 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrigamiBench: An Interactive Environment to Synthesize Flat-Foldable Origamis
Mar 17, 2026Building AI systems that can plan, act, and create in the physical world requires more than pattern recognition. Such systems must understand the causal mechanisms and constraints governing physical processes in order to guide sequential decisions. This capability relies on internal representations, analogous to an internal language model, that relate observations, actions, and resulting environmental changes. However, many existing benchmarks treat visual perception and programmatic reasoning as separate problems, focusing either on visual recognition or on symbolic tasks. The domain of origami provides a natural testbed that integrates these modalities. Constructing shapes through folding operations requires visual perception, reasoning about geometric and physical constraints, and sequential planning, while remaining sufficiently structured for systematic evaluation. We introduce OrigamiBench, an interactive benchmark in which models iteratively propose folds and receive feedback on physical validity and similarity to a target configuration. Experiments with modern vision-language models show that scaling model size alone does not reliably produce causal reasoning about physical transformations. Models fail to generate coherent multi-step folding strategies, suggesting that visual and language representations remain weakly integrated.
Enhancing Visual Reasoning with Autonomous Imagination in Multimodal Large Language Models
Nov 27, 2024

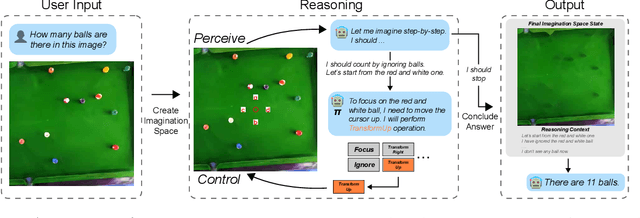

There have been recent efforts to extend the Chain-of-Thought (CoT) paradigm to Multimodal Large Language Models (MLLMs) by finding visual clues in the input scene, advancing the visual reasoning ability of MLLMs. However, current approaches are specially designed for the tasks where clue finding plays a major role in the whole reasoning process, leading to the difficulty in handling complex visual scenes where clue finding does not actually simplify the whole reasoning task. To deal with this challenge, we propose a new visual reasoning paradigm enabling MLLMs to autonomously modify the input scene to new ones based on its reasoning status, such that CoT is reformulated as conducting simple closed-loop decision-making and reasoning steps under a sequence of imagined visual scenes, leading to natural and general CoT construction. To implement this paradigm, we introduce a novel plug-and-play imagination space, where MLLMs conduct visual modifications through operations like focus, ignore, and transform based on their native reasoning ability without specific training. We validate our approach through a benchmark spanning dense counting, simple jigsaw puzzle solving, and object placement, challenging the reasoning ability beyond clue finding. The results verify that while existing techniques fall short, our approach enables MLLMs to effectively reason step by step through autonomous imagination. Project page: https://future-item.github.io/autoimagine-site.