 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse2Act: Learning Action-Aligned Sparse 3D Representations for Cross-Domain Robot Manipulation
Jun 10, 2026Explicit 3D representations are attractive for manipulation because they expose object shape, workspace geometry, and robot-object relations in metric coordinates. However, sparse 3D encoders are often learned through downstream task objectives, tying the representation to a particular data distribution, policy architecture, and action parameterization. We introduce Sparse2Act, an observation-action alignment framework for pretraining sparse point-cloud encoders. The key idea is to use task-space end-effector actions as geometric supervision: masked sparse 3D tokens are trained to organize scene features around the workspace motion paired with the observation. After pretraining, only the encoder initialization is reused by downstream policies, allowing them to retain their own architectures and action spaces, including joint-space commands. On the LIBERO-10 benchmark, our method achieves 86.9% average success after 500 fine-tuning steps. The same pretrained encoder supports LIBERO-to-Meta-World cross-domain transfer, achieving 73.4% average success on the Meta-World-5 benchmark. Ablations on the objective and decoder capacity show that the gains come from the masked action-alignment signal and remain useful across downstream action decoders. In real-world experiments, simulation pretraining followed by limited real-data fine-tuning achieves an average success rate of 72.5% across four tasks, demonstrating effective sim-to-real transfer. These results suggest that robot actions can provide compact geometric supervision for reusable sparse 3D representations.
TacCoRL: Integrating Tactile Feedback into VLA via Simulation
Jun 10, 2026Vision-language-action (VLA) models provide strong visual, language, and action priors for robot manipulation, but visual observations alone often miss the local contact state required for contact-rich tasks. We present TacCoRL, a scalable framework that injects Tactile feedback into VLA policies and improves them through sim-real Co-training and simulation-based reinforcement learning (RL), without requiring large-scale tactile pretraining or extensive real-world contact exploration. The key idea is not only adding touch as an input, but learning how contact readings should modulate action responses in near-failure states that are rare in demonstrations and risky to collect on hardware. We use a real-aligned simulator as a closed-loop training environment for contact interaction. Mixed simulated and real trajectories first warm-start tactile-conditioned actions in the pretrained policy. Reinforcement learning with verifiable task rewards then optimizes the policy using simulated contact rollouts. It reinforces tactile-conditioned actions that lead to task completion, while a supervised objective on real trajectories keeps the refined policy anchored to deployment visual, tactile, and action distributions. The resulting policy transfers directly to the real robot without privileged simulation state or online real-world RL. Across four bimanual contact-rich tasks, the final visuo-tactile policy achieves an average success rate of 72.5%, compared to baseline of 50.0%. Result videos and more details are available at https://tac-corl.github.io/
scTranslation: A Comprehensive Benchmark for Single-Cell Multi-Omics Modality Translation
Jun 02, 2026Simultaneous measurement of multiple omics modalities in single cells enables researchers to gain a more comprehensive understanding of cellular states and regulatory mechanisms. However, due to high experimental costs, significant noise, and incomplete modality coverage, a variety of computational methods for modality translation have emerged in recent years. Despite the development of translation models, there is still a lack of systematic benchmark evaluation in terms of datasets, evaluation metrics, and influencing factors. To address this, we present scTranslation, a comprehensive benchmark for single-cell multi-omics modality translation tasks. It includes diverse translation datasets, integrates state-of-the-art models, and provides a comprehensive evaluation metrics. In addition, we assess model performance under different scenarios, such as feature selection, feature quality, and few-shot settings. These factors significantly affect model performance but have rarely been systematically studied before. Leveraging this benchmark, we conduct a large-scale study of current methods, report many insightful findings that open up new possibilities for future development. The benchmark is open-sourced to facilitate future research. The code is anonymously released at https://github.com/Bunnybeibei/scTranslation.
scHelix: Asymmetric Dual-Stream Integration via Explicit Gene-Level Disentanglement
May 18, 2026A critical challenge in single-cell RNA sequencing (scRNA-seq) integration is resolving the tension between eliminating batch effects and maintaining biological fidelity. While recent evidence indicates that batch effects manifest heterogeneously across genes, most existing methods process the transcriptome uniformly, frequently resulting in over-correction and loss of subtle biological signals. To address this, we present scHelix, a dataset-adaptive framework that fundamentally changes how features are processed by explicitly partitioning genes into domain-invariant Anchors and domain-sensitive Variants at the input level. scHelix utilizes a dual-stream sparse diffusion encoder equipped with stop-gradient graph caching to efficiently learn multi-scale structural representations. The core of our approach is a novel asymmetric Align-Refine-Fuse protocol: the unstable Variant stream is first aligned to the robust topology of the Anchor stream, followed by a conservative refinement phase where the Anchor stream absorbs denoised details via bounded residual gating. This divide-and-conquer architecture prevents shortcut learning and ensures robust batch removal without compromising the integrity of biological clusters. Extensive benchmarking demonstrates that scHelix outperforms state-of-the-art methods.
