 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmni-I2C: A Holistic Benchmark for High-Fidelity Image-to-Code Generation
Mar 18, 2026We present Omni-I2C, a comprehensive benchmark designed to evaluate the capability of Large Multimodal Models (LMMs) in converting complex, structured digital graphics into executable code. We argue that this task represents a non-trivial challenge for the current generation of LMMs: it demands an unprecedented synergy between high-fidelity visual perception -- to parse intricate spatial hierarchies and symbolic details -- and precise generative expression -- to synthesize syntactically sound and logically consistent code. Unlike traditional descriptive tasks, Omni-I2C requires a holistic understanding where any minor perceptual hallucination or coding error leads to a complete failure in visual reconstruction. Omni-I2C features 1080 meticulously curated samples, defined by its breadth across subjects, image modalities, and programming languages. By incorporating authentic user-sourced cases, the benchmark spans a vast spectrum of digital content -- from scientific visualizations to complex symbolic notations -- each paired with executable reference code. To complement this diversity, our evaluation framework provides necessary depth; by decoupling performance into perceptual fidelity and symbolic precision, it transcends surface-level accuracy to expose the granular structural failures and reasoning bottlenecks of current LMMs. Our evaluation reveals a substantial performance gap among leading LMMs; even state-of-the-art models struggle to preserve structural integrity in complex scenarios, underscoring that multimodal code generation remains a formidable challenge. Data and code are available at https://github.com/MiliLab/Omni-I2C.
SR3R: Rethinking Super-Resolution 3D Reconstruction With Feed-Forward Gaussian Splatting
Feb 27, 20263D super-resolution (3DSR) aims to reconstruct high-resolution (HR) 3D scenes from low-resolution (LR) multi-view images. Existing methods rely on dense LR inputs and per-scene optimization, which restricts the high-frequency priors for constructing HR 3D Gaussian Splatting (3DGS) to those inherited from pretrained 2D super-resolution (2DSR) models. This severely limits reconstruction fidelity, cross-scene generalization, and real-time usability. We propose to reformulate 3DSR as a direct feed-forward mapping from sparse LR views to HR 3DGS representations, enabling the model to autonomously learn 3D-specific high-frequency geometry and appearance from large-scale, multi-scene data. This fundamentally changes how 3DSR acquires high-frequency knowledge and enables robust generalization to unseen scenes. Specifically, we introduce SR3R, a feed-forward framework that directly predicts HR 3DGS representations from sparse LR views via the learned mapping network. To further enhance reconstruction fidelity, we introduce Gaussian offset learning and feature refinement, which stabilize reconstruction and sharpen high-frequency details. SR3R is plug-and-play and can be paired with any feed-forward 3DGS reconstruction backbone: the backbone provides an LR 3DGS scaffold, and SR3R upscales it to an HR 3DGS. Extensive experiments across three 3D benchmarks demonstrate that SR3R surpasses state-of-the-art (SOTA) 3DSR methods and achieves strong zero-shot generalization, even outperforming SOTA per-scene optimization methods on unseen scenes.
