 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDive into the Scene: Breaking the Perceptual Bottleneck in Vision-Language Decision Making via Focus Plan Generation
Jun 02, 2026In embodied vision-language decision making tasks such as robotic manipulation and navigation, Vision-Language and Vision-Language-Action Models (VLMs & VLAs) are powerful tools with different benefits: VLMs are better at long-term planning, while VLAs are better at reactive control. However, their performance is limited by the same perceptual bottleneck: visual hallucinations arise due to the models' inability to distinguish task-relevant objects from distractors. In principle, accurate identification and focus on critical objects while filtering out irrelevant ones is the key to break this limitation. A straightforward solution is one-step focus: directly attending to essential objects. However, this approach proves ineffective because effective focus inherently requires deep scene understanding. To this end, we propose SceneDiver, a coarse-to-fine focus plan generation method for VLMs leveraging their long-term planning abilities, that first constructs a holistic scene graph to establish initial comprehension, then progressively decomposes the task into simpler sub-problems through an iterative cycle of recognition, understanding, and analysis. To enable reactive control, we also design a lightweight adapter for distilling the deliberate focus ability into VLAs. Evaluations on standard embodied AI benchmarks confirm that our method substantially reduces visual hallucinations for both VLMs and VLAs, while preserving computational efficiency in tasks requiring fast execution. Our code and data are released at: https://future-item.github.io/SceneDiver.
Tree-Guided Identify-Then-Exploit: A Unified Framework of Best Arm Identification and Regret Minimization for Dueling Bandits
Jun 01, 2026We study $N$-armed stochastic dueling bandits under the Condorcet-winner assumption, where three widely adopted objectives are considered: best-arm identification (BAI), weak regret, and strong regret. We propose Tree-Guided Identify-Then-Exploit (TG-ITE), the first unified framework to tackle all these objectives to our knowledge. Without requiring stronger assumptions, we propose a shared tree-guided identification approach to find a high-confidence incumbent within $O(N)$ comparisons. We further propose varied exploitation strategies to utilize this warm-start stage to optimize the specific objectives at hand. This methodology enables our approach to (1) achieve $O(N)$ sample complexity in BAI without commonly adopted stronger assumptions; (2) build the first winner-stays-style algorithm to achieve $O(N)$ weak regret; (3) enjoy the same $O(N \log T)$ guarantee as specialized strong-regret approaches; (4) realize the joint optimization of BAI and weak regret with $O(N)$ guarantees for both, eliminating the sub-optimal gap of $O(\log N)$ in the existing approach. Our results provide evidence that the trade-off between BAI and regret minimization is relatively benign in dueling bandits.
OrigamiBench: An Interactive Environment to Synthesize Flat-Foldable Origamis
Mar 17, 2026Building AI systems that can plan, act, and create in the physical world requires more than pattern recognition. Such systems must understand the causal mechanisms and constraints governing physical processes in order to guide sequential decisions. This capability relies on internal representations, analogous to an internal language model, that relate observations, actions, and resulting environmental changes. However, many existing benchmarks treat visual perception and programmatic reasoning as separate problems, focusing either on visual recognition or on symbolic tasks. The domain of origami provides a natural testbed that integrates these modalities. Constructing shapes through folding operations requires visual perception, reasoning about geometric and physical constraints, and sequential planning, while remaining sufficiently structured for systematic evaluation. We introduce OrigamiBench, an interactive benchmark in which models iteratively propose folds and receive feedback on physical validity and similarity to a target configuration. Experiments with modern vision-language models show that scaling model size alone does not reliably produce causal reasoning about physical transformations. Models fail to generate coherent multi-step folding strategies, suggesting that visual and language representations remain weakly integrated.
Motion-example-controlled Co-speech Gesture Generation Leveraging Large Language Models
Jul 27, 2025The automatic generation of controllable co-speech gestures has recently gained growing attention. While existing systems typically achieve gesture control through predefined categorical labels or implicit pseudo-labels derived from motion examples, these approaches often compromise the rich details present in the original motion examples. We present MECo, a framework for motion-example-controlled co-speech gesture generation by leveraging large language models (LLMs). Our method capitalizes on LLMs' comprehension capabilities through fine-tuning to simultaneously interpret speech audio and motion examples, enabling the synthesis of gestures that preserve example-specific characteristics while maintaining speech congruence. Departing from conventional pseudo-labeling paradigms, we position motion examples as explicit query contexts within the prompt structure to guide gesture generation. Experimental results demonstrate state-of-the-art performance across three metrics: Fr\'echet Gesture Distance (FGD), motion diversity, and example-gesture similarity. Furthermore, our framework enables granular control of individual body parts and accommodates diverse input modalities including motion clips, static poses, human video sequences, and textual descriptions. Our code, pre-trained models, and videos are available at https://robinwitch.github.io/MECo-Page.
Pre-Training Meta-Rule Selection Policy for Visual Generative Abductive Learning
Mar 09, 2025



