 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLuSeeL: Language-queried Binaural Universal Sound Event Extraction and Localization
Jan 27, 2026Most universal sound extraction algorithms focus on isolating a target sound event from single-channel audio mixtures. However, the real world is three-dimensional, and binaural audio, which mimics human hearing, can capture richer spatial information, including sound source location. This spatial context is crucial for understanding and modeling complex auditory scenes, as it inherently informs sound detection and extraction. In this work, we propose a language-driven universal sound extraction network that isolates text-described sound events from binaural mixtures by effectively leveraging the spatial cues present in binaural signals. Additionally, we jointly predict the direction of arrival (DoA) of the target sound using spatial features from the extraction network. This dual-task approach exploits complementary location information to improve extraction performance while enabling accurate DoA estimation. Experimental results on the in-the-wild AudioCaps dataset show that our proposed LuSeeL model significantly outperforms single-channel and uni-task baselines.
FGGM: Fisher-Guided Gradient Masking for Continual Learning
Jan 26, 2026Catastrophic forgetting impairs the continuous learning of large language models. We propose Fisher-Guided Gradient Masking (FGGM), a framework that mitigates this by strategically selecting parameters for updates using diagonal Fisher Information. FGGM dynamically generates binary masks with adaptive thresholds, preserving critical parameters to balance stability and plasticity without requiring historical data. Unlike magnitude-based methods such as MIGU, our approach offers a mathematically principled parameter importance estimation. On the TRACE benchmark, FGGM shows a 9.6% relative improvement in retaining general capabilities over supervised fine-tuning (SFT) and a 4.4% improvement over MIGU on TRACE tasks. Additional analysis on code generation tasks confirms FGGM's superior performance and reduced forgetting, establishing it as an effective solution.
Joint Power Control and Precoding for Cell-Free Massive MIMO Systems With Sparse Multi-Dimensional Graph Neural Networks
Jul 02, 2025Cell-free massive multiple-input multiple-output (CF mMIMO) has emerged as a prominent candidate for future networks due to its ability to significantly enhance spectral efficiency by eliminating inter-cell interference. However, its practical deployment faces considerable challenges, such as high computational complexity and the optimization of its complex processing. To address these challenges, this correspondence proposes a framework based on a sparse multi-dimensional graph neural network (SP-MDGNN), which sparsifies the connections between access points (APs) and user equipments (UEs) to significantly reduce computational complexity while maintaining high performance. In addition, the weighted minimum mean square error (WMMSE) algorithm is introduced as a comparative method to further analyze the trade-off between performance and complexity. Simulation results demonstrate that the sparse method achieves an optimal balance between performance and complexity, significantly reducing the computational complexity of the original MDGNN method while incurring only a slight performance degradation, providing insights for the practical deployment of CF mMIMO systems in large-scale network.
OmniDRCA: Parallel Speech-Text Foundation Model via Dual-Resolution Speech Representations and Contrastive Alignment
Jun 11, 2025Recent studies on end-to-end speech generation with large language models (LLMs) have attracted significant community attention, with multiple works extending text-based LLMs to generate discrete speech tokens. Existing approaches primarily fall into two categories: (1) Methods that generate discrete speech tokens independently without incorporating them into the LLM's autoregressive process, resulting in text generation being unaware of concurrent speech synthesis. (2) Models that generate interleaved or parallel speech-text tokens through joint autoregressive modeling, enabling mutual modality awareness during generation. This paper presents OmniDRCA, a parallel speech-text foundation model based on joint autoregressive modeling, featuring dual-resolution speech representations and contrastive cross-modal alignment. Our approach processes speech and text representations in parallel while enhancing audio comprehension through contrastive alignment. Experimental results on Spoken Question Answering benchmarks demonstrate that OmniDRCA establishes new state-of-the-art (SOTA) performance among parallel joint speech-text modeling based foundation models, and achieves competitive performance compared to interleaved models. Additionally, we explore the potential of extending the framework to full-duplex conversational scenarios.
Plug-and-Play Co-Occurring Face Attention for Robust Audio-Visual Speaker Extraction
May 27, 2025Audio-visual speaker extraction isolates a target speaker's speech from a mixture speech signal conditioned on a visual cue, typically using the target speaker's face recording. However, in real-world scenarios, other co-occurring faces are often present on-screen, providing valuable speaker activity cues in the scene. In this work, we introduce a plug-and-play inter-speaker attention module to process these flexible numbers of co-occurring faces, allowing for more accurate speaker extraction in complex multi-person environments. We integrate our module into two prominent models: the AV-DPRNN and the state-of-the-art AV-TFGridNet. Extensive experiments on diverse datasets, including the highly overlapped VoxCeleb2 and sparsely overlapped MISP, demonstrate that our approach consistently outperforms baselines. Furthermore, cross-dataset evaluations on LRS2 and LRS3 confirm the robustness and generalizability of our method.
Conditional Latent Diffusion-Based Speech Enhancement Via Dual Context Learning
Jan 17, 2025Recently, the application of diffusion probabilistic models has advanced speech enhancement through generative approaches. However, existing diffusion-based methods have focused on the generation process in high-dimensional waveform or spectral domains, leading to increased generation complexity and slower inference speeds. Additionally, these methods have primarily modelled clean speech distributions, with limited exploration of noise distributions, thereby constraining the discriminative capability of diffusion models for speech enhancement. To address these issues, we propose a novel approach that integrates a conditional latent diffusion model (cLDM) with dual-context learning (DCL). Our method utilizes a variational autoencoder (VAE) to compress mel-spectrograms into a low-dimensional latent space. We then apply cLDM to transform the latent representations of both clean speech and background noise into Gaussian noise by the DCL process, and a parameterized model is trained to reverse this process, conditioned on noisy latent representations and text embeddings. By operating in a lower-dimensional space, the latent representations reduce the complexity of the generation process, while the DCL process enhances the model's ability to handle diverse and unseen noise environments. Our experiments demonstrate the strong performance of the proposed approach compared to existing diffusion-based methods, even with fewer iterative steps, and highlight the superior generalization capability of our models to out-of-domain noise datasets (https://github.com/modelscope/ClearerVoice-Studio).