Adaptive Decoding via Hierarchical Neural Information Gradients in Mouse Visual Tasks
Oct 10, 2025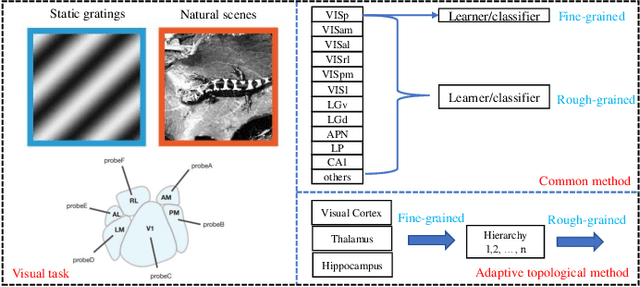
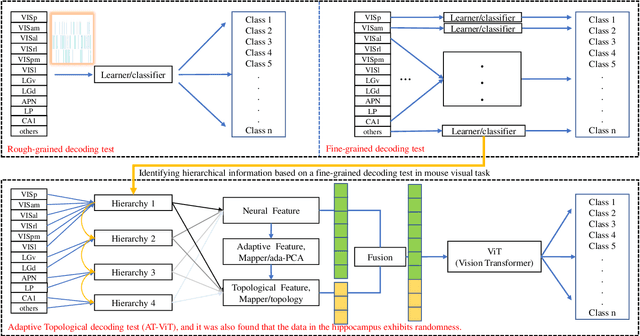
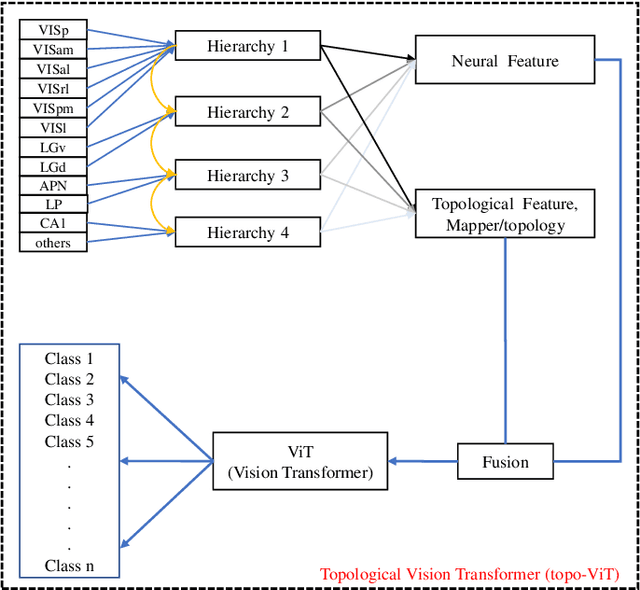
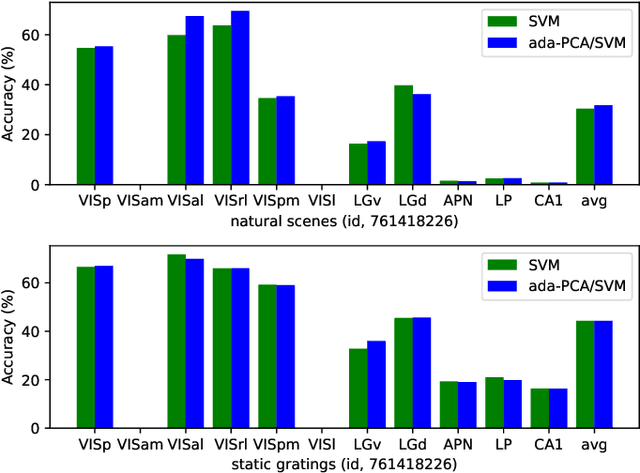
Understanding the encoding and decoding mechanisms of dynamic neural responses to different visual stimuli is an important topic in exploring how the brain represents visual information. Currently, hierarchically deep neural networks (DNNs) have played a significant role as tools for mining the core features of complex data. However, most methods often overlook the dynamic generation process of neural data, such as hierarchical brain's visual data, within the brain's structure. In the decoding of brain's visual data, two main paradigms are 'fine-grained decoding tests' and 'rough-grained decoding tests', which we define as focusing on a single brain region and studying the overall structure across multiple brain regions, respectively. In this paper, we mainly use the Visual Coding Neuropixel dataset from the Allen Brain Institute, and the hierarchical information extracted from some single brain regions (i.e., fine-grained decoding tests) is provided to the proposed method for studying the adaptive topological decoding between brain regions, called the Adaptive Topological Vision Transformer, or AT-ViT. In numerous experiments, the results reveal the importance of the proposed method in hierarchical networks in the visual tasks, and also validate the hypothesis that "the hierarchical information content in brain regions of the visual system can be quantified by decoding outcomes to reflect an information hierarchy." Among them, we found that neural data collected in the hippocampus can have a random decoding performance, and this negative impact on performance still holds significant scientific value.