MAT-Cell: A Multi-Agent Tree-Structured Reasoning Framework for Batch-Level Single-Cell Annotation
Apr 07, 2026Automated cellular reasoning faces a core dichotomy: supervised methods fall into the Reference Trap and fail to generalize to out-of-distribution cell states, while large language models (LLMs), without grounded biological priors, suffer from a Signal-to-Noise Paradox that produces spurious associations. We propose MAT-Cell, a neuro-symbolic reasoning framework that reframes single-cell analysis from black-box classification into constructive, verifiable proof generation. MAT-Cell injects symbolic constraints through adaptive Retrieval-Augmented Generation (RAG) to ground neural reasoning in biological axioms and reduce transcriptomic noise. It further employs a dialectic verification process with homogeneous rebuttal agents to audit and prune reasoning paths, forming syllogistic derivation trees that enforce logical consistency.Across large-scale and cross-species benchmarks, MAT-Cell significantly outperforms state-of-the-art (SOTA) models and maintains robust per-formance in challenging scenarios where baselinemethods severely degrade. Code is available at https://gith ub.com/jiangliu91/MAT-Cell-A-Mul ti-Agent-Tree-Structured-Reasoni ng-Framework-for-Batch-Level-Sin gle-Cell-Annotation.
The Trinity of Consistency as a Defining Principle for General World Models
Feb 26, 2026The construction of World Models capable of learning, simulating, and reasoning about objective physical laws constitutes a foundational challenge in the pursuit of Artificial General Intelligence. Recent advancements represented by video generation models like Sora have demonstrated the potential of data-driven scaling laws to approximate physical dynamics, while the emerging Unified Multimodal Model (UMM) offers a promising architectural paradigm for integrating perception, language, and reasoning. Despite these advances, the field still lacks a principled theoretical framework that defines the essential properties requisite for a General World Model. In this paper, we propose that a World Model must be grounded in the Trinity of Consistency: Modal Consistency as the semantic interface, Spatial Consistency as the geometric basis, and Temporal Consistency as the causal engine. Through this tripartite lens, we systematically review the evolution of multimodal learning, revealing a trajectory from loosely coupled specialized modules toward unified architectures that enable the synergistic emergence of internal world simulators. To complement this conceptual framework, we introduce CoW-Bench, a benchmark centered on multi-frame reasoning and generation scenarios. CoW-Bench evaluates both video generation models and UMMs under a unified evaluation protocol. Our work establishes a principled pathway toward general world models, clarifying both the limitations of current systems and the architectural requirements for future progress.
VecFormer: Towards Efficient and Generalizable Graph Transformer with Graph Token Attention
Feb 23, 2026Graph Transformer has demonstrated impressive capabilities in the field of graph representation learning. However, existing approaches face two critical challenges: (1) most models suffer from exponentially increasing computational complexity, making it difficult to scale to large graphs; (2) attention mechanisms based on node-level operations limit the flexibility of the model and result in poor generalization performance in out-of-distribution (OOD) scenarios. To address these issues, we propose \textbf{VecFormer} (the \textbf{Vec}tor Quantized Graph Trans\textbf{former}), an efficient and highly generalizable model for node classification, particularly under OOD settings. VecFormer adopts a two-stage training paradigm. In the first stage, two codebooks are used to reconstruct the node features and the graph structure, aiming to learn the rich semantic \texttt{Graph Codes}. In the second stage, attention mechanisms are performed at the \texttt{Graph Token} level based on the transformed cross codebook, reducing computational complexity while enhancing the model's generalization capability. Extensive experiments on datasets of various sizes demonstrate that VecFormer outperforms the existing Graph Transformer in both performance and speed.