HiFi-SR: A Unified Generative Transformer-Convolutional Adversarial Network for High-Fidelity Speech Super-Resolution
Jan 17, 2025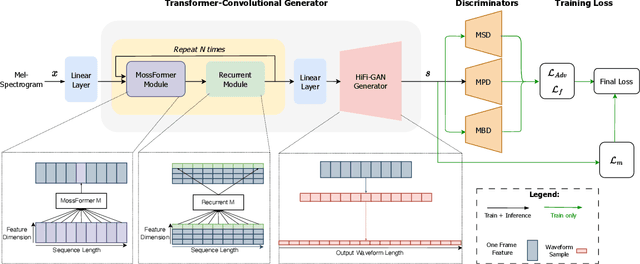
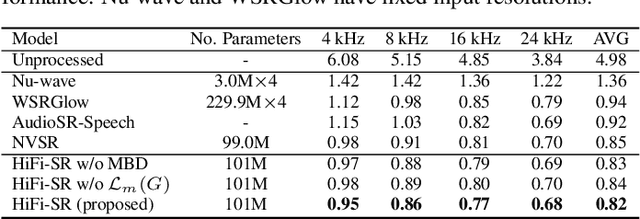

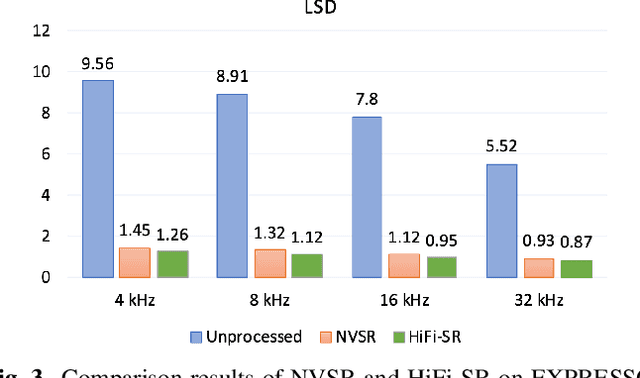
The application of generative adversarial networks (GANs) has recently advanced speech super-resolution (SR) based on intermediate representations like mel-spectrograms. However, existing SR methods that typically rely on independently trained and concatenated networks may lead to inconsistent representations and poor speech quality, especially in out-of-domain scenarios. In this work, we propose HiFi-SR, a unified network that leverages end-to-end adversarial training to achieve high-fidelity speech super-resolution. Our model features a unified transformer-convolutional generator designed to seamlessly handle both the prediction of latent representations and their conversion into time-domain waveforms. The transformer network serves as a powerful encoder, converting low-resolution mel-spectrograms into latent space representations, while the convolutional network upscales these representations into high-resolution waveforms. To enhance high-frequency fidelity, we incorporate a multi-band, multi-scale time-frequency discriminator, along with a multi-scale mel-reconstruction loss in the adversarial training process. HiFi-SR is versatile, capable of upscaling any input speech signal between 4 kHz and 32 kHz to a 48 kHz sampling rate. Experimental results demonstrate that HiFi-SR significantly outperforms existing speech SR methods across both objective metrics and ABX preference tests, for both in-domain and out-of-domain scenarios (https://github.com/modelscope/ClearerVoice-Studio).
Emotional Dimension Control in Language Model-Based Text-to-Speech: Spanning a Broad Spectrum of Human Emotions
Sep 25, 2024Current emotional text-to-speech (TTS) systems face challenges in mimicking a broad spectrum of human emotions due to the inherent complexity of emotions and limitations in emotional speech datasets and models. This paper proposes a TTS framework that facilitates control over pleasure, arousal, and dominance, and can synthesize a diversity of emotional styles without requiring any emotional speech data during TTS training. We train an emotional attribute predictor using only categorical labels from speech data, aligning with psychological research and incorporating anchored dimensionality reduction on self-supervised learning (SSL) features. The TTS framework converts text inputs into phonetic tokens via an autoregressive language model and uses pseudo-emotional dimensions to guide the parallel prediction of fine-grained acoustic details. Experiments conducted on the LibriTTS dataset demonstrate that our framework can synthesize speech with enhanced naturalness and a variety of emotional styles by effectively controlling emotional dimensions, even without the inclusion of any emotional speech during TTS training.
Imagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
Skip-Layer Attention: Bridging Abstract and Detailed Dependencies in Transformers
Jun 17, 2024



The Transformer architecture has significantly advanced deep learning, particularly in natural language processing, by effectively managing long-range dependencies. However, as the demand for understanding complex relationships grows, refining the Transformer's architecture becomes critical. This paper introduces Skip-Layer Attention (SLA) to enhance Transformer models by enabling direct attention between non-adjacent layers. This method improves the model's ability to capture dependencies between high-level abstract features and low-level details. By facilitating direct attention between these diverse feature levels, our approach overcomes the limitations of current Transformers, which often rely on suboptimal intra-layer attention. Our implementation extends the Transformer's functionality by enabling queries in a given layer to interact with keys and values from both the current layer and one preceding layer, thus enhancing the diversity of multi-head attention without additional computational burden. Extensive experiments demonstrate that our enhanced Transformer model achieves superior performance in language modeling tasks, highlighting the effectiveness of our skip-layer attention mechanism.