REX-RAG: Reasoning Exploration with Policy Correction in Retrieval-Augmented Generation
Aug 12, 2025



Reinforcement learning (RL) is emerging as a powerful paradigm for enabling large language models (LLMs) to perform complex reasoning tasks. Recent advances indicate that integrating RL with retrieval-augmented generation (RAG) allows LLMs to dynamically incorporate external knowledge, leading to more informed and robust decision making. However, we identify a critical challenge during policy-driven trajectory sampling: LLMs are frequently trapped in unproductive reasoning paths, which we refer to as "dead ends", committing to overconfident yet incorrect conclusions. This severely hampers exploration and undermines effective policy optimization. To address this challenge, we propose REX-RAG (Reasoning Exploration with Policy Correction in Retrieval-Augmented Generation), a novel framework that explores alternative reasoning paths while maintaining rigorous policy learning through principled distributional corrections. Our approach introduces two key innovations: (1) Mixed Sampling Strategy, which combines a novel probe sampling method with exploratory prompts to escape dead ends; and (2) Policy Correction Mechanism, which employs importance sampling to correct distribution shifts induced by mixed sampling, thereby mitigating gradient estimation bias. We evaluate it on seven question-answering benchmarks, and the experimental results show that REX-RAG achieves average performance gains of 5.1% on Qwen2.5-3B and 3.6% on Qwen2.5-7B over strong baselines, demonstrating competitive results across multiple datasets. The code is publicly available at https://github.com/MiliLab/REX-RAG.
STAGE: A Stream-Centric Generative World Model for Long-Horizon Driving-Scene Simulation
Jun 16, 2025The generation of temporally consistent, high-fidelity driving videos over extended horizons presents a fundamental challenge in autonomous driving world modeling. Existing approaches often suffer from error accumulation and feature misalignment due to inadequate decoupling of spatio-temporal dynamics and limited cross-frame feature propagation mechanisms. To address these limitations, we present STAGE (Streaming Temporal Attention Generative Engine), a novel auto-regressive framework that pioneers hierarchical feature coordination and multi-phase optimization for sustainable video synthesis. To achieve high-quality long-horizon driving video generation, we introduce Hierarchical Temporal Feature Transfer (HTFT) and a novel multi-stage training strategy. HTFT enhances temporal consistency between video frames throughout the video generation process by modeling the temporal and denoising process separately and transferring denoising features between frames. The multi-stage training strategy is to divide the training into three stages, through model decoupling and auto-regressive inference process simulation, thereby accelerating model convergence and reducing error accumulation. Experiments on the Nuscenes dataset show that STAGE has significantly surpassed existing methods in the long-horizon driving video generation task. In addition, we also explored STAGE's ability to generate unlimited-length driving videos. We generated 600 frames of high-quality driving videos on the Nuscenes dataset, which far exceeds the maximum length achievable by existing methods.
AnesBench: Multi-Dimensional Evaluation of LLM Reasoning in Anesthesiology
Apr 03, 2025The application of large language models (LLMs) in the medical field has gained significant attention, yet their reasoning capabilities in more specialized domains like anesthesiology remain underexplored. In this paper, we systematically evaluate the reasoning capabilities of LLMs in anesthesiology and analyze key factors influencing their performance. To this end, we introduce AnesBench, a cross-lingual benchmark designed to assess anesthesiology-related reasoning across three levels: factual retrieval (System 1), hybrid reasoning (System 1.x), and complex decision-making (System 2). Through extensive experiments, we first explore how model characteristics, including model scale, Chain of Thought (CoT) length, and language transferability, affect reasoning performance. Then, we further evaluate the effectiveness of different training strategies, leveraging our curated anesthesiology-related dataset, including continuous pre-training (CPT) and supervised fine-tuning (SFT). Additionally, we also investigate how the test-time reasoning techniques, such as Best-of-N sampling and beam search, influence reasoning performance, and assess the impact of reasoning-enhanced model distillation, specifically DeepSeek-R1. We will publicly release AnesBench, along with our CPT and SFT training datasets and evaluation code at https://github.com/MiliLab/AnesBench.