Visual generative abductive learning studies jointly training symbol-grounded neural visual generator and inducing logic rules from data, such that after learning, the visual generation process is guided by the induced logic rules. A major challenge for this task is to reduce the time cost of logic abduction during learning, an essential step when the logic symbol set is large and the logic rule to induce is complicated. To address this challenge, we propose a pre-training method for obtaining meta-rule selection policy for the recently proposed visual generative learning approach AbdGen [Peng et al., 2023], aiming at significantly reducing the candidate meta-rule set and pruning the search space. The selection model is built based on the embedding representation of both symbol grounding of cases and meta-rules, which can be effectively integrated with both neural model and logic reasoning system. The pre-training process is done on pure symbol data, not involving symbol grounding learning of raw visual inputs, making the entire learning process low-cost. An additional interesting observation is that the selection policy can rectify symbol grounding errors unseen during pre-training, which is resulted from the memorization ability of attention mechanism and the relative stability of symbolic patterns. Experimental results show that our method is able to effectively address the meta-rule selection problem for visual abduction, boosting the efficiency of visual generative abductive learning. Code is available at https://github.com/future-item/metarule-select.
Enhancing Visual Reasoning with Autonomous Imagination in Multimodal Large Language Models
Nov 27, 2024

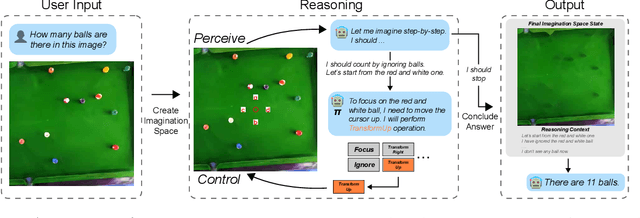

There have been recent efforts to extend the Chain-of-Thought (CoT) paradigm to Multimodal Large Language Models (MLLMs) by finding visual clues in the input scene, advancing the visual reasoning ability of MLLMs. However, current approaches are specially designed for the tasks where clue finding plays a major role in the whole reasoning process, leading to the difficulty in handling complex visual scenes where clue finding does not actually simplify the whole reasoning task. To deal with this challenge, we propose a new visual reasoning paradigm enabling MLLMs to autonomously modify the input scene to new ones based on its reasoning status, such that CoT is reformulated as conducting simple closed-loop decision-making and reasoning steps under a sequence of imagined visual scenes, leading to natural and general CoT construction. To implement this paradigm, we introduce a novel plug-and-play imagination space, where MLLMs conduct visual modifications through operations like focus, ignore, and transform based on their native reasoning ability without specific training. We validate our approach through a benchmark spanning dense counting, simple jigsaw puzzle solving, and object placement, challenging the reasoning ability beyond clue finding. The results verify that while existing techniques fall short, our approach enables MLLMs to effectively reason step by step through autonomous imagination. Project page: https://future-item.github.io/autoimagine-site.
Beyond Simple Sum of Delayed Rewards: Non-Markovian Reward Modeling for Reinforcement Learning
Oct 26, 2024



