 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaterialPicker: Multi-Modal Material Generation with Diffusion Transformers
Dec 04, 2024



High-quality material generation is key for virtual environment authoring and inverse rendering. We propose MaterialPicker, a multi-modal material generator leveraging a Diffusion Transformer (DiT) architecture, improving and simplifying the creation of high-quality materials from text prompts and/or photographs. Our method can generate a material based on an image crop of a material sample, even if the captured surface is distorted, viewed at an angle or partially occluded, as is often the case in photographs of natural scenes. We further allow the user to specify a text prompt to provide additional guidance for the generation. We finetune a pre-trained DiT-based video generator into a material generator, where each material map is treated as a frame in a video sequence. We evaluate our approach both quantitatively and qualitatively and show that it enables more diverse material generation and better distortion correction than previous work.
Efficient Reflectance Capture with a Deep Gated Mixture-of-Experts
Mar 29, 2022
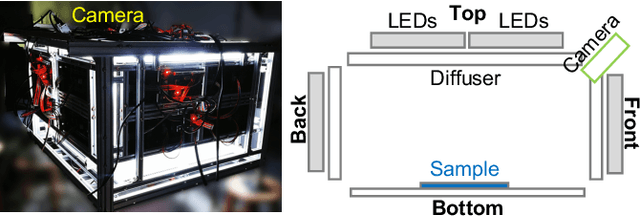

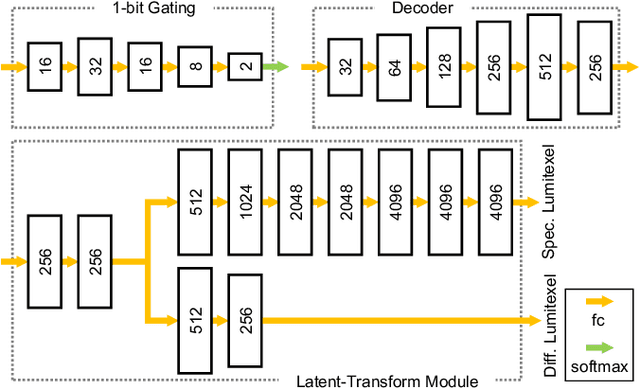
We present a novel framework to efficiently acquire near-planar anisotropic reflectance in a pixel-independent fashion, using a deep gated mixtureof-experts. While existing work employs a unified network to handle all possible input, our network automatically learns to condition on the input for enhanced reconstruction. We train a gating module to select one out of a number of specialized decoders for reflectance reconstruction, based on photometric measurements, essentially trading generality for quality. A common, pre-trained latent transform module is also appended to each decoder, to offset the burden of the increased number of decoders. In addition, the illumination conditions during acquisition can be jointly optimized. The effectiveness of our framework is validated on a wide variety of challenging samples using a near-field lightstage. Compared with the state-of-the-art technique, our results are improved at the same input bandwidth, and our bandwidth can be reduced to about 1/3 for equal-quality results.
Learning Efficient Photometric Feature Transform for Multi-view Stereo
Mar 27, 2021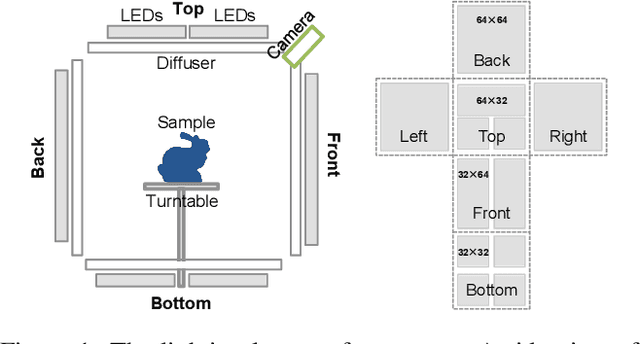

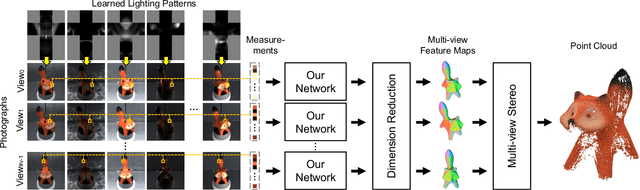
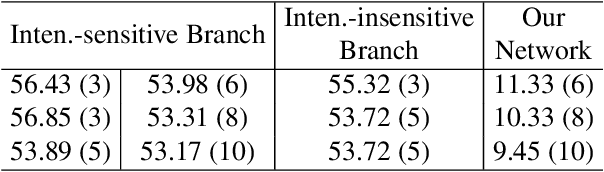
We present a novel framework to learn to convert the perpixel photometric information at each view into spatially distinctive and view-invariant low-level features, which can be plugged into existing multi-view stereo pipeline for enhanced 3D reconstruction. Both the illumination conditions during acquisition and the subsequent per-pixel feature transform can be jointly optimized in a differentiable fashion. Our framework automatically adapts to and makes efficient use of the geometric information available in different forms of input data. High-quality 3D reconstructions of a variety of challenging objects are demonstrated on the data captured with an illumination multiplexing device, as well as a point light. Our results compare favorably with state-of-the-art techniques.