 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse-to-Complete: From Sparse Image Captures to Complete 3D Scenes
May 07, 2026We introduce S2C-3D, a novel sparse-view 3D reconstruction framework for high-fidelity and complete scene reconstruction from as few as six to eight images. Our framework features three components: a specialized diffusion model for scene-specific image restoration, a training-free view-consistency conditioned sampling process in the diffusion model for refined Gaussian optimization, and a camera trajectory planning scheme to ensure comprehensive scene coverage. The specialized diffusion model is developed by finetuning a pretrained architecture on the input views and their corresponding degraded counterparts. The adaptation to the scene distribution allows the model to repair Gaussian renderings while effectively eliminating domain gaps. Meanwhile, the trajectory planning scheme optimizes scene coverage by connecting each newly sampled camera to its two nearest neighbors. By iteratively constructing paths and retaining only those that significantly enhance visibility, the scheme establishes a trajectory that covers the entire scene. To address multi-view conflicts, the view-consistency conditioned sampling process quantifies the consistency between neighboring repaired images. This information is injected as a condition into the sampling process of the frozen diffusion model, facilitating the generation of view-consistent images without additional training. Consequently, our approach produces high-fidelity 3D Gaussians that are robust to artifacts. Experimental results demonstrate that S2C-3D outperforms state-of-the-art methods, constructing high-quality scenes that are free from missing regions, blurring, or other artifacts with very sparse inputs. The source code and data are available at https://gapszju.github.io/S2C-3D.
High-Fidelity Mobile Avatars with Pruned Local Blendshapes
May 03, 2026We propose a method to reconstruct high-fidelity human avatars from multi-view video that can run on mobile devices. Many works can model high-quality Gaussian-based full-body avatars from multi-view video. However, these methods require heavy computation to obtain pose-dependent appearance, making deployment on mobile devices very difficult. Recent methods distill from pretrained models and model pose-dependent nonlinear Gaussian attributes by linearly combining global pose features with blendshapes. Although they can run on mobile devices, they suffer some loss of detail. We observe that nearby Gaussians are often highly correlated within a local region of the body, and can be linearly modeled with less error. Therefore, we use local linear blendshapes in small body parts to capture global nonlinear changes of Gaussian attributes. To further reduce computation and model size, we propose to remove blendshapes for Gaussians whose attributes change little, yielding a minimal blendshape representation. Our method is an end-to-end training method without a pretrained model. To make it run on multiple devices, we implement our method using WebGPU. Experiments show that our method can render high-quality human avatars with better details, and can reach 120 FPS at 2K resolution on mobile devices.
Direct Object-Level Reconstruction via Probabilistic Gaussian Splatting
Mar 15, 2026Object-level 3D reconstruction play important roles across domains such as cultural heritage digitization, industrial manufacturing, and virtual reality. However, existing Gaussian Splatting-based approaches generally rely on full-scene reconstruction, in which substantial redundant background information is introduced, leading to increased computational and storage overhead. To address this limitation, we propose an efficient single-object 3D reconstruction method based on 2D Gaussian Splatting. By directly integrating foreground-background probability cues into Gaussian primitives and dynamically pruning low-probability Gaussians during training, the proposed method fundamentally focuses on an object of interest and improves the memory and computational efficiency. Our pipeline leverages probability masks generated by YOLO and SAM to supervise probabilistic Gaussian attributes, replacing binary masks with continuous probability values to mitigate boundary ambiguity. Additionally, we propose a dual-stage filtering strategy for training's startup to suppress background Gaussians. And, during training, rendered probability masks are conversely employed to refine supervision and enhance boundary consistency across views. Experiments conducted on the MIP-360, T&T, and NVOS datasets demonstrate that our method exhibits strong self-correction capability in the presence of mask errors and achieves reconstruction quality comparable to standard 3DGS approaches, while requiring only approximately 1/10 of their Gaussian amount. These results validate the efficiency and robustness of our method for single-object reconstruction and highlight its potential for applications requiring both high fidelity and computational efficiency.
