 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResEdit: Residual embeddings for precise generative image editing
Jun 15, 2026Conditional diffusion image generators can be repurposed for editing through inversion, without the need for large-scale paired fine-tuning data. However, producing high-quality, targeted edits while maintaining image identity and global consistency remains challenging, as weakly conditioned inversion often embeds conflicting image features into the noise. We demonstrate that incorporating a residual image encoding as additional conditioning enables both improved identity preservation and better editability. We optimize this residual encoding to provide a strong conditioning signal for reconstruction, thereby reducing the reliance on inversion and susceptibility to its aforementioned pitfalls. To ensure this residual does not interfere with desired edits, we incorporate a gradient reversal-based optimization strategy that disentangles the residual from the edited condition. We illustrate our method's ability to produce high-fidelity results across precise intrinsic-based editing and relighting, and show proof-of-concept text-guided manipulation.
MAOAM: Unified Object and Material Selection with Vision-Language Models
Jun 02, 2026Selection is a core operation in interactive image editing. To be practical, a user should be able to specify and disambiguate the desired selection region through either text or click-based interactions, and the system should support selecting not only objects but also other criteria, such as materials. Material-based selection is valuable for tasks like re-texturing surfaces or editing instances of a specific material. However, existing vision-language-model (VLM) based selection methods are object-centric and typically support a single interaction modality, limiting their applicability. In this work, we thus present Mask Any Object And Material (MAOAM), a unified selection framework that enables precise object and material-level selection across both text- and click-based interactions. MAOAM leverages a VLM with a segmentation head to produce pixel-accurate masks from user prompts: the VLM interprets the user's selection intent (object or material-level) and encodes visual entities, attributes, and spatial relations, while the segmentation head decodes the output token into a mask. A key challenge is the lack of material selection datasets with text annotations. We propose a scalable data generation pipeline: we collect real and synthetic images with material masks, and leverage VLMs to generate material descriptions with rich visual-semantics. We train MAOAM with a multi-task objective over click and text-based selection, along with an auxiliary VQA task derived from the material descriptions to facilitate deeper material understanding. Despite being trained with uni-modal prompts, our model exhibits an emergent improvement in selection when combining text and clicks at inference, enabling flexible image editing workflows. Experiments demonstrate accurate and coherent selections across diverse objects, materials, and interaction scenarios, highlighting robustness in practice.
An evaluation of SVBRDF Prediction from Generative Image Models for Appearance Modeling of 3D Scenes
Dec 15, 2025Digital content creation is experiencing a profound change with the advent of deep generative models. For texturing, conditional image generators now allow the synthesis of realistic RGB images of a 3D scene that align with the geometry of that scene. For appearance modeling, SVBRDF prediction networks recover material parameters from RGB images. Combining these technologies allows us to quickly generate SVBRDF maps for multiple views of a 3D scene, which can be merged to form a SVBRDF texture atlas of that scene. In this paper, we analyze the challenges and opportunities for SVBRDF prediction in the context of such a fast appearance modeling pipeline. On the one hand, single-view SVBRDF predictions might suffer from multiview incoherence and yield inconsistent texture atlases. On the other hand, generated RGB images, and the different modalities on which they are conditioned, can provide additional information for SVBRDF estimation compared to photographs. We compare neural architectures and conditions to identify designs that achieve high accuracy and coherence. We find that, surprisingly, a standard UNet is competitive with more complex designs. Project page: http://repo-sam.inria.fr/nerphys/svbrdf-evaluation
* Project page: http://repo-sam.inria.fr/nerphys/svbrdf-evaluation Code: http://github.com/graphdeco-inria/svbrdf-evaluation
V-RGBX: Video Editing with Accurate Controls over Intrinsic Properties
Dec 12, 2025



Large-scale video generation models have shown remarkable potential in modeling photorealistic appearance and lighting interactions in real-world scenes. However, a closed-loop framework that jointly understands intrinsic scene properties (e.g., albedo, normal, material, and irradiance), leverages them for video synthesis, and supports editable intrinsic representations remains unexplored. We present V-RGBX, the first end-to-end framework for intrinsic-aware video editing. V-RGBX unifies three key capabilities: (1) video inverse rendering into intrinsic channels, (2) photorealistic video synthesis from these intrinsic representations, and (3) keyframe-based video editing conditioned on intrinsic channels. At the core of V-RGBX is an interleaved conditioning mechanism that enables intuitive, physically grounded video editing through user-selected keyframes, supporting flexible manipulation of any intrinsic modality. Extensive qualitative and quantitative results show that V-RGBX produces temporally consistent, photorealistic videos while propagating keyframe edits across sequences in a physically plausible manner. We demonstrate its effectiveness in diverse applications, including object appearance editing and scene-level relighting, surpassing the performance of prior methods.
GimbalDiffusion: Gravity-Aware Camera Control for Video Generation
Dec 09, 2025