MergeDNA: Context-aware Genome Modeling with Dynamic Tokenization through Token Merging
Nov 17, 2025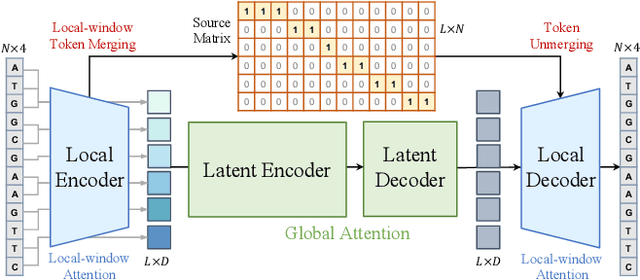

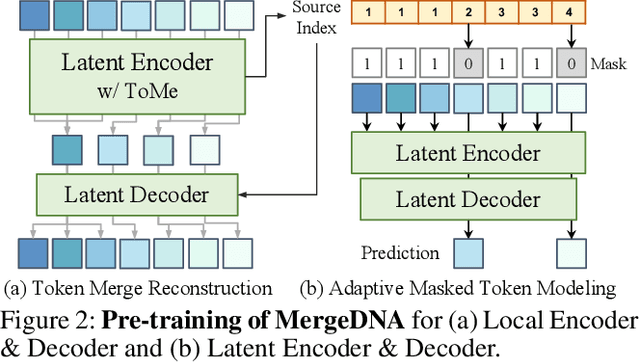
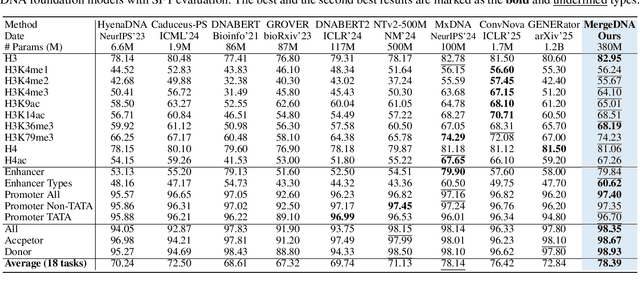
Modeling genomic sequences faces two unsolved challenges: the information density varies widely across different regions, while there is no clearly defined minimum vocabulary unit. Relying on either four primitive bases or independently designed DNA tokenizers, existing approaches with naive masked language modeling pre-training often fail to adapt to the varying complexities of genomic sequences. Leveraging Token Merging techniques, this paper introduces a hierarchical architecture that jointly optimizes a dynamic genomic tokenizer and latent Transformers with context-aware pre-training tasks. As for network structures, the tokenization module automatically chunks adjacent bases into words by stacking multiple layers of the differentiable token merging blocks with local-window constraints, then a Latent Encoder captures the global context of these merged words by full-attention blocks. Symmetrically employing a Latent Decoder and a Local Decoder, MergeDNA learns with two pre-training tasks: Merged Token Reconstruction simultaneously trains the dynamic tokenization module and adaptively filters important tokens, while Adaptive Masked Token Modeling learns to predict these filtered tokens to capture informative contents. Extensive experiments show that MergeDNA achieves superior performance on three popular DNA benchmarks and several multi-omics tasks with fine-tuning or zero-shot evaluation, outperforming typical tokenization methods and large-scale DNA foundation models.
Right-Side-Out: Learning Zero-Shot Sim-to-Real Garment Reversal
Sep 19, 2025Turning garments right-side out is a challenging manipulation task: it is highly dynamic, entails rapid contact changes, and is subject to severe visual occlusion. We introduce Right-Side-Out, a zero-shot sim-to-real framework that effectively solves this challenge by exploiting task structures. We decompose the task into Drag/Fling to create and stabilize an access opening, followed by Insert&Pull to invert the garment. Each step uses a depth-inferred, keypoint-parameterized bimanual primitive that sharply reduces the action space while preserving robustness. Efficient data generation is enabled by our custom-built, high-fidelity, GPU-parallel Material Point Method (MPM) simulator that models thin-shell deformation and provides robust and efficient contact handling for batched rollouts. Built on the simulator, our fully automated pipeline scales data generation by randomizing garment geometry, material parameters, and viewpoints, producing depth, masks, and per-primitive keypoint labels without any human annotations. With a single depth camera, policies trained entirely in simulation deploy zero-shot on real hardware, achieving up to 81.3% success rate. By employing task decomposition and high fidelity simulation, our framework enables tackling highly dynamic, severely occluded tasks without laborious human demonstrations.
EvoCoT: Overcoming the Exploration Bottleneck in Reinforcement Learning
Aug 11, 2025Reinforcement learning with verifiable reward (RLVR) has become a promising paradigm for post-training large language models (LLMs) to improve their reasoning capability. However, when the rollout accuracy is low on hard problems, the reward becomes sparse, limiting learning efficiency and causing exploration bottlenecks. Existing approaches either rely on stronger LLMs for distillation or filter out difficult problems, which limits scalability or restricts reasoning improvement through exploration. We propose EvoCoT, a self-evolving curriculum learning framework based on two-stage chain-of-thought (CoT) reasoning optimization. EvoCoT constrains the exploration space by self-generating and verifying CoT trajectories, then gradually shortens them to expand the space in a controlled way. This enables LLMs to stably learn from initially unsolved hard problems under sparse rewards. We apply EvoCoT to multiple LLM families, including Qwen, DeepSeek, and Llama. Experiments show that EvoCoT enables LLMs to solve previously unsolved problems, improves reasoning capability without external CoT supervision, and is compatible with various RL fine-tuning methods. We release the source code to support future research.