Slot-ID: Identity-Preserving Video Generation from Reference Videos via Slot-Based Temporal Identity Encoding
Jan 04, 2026Producing prompt-faithful videos that preserve a user-specified identity remains challenging: models need to extrapolate facial dynamics from sparse reference while balancing the tension between identity preservation and motion naturalness. Conditioning on a single image completely ignores the temporal signature, which leads to pose-locked motions, unnatural warping, and "average" faces when viewpoints and expressions change. To this end, we introduce an identity-conditioned variant of a diffusion-transformer video generator which uses a short reference video rather than a single portrait. Our key idea is to incorporate the dynamics in the reference. A short clip reveals subject-specific patterns, e.g., how smiles form, across poses and lighting. From this clip, a Sinkhorn-routed encoder learns compact identity tokens that capture characteristic dynamics while remaining pretrained backbone-compatible. Despite adding only lightweight conditioning, the approach consistently improves identity retention under large pose changes and expressive facial behavior, while maintaining prompt faithfulness and visual realism across diverse subjects and prompts.
TR-Gaussians: High-fidelity Real-time Rendering of Planar Transmission and Reflection with 3D Gaussian Splatting
Nov 17, 2025We propose Transmission-Reflection Gaussians (TR-Gaussians), a novel 3D-Gaussian-based representation for high-fidelity rendering of planar transmission and reflection, which are ubiquitous in indoor scenes. Our method combines 3D Gaussians with learnable reflection planes that explicitly model the glass planes with view-dependent reflectance strengths. Real scenes and transmission components are modeled by 3D Gaussians and the reflection components are modeled by the mirrored Gaussians with respect to the reflection plane. The transmission and reflection components are blended according to a Fresnel-based, view-dependent weighting scheme, allowing for faithful synthesis of complex appearance effects under varying viewpoints. To effectively optimize TR-Gaussians, we develop a multi-stage optimization framework incorporating color and geometry constraints and an opacity perturbation mechanism. Experiments on different datasets demonstrate that TR-Gaussians achieve real-time, high-fidelity novel view synthesis in scenes with planar transmission and reflection, and outperform state-of-the-art approaches both quantitatively and qualitatively.
When Gaussian Meets Surfel: Ultra-fast High-fidelity Radiance Field Rendering
Apr 24, 2025We introduce Gaussian-enhanced Surfels (GESs), a bi-scale representation for radiance field rendering, wherein a set of 2D opaque surfels with view-dependent colors represent the coarse-scale geometry and appearance of scenes, and a few 3D Gaussians surrounding the surfels supplement fine-scale appearance details. The rendering with GESs consists of two passes -- surfels are first rasterized through a standard graphics pipeline to produce depth and color maps, and then Gaussians are splatted with depth testing and color accumulation on each pixel order independently. The optimization of GESs from multi-view images is performed through an elaborate coarse-to-fine procedure, faithfully capturing rich scene appearance. The entirely sorting-free rendering of GESs not only achieves very fast rates, but also produces view-consistent images, successfully avoiding popping artifacts under view changes. The basic GES representation can be easily extended to achieve anti-aliasing in rendering (Mip-GES), boosted rendering speeds (Speedy-GES) and compact storage (Compact-GES), and reconstruct better scene geometries by replacing 3D Gaussians with 2D Gaussians (2D-GES). Experimental results show that GESs advance the state-of-the-arts as a compelling representation for ultra-fast high-fidelity radiance field rendering.
Real-time High-fidelity Gaussian Human Avatars with Position-based Interpolation of Spatially Distributed MLPs
Apr 17, 2025



Many works have succeeded in reconstructing Gaussian human avatars from multi-view videos. However, they either struggle to capture pose-dependent appearance details with a single MLP, or rely on a computationally intensive neural network to reconstruct high-fidelity appearance but with rendering performance degraded to non-real-time. We propose a novel Gaussian human avatar representation that can reconstruct high-fidelity pose-dependence appearance with details and meanwhile can be rendered in real time. Our Gaussian avatar is empowered by spatially distributed MLPs which are explicitly located on different positions on human body. The parameters stored in each Gaussian are obtained by interpolating from the outputs of its nearby MLPs based on their distances. To avoid undesired smooth Gaussian property changing during interpolation, for each Gaussian we define a set of Gaussian offset basis, and a linear combination of basis represents the Gaussian property offsets relative to the neutral properties. Then we propose to let the MLPs output a set of coefficients corresponding to the basis. In this way, although Gaussian coefficients are derived from interpolation and change smoothly, the Gaussian offset basis is learned freely without constraints. The smoothly varying coefficients combined with freely learned basis can still produce distinctly different Gaussian property offsets, allowing the ability to learn high-frequency spatial signals. We further use control points to constrain the Gaussians distributed on a surface layer rather than allowing them to be irregularly distributed inside the body, to help the human avatar generalize better when animated under novel poses. Compared to the state-of-the-art method, our method achieves better appearance quality with finer details while the rendering speed is significantly faster under novel views and novel poses.