Reinforcement Learning (RL) empowers agents to acquire various skills by learning from reward signals. Unfortunately, designing high-quality instance-level rewards often demands significant effort. An emerging alternative, RL with delayed reward, focuses on learning from rewards presented periodically, which can be obtained from human evaluators assessing the agent's performance over sequences of behaviors. However, traditional methods in this domain assume the existence of underlying Markovian rewards and that the observed delayed reward is simply the sum of instance-level rewards, both of which often do not align well with real-world scenarios. In this paper, we introduce the problem of RL from Composite Delayed Reward (RLCoDe), which generalizes traditional RL from delayed rewards by eliminating the strong assumption. We suggest that the delayed reward may arise from a more complex structure reflecting the overall contribution of the sequence. To address this problem, we present a framework for modeling composite delayed rewards, using a weighted sum of non-Markovian components to capture the different contributions of individual steps. Building on this framework, we propose Composite Delayed Reward Transformer (CoDeTr), which incorporates a specialized in-sequence attention mechanism to effectively model these contributions. We conduct experiments on challenging locomotion tasks where the agent receives delayed rewards computed from composite functions of observable step rewards. The experimental results indicate that CoDeTr consistently outperforms baseline methods across evaluated metrics. Additionally, we demonstrate that it effectively identifies the most significant time steps within the sequence and accurately predicts rewards that closely reflect the environment feedback.
Enabling Synergistic Full-Body Control in Prompt-Based Co-Speech Motion Generation
Oct 01, 2024



Current co-speech motion generation approaches usually focus on upper body gestures following speech contents only, while lacking supporting the elaborate control of synergistic full-body motion based on text prompts, such as talking while walking. The major challenges lie in 1) the existing speech-to-motion datasets only involve highly limited full-body motions, making a wide range of common human activities out of training distribution; 2) these datasets also lack annotated user prompts. To address these challenges, we propose SynTalker, which utilizes the off-the-shelf text-to-motion dataset as an auxiliary for supplementing the missing full-body motion and prompts. The core technical contributions are two-fold. One is the multi-stage training process which obtains an aligned embedding space of motion, speech, and prompts despite the significant distributional mismatch in motion between speech-to-motion and text-to-motion datasets. Another is the diffusion-based conditional inference process, which utilizes the separate-then-combine strategy to realize fine-grained control of local body parts. Extensive experiments are conducted to verify that our approach supports precise and flexible control of synergistic full-body motion generation based on both speeches and user prompts, which is beyond the ability of existing approaches.
Reinforcement Learning from Bagged Reward: A Transformer-based Approach for Instance-Level Reward Redistribution
Feb 06, 2024In reinforcement Learning (RL), an instant reward signal is generated for each action of the agent, such that the agent learns to maximize the cumulative reward to obtain the optimal policy. However, in many real-world applications, the instant reward signals are not obtainable by the agent. Instead, the learner only obtains rewards at the ends of bags, where a bag is defined as a partial sequence of a complete trajectory. In this situation, the learner has to face the significant difficulty of exploring the unknown instant rewards in the bags, which could not be addressed by existing approaches, including those trajectory-based approaches that consider only complete trajectories and ignore the inner reward distributions. To formally study this situation, we introduce a novel RL setting termed Reinforcement Learning from Bagged Rewards (RLBR), where only the bagged rewards of sequences can be obtained. We provide the theoretical study to establish the connection between RLBR and standard RL in Markov Decision Processes (MDPs). To effectively explore the reward distributions within the bagged rewards, we propose a Transformer-based reward model, the Reward Bag Transformer (RBT), which uses the self-attention mechanism for interpreting the contextual nuances and temporal dependencies within each bag. Extensive experimental analyses demonstrate the superiority of our method, particularly in its ability to mimic the original MDP's reward distribution, highlighting its proficiency in contextual understanding and adaptability to environmental dynamics.
Generating by Understanding: Neural Visual Generation with Logical Symbol Groundings
Oct 26, 2023



Despite the great success of neural visual generative models in recent years, integrating them with strong symbolic knowledge reasoning systems remains a challenging task. The main challenges are two-fold: one is symbol assignment, i.e. bonding latent factors of neural visual generators with meaningful symbols from knowledge reasoning systems. Another is rule learning, i.e. learning new rules, which govern the generative process of the data, to augment the knowledge reasoning systems. To deal with these symbol grounding problems, we propose a neural-symbolic learning approach, Abductive Visual Generation (AbdGen), for integrating logic programming systems with neural visual generative models based on the abductive learning framework. To achieve reliable and efficient symbol assignment, the quantized abduction method is introduced for generating abduction proposals by the nearest-neighbor lookups within semantic codebooks. To achieve precise rule learning, the contrastive meta-abduction method is proposed to eliminate wrong rules with positive cases and avoid less-informative rules with negative cases simultaneously. Experimental results on various benchmark datasets show that compared to the baselines, AbdGen requires significantly fewer instance-level labeling information for symbol assignment. Furthermore, our approach can effectively learn underlying logical generative rules from data, which is out of the capability of existing approaches.