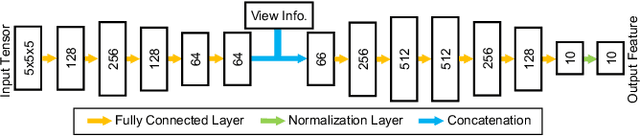

We present a novel framework to automatically learn to transform the differential cues from a stack of images densely captured with a rotational motion into spatially discriminative and view-invariant per-pixel features at each view. These low-level features can be directly fed to any existing multi-view stereo technique for enhanced 3D reconstruction. The lighting condition during acquisition can also be jointly optimized in a differentiable fashion. We sample from a dozen of pre-scanned objects with a wide variety of geometry and reflectance to synthesize a large amount of high-quality training data. The effectiveness of our features is demonstrated on a number of challenging objects acquired with a lightstage, comparing favorably with state-of-the-art techniques. Finally, we explore additional applications of geometric detail visualization and computational stylization of complex appearance.