Residual Learning Inspired Crossover Operator and Strategy Enhancements for Evolutionary Multitasking
Mar 27, 2025



In evolutionary multitasking, strategies such as crossover operators and skill factor assignment are critical for effective knowledge transfer. Existing improvements to crossover operators primarily focus on low-dimensional variable combinations, such as arithmetic crossover or partially mapped crossover, which are insufficient for modeling complex high-dimensional interactions.Moreover, static or semi-dynamic crossover strategies fail to adapt to the dynamic dependencies among tasks. In addition, current Multifactorial Evolutionary Algorithm frameworks often rely on fixed skill factor assignment strategies, lacking flexibility. To address these limitations, this paper proposes the Multifactorial Evolutionary Algorithm-Residual Learning (MFEA-RL) method based on residual learning. The method employs a Very Deep Super-Resolution (VDSR) model to generate high-dimensional residual representations of individuals, enhancing the modeling of complex relationships within dimensions. A ResNet-based mechanism dynamically assigns skill factors to improve task adaptability, while a random mapping mechanism efficiently performs crossover operations and mitigates the risk of negative transfer. Theoretical analysis and experimental results show that MFEA-RL outperforms state-of-the-art multitasking algorithms. It excels in both convergence and adaptability on standard evolutionary multitasking benchmarks, including CEC2017-MTSO and WCCI2020-MTSO. Additionally, its effectiveness is validated through a real-world application scenario.
ARM: Appearance Reconstruction Model for Relightable 3D Generation
Nov 16, 2024



Recent image-to-3D reconstruction models have greatly advanced geometry generation, but they still struggle to faithfully generate realistic appearance. To address this, we introduce ARM, a novel method that reconstructs high-quality 3D meshes and realistic appearance from sparse-view images. The core of ARM lies in decoupling geometry from appearance, processing appearance within the UV texture space. Unlike previous methods, ARM improves texture quality by explicitly back-projecting measurements onto the texture map and processing them in a UV space module with a global receptive field. To resolve ambiguities between material and illumination in input images, ARM introduces a material prior that encodes semantic appearance information, enhancing the robustness of appearance decomposition. Trained on just 8 H100 GPUs, ARM outperforms existing methods both quantitatively and qualitatively.
GS^3: Efficient Relighting with Triple Gaussian Splatting
Oct 15, 2024



We present a spatial and angular Gaussian based representation and a triple splatting process, for real-time, high-quality novel lighting-and-view synthesis from multi-view point-lit input images. To describe complex appearance, we employ a Lambertian plus a mixture of angular Gaussians as an effective reflectance function for each spatial Gaussian. To generate self-shadow, we splat all spatial Gaussians towards the light source to obtain shadow values, which are further refined by a small multi-layer perceptron. To compensate for other effects like global illumination, another network is trained to compute and add a per-spatial-Gaussian RGB tuple. The effectiveness of our representation is demonstrated on 30 samples with a wide variation in geometry (from solid to fluffy) and appearance (from translucent to anisotropic), as well as using different forms of input data, including rendered images of synthetic/reconstructed objects, photographs captured with a handheld camera and a flash, or from a professional lightstage. We achieve a training time of 40-70 minutes and a rendering speed of 90 fps on a single commodity GPU. Our results compare favorably with state-of-the-art techniques in terms of quality/performance. Our code and data are publicly available at https://GSrelight.github.io/.
* Accepted to SIGGRAPH Asia 2024. Project page: https://gsrelight.github.io/
GFE-Mamba: Mamba-based AD Multi-modal Progression Assessment via Generative Feature Extraction from MCI
Jul 22, 2024



Alzheimer's Disease (AD) is an irreversible neurodegenerative disorder that often progresses from Mild Cognitive Impairment (MCI), leading to memory loss and significantly impacting patients' lives. Clinical trials indicate that early targeted interventions for MCI patients can potentially slow or halt the development and progression of AD. Previous research has shown that accurate medical classification requires the inclusion of extensive multimodal data, such as assessment scales and various neuroimaging techniques like Magnetic Resonance Imaging (MRI) and Positron Emission Tomography (PET). However, consistently tracking the diagnosis of the same individual over time and simultaneously collecting multimodal data poses significant challenges. To address this issue, we introduce GFE-Mamba, a classifier based on Generative Feature Extraction (GFE). This classifier effectively integrates data from assessment scales, MRI, and PET, enabling deeper multimodal fusion. It efficiently extracts both long and short sequence information and incorporates additional information beyond the pixel space. This approach not only improves classification accuracy but also enhances the interpretability and stability of the model. We constructed datasets of over 3000 samples based on the Alzheimer's Disease Neuroimaging Initiative (ADNI) for a two-step training process. Our experimental results demonstrate that the GFE-Mamba model is effective in predicting the conversion from MCI to AD and outperforms several state-of-the-art methods. Our source code and ADNI dataset processing code are available at https://github.com/Tinysqua/GFE-Mamba.