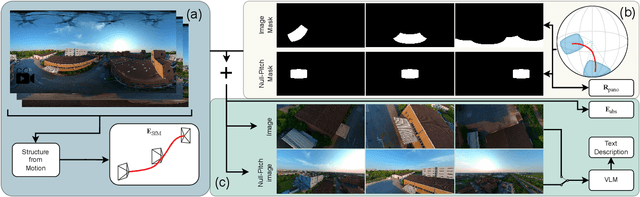
Recent progress in text-to-video generation has achieved remarkable realism, yet fine-grained control over camera motion and orientation remains elusive. Existing approaches typically encode camera trajectories through relative or ambiguous representations, limiting explicit geometric control. We introduce GimbalDiffusion, a framework that enables camera control grounded in physical-world coordinates, using gravity as a global reference. Instead of describing motion relative to previous frames, our method defines camera trajectories in an absolute coordinate system, allowing precise and interpretable control over camera parameters without requiring an initial reference frame. We leverage panoramic 360-degree videos to construct a wide variety of camera trajectories, well beyond the predominantly straight, forward-facing trajectories seen in conventional video data. To further enhance camera guidance, we introduce null-pitch conditioning, an annotation strategy that reduces the model's reliance on text content when conflicting with camera specifications (e.g., generating grass while the camera points towards the sky). Finally, we establish a benchmark for camera-aware video generation by rebalancing SpatialVID-HQ for comprehensive evaluation under wide camera pitch variation. Together, these contributions advance the controllability and robustness of text-to-video models, enabling precise, gravity-aligned camera manipulation within generative frameworks.
Fine-Grained Spatially Varying Material Selection in Images
Jun 11, 2025



Selection is the first step in many image editing processes, enabling faster and simpler modifications of all pixels sharing a common modality. In this work, we present a method for material selection in images, robust to lighting and reflectance variations, which can be used for downstream editing tasks. We rely on vision transformer (ViT) models and leverage their features for selection, proposing a multi-resolution processing strategy that yields finer and more stable selection results than prior methods. Furthermore, we enable selection at two levels: texture and subtexture, leveraging a new two-level material selection (DuMaS) dataset which includes dense annotations for over 800,000 synthetic images, both on the texture and subtexture levels.
IntrinsicEdit: Precise generative image manipulation in intrinsic space
May 15, 2025



Generative diffusion models have advanced image editing with high-quality results and intuitive interfaces such as prompts and semantic drawing. However, these interfaces lack precise control, and the associated methods typically specialize on a single editing task. We introduce a versatile, generative workflow that operates in an intrinsic-image latent space, enabling semantic, local manipulation with pixel precision for a range of editing operations. Building atop the RGB-X diffusion framework, we address key challenges of identity preservation and intrinsic-channel entanglement. By incorporating exact diffusion inversion and disentangled channel manipulation, we enable precise, efficient editing with automatic resolution of global illumination effects -- all without additional data collection or model fine-tuning. We demonstrate state-of-the-art performance across a variety of tasks on complex images, including color and texture adjustments, object insertion and removal, global relighting, and their combinations.
MatSwap: Light-aware material transfers in images
Feb 11, 2025



We present MatSwap, a method to transfer materials to designated surfaces in an image photorealistically. Such a task is non-trivial due to the large entanglement of material appearance, geometry, and lighting in a photograph. In the literature, material editing methods typically rely on either cumbersome text engineering or extensive manual annotations requiring artist knowledge and 3D scene properties that are impractical to obtain. In contrast, we propose to directly learn the relationship between the input material -- as observed on a flat surface -- and its appearance within the scene, without the need for explicit UV mapping. To achieve this, we rely on a custom light- and geometry-aware diffusion model. We fine-tune a large-scale pre-trained text-to-image model for material transfer using our synthetic dataset, preserving its strong priors to ensure effective generalization to real images. As a result, our method seamlessly integrates a desired material into the target location in the photograph while retaining the identity of the scene. We evaluate our method on synthetic and real images and show that it compares favorably to recent work both qualitatively and quantitatively. We will release our code and data upon publication.
MaterialPicker: Multi-Modal Material Generation with Diffusion Transformers
Dec 04, 2024



High-quality material generation is key for virtual environment authoring and inverse rendering. We propose MaterialPicker, a multi-modal material generator leveraging a Diffusion Transformer (DiT) architecture, improving and simplifying the creation of high-quality materials from text prompts and/or photographs. Our method can generate a material based on an image crop of a material sample, even if the captured surface is distorted, viewed at an angle or partially occluded, as is often the case in photographs of natural scenes. We further allow the user to specify a text prompt to provide additional guidance for the generation. We finetune a pre-trained DiT-based video generator into a material generator, where each material map is treated as a frame in a video sequence. We evaluate our approach both quantitatively and qualitatively and show that it enables more diverse material generation and better distortion correction than previous work.
SAMa: Material-aware 3D Selection and Segmentation
Nov 28, 2024



Decomposing 3D assets into material parts is a common task for artists and creators, yet remains a highly manual process. In this work, we introduce Select Any Material (SAMa), a material selection approach for various 3D representations. Building on the recently introduced SAM2 video selection model, we extend its capabilities to the material domain. We leverage the model's cross-view consistency to create a 3D-consistent intermediate material-similarity representation in the form of a point cloud from a sparse set of views. Nearest-neighbour lookups in this similarity cloud allow us to efficiently reconstruct accurate continuous selection masks over objects' surfaces that can be inspected from any view. Our method is multiview-consistent by design, alleviating the need for contrastive learning or feature-field pre-processing, and performs optimization-free selection in seconds. Our approach works on arbitrary 3D representations and outperforms several strong baselines in terms of selection accuracy and multiview consistency. It enables several compelling applications, such as replacing the diffuse-textured materials on a text-to-3D output, or selecting and editing materials on NeRFs and 3D-Gaussians.