High-fidelity 3D Object Generation from Single Image with RGBN-Volume Gaussian Reconstruction Model
Apr 02, 2025Recently single-view 3D generation via Gaussian splatting has emerged and developed quickly. They learn 3D Gaussians from 2D RGB images generated from pre-trained multi-view diffusion (MVD) models, and have shown a promising avenue for 3D generation through a single image. Despite the current progress, these methods still suffer from the inconsistency jointly caused by the geometric ambiguity in the 2D images, and the lack of structure of 3D Gaussians, leading to distorted and blurry 3D object generation. In this paper, we propose to fix these issues by GS-RGBN, a new RGBN-volume Gaussian Reconstruction Model designed to generate high-fidelity 3D objects from single-view images. Our key insight is a structured 3D representation can simultaneously mitigate the afore-mentioned two issues. To this end, we propose a novel hybrid Voxel-Gaussian representation, where a 3D voxel representation contains explicit 3D geometric information, eliminating the geometric ambiguity from 2D images. It also structures Gaussians during learning so that the optimization tends to find better local optima. Our 3D voxel representation is obtained by a fusion module that aligns RGB features and surface normal features, both of which can be estimated from 2D images. Extensive experiments demonstrate the superiority of our methods over prior works in terms of high-quality reconstruction results, robust generalization, and good efficiency.
Enhancing Visual Reasoning with Autonomous Imagination in Multimodal Large Language Models
Nov 27, 2024

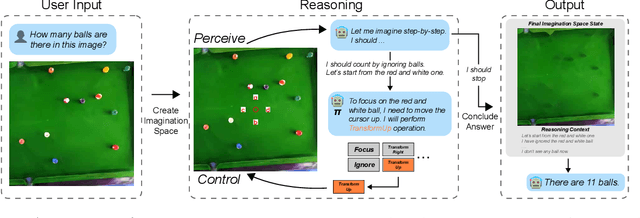

There have been recent efforts to extend the Chain-of-Thought (CoT) paradigm to Multimodal Large Language Models (MLLMs) by finding visual clues in the input scene, advancing the visual reasoning ability of MLLMs. However, current approaches are specially designed for the tasks where clue finding plays a major role in the whole reasoning process, leading to the difficulty in handling complex visual scenes where clue finding does not actually simplify the whole reasoning task. To deal with this challenge, we propose a new visual reasoning paradigm enabling MLLMs to autonomously modify the input scene to new ones based on its reasoning status, such that CoT is reformulated as conducting simple closed-loop decision-making and reasoning steps under a sequence of imagined visual scenes, leading to natural and general CoT construction. To implement this paradigm, we introduce a novel plug-and-play imagination space, where MLLMs conduct visual modifications through operations like focus, ignore, and transform based on their native reasoning ability without specific training. We validate our approach through a benchmark spanning dense counting, simple jigsaw puzzle solving, and object placement, challenging the reasoning ability beyond clue finding. The results verify that while existing techniques fall short, our approach enables MLLMs to effectively reason step by step through autonomous imagination. Project page: https://future-item.github.io/autoimagine-site.
Enabling Synergistic Full-Body Control in Prompt-Based Co-Speech Motion Generation
Oct 01, 2024



Current co-speech motion generation approaches usually focus on upper body gestures following speech contents only, while lacking supporting the elaborate control of synergistic full-body motion based on text prompts, such as talking while walking. The major challenges lie in 1) the existing speech-to-motion datasets only involve highly limited full-body motions, making a wide range of common human activities out of training distribution; 2) these datasets also lack annotated user prompts. To address these challenges, we propose SynTalker, which utilizes the off-the-shelf text-to-motion dataset as an auxiliary for supplementing the missing full-body motion and prompts. The core technical contributions are two-fold. One is the multi-stage training process which obtains an aligned embedding space of motion, speech, and prompts despite the significant distributional mismatch in motion between speech-to-motion and text-to-motion datasets. Another is the diffusion-based conditional inference process, which utilizes the separate-then-combine strategy to realize fine-grained control of local body parts. Extensive experiments are conducted to verify that our approach supports precise and flexible control of synergistic full-body motion generation based on both speeches and user prompts, which is beyond the ability of existing approaches.