 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-grained Entity Typing via Label Reasoning
Sep 13, 2021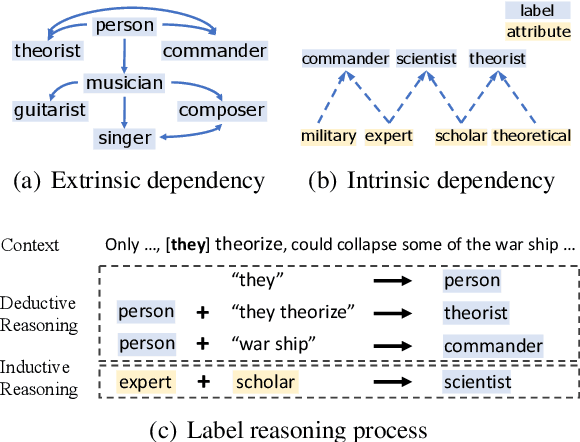
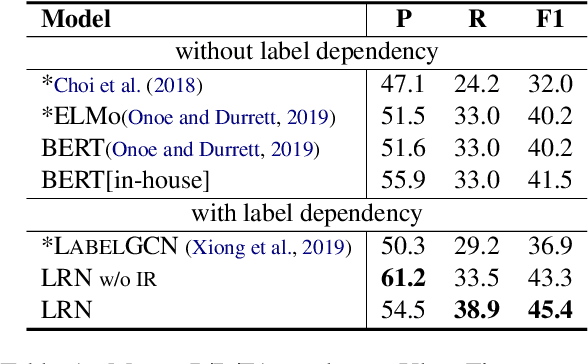
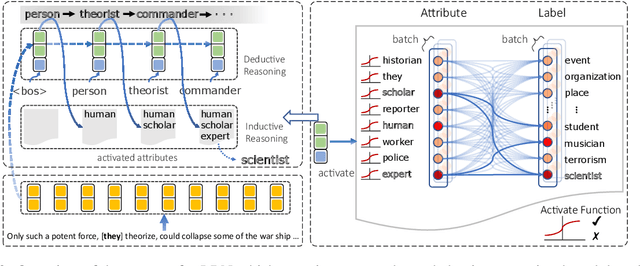
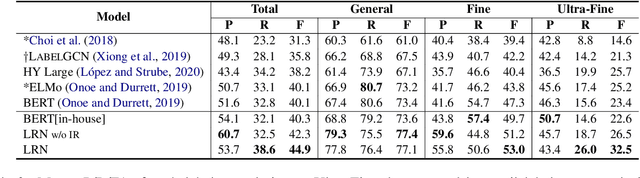
Conventional entity typing approaches are based on independent classification paradigms, which make them difficult to recognize inter-dependent, long-tailed and fine-grained entity types. In this paper, we argue that the implicitly entailed extrinsic and intrinsic dependencies between labels can provide critical knowledge to tackle the above challenges. To this end, we propose \emph{Label Reasoning Network(LRN)}, which sequentially reasons fine-grained entity labels by discovering and exploiting label dependencies knowledge entailed in the data. Specifically, LRN utilizes an auto-regressive network to conduct deductive reasoning and a bipartite attribute graph to conduct inductive reasoning between labels, which can effectively model, learn and reason complex label dependencies in a sequence-to-set, end-to-end manner. Experiments show that LRN achieves the state-of-the-art performance on standard ultra fine-grained entity typing benchmarks, and can also resolve the long tail label problem effectively.
DuTrust: A Sentiment Analysis Dataset for Trustworthiness Evaluation
Sep 07, 2021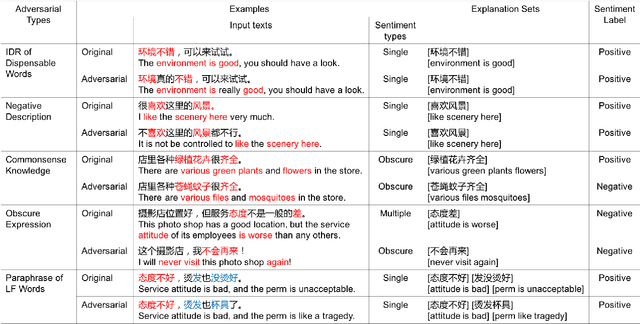


While deep learning models have greatly improved the performance of most artificial intelligence tasks, they are often criticized to be untrustworthy due to the black-box problem. Consequently, many works have been proposed to study the trustworthiness of deep learning. However, as most open datasets are designed for evaluating the accuracy of model outputs, there is still a lack of appropriate datasets for evaluating the inner workings of neural networks. The lack of datasets obviously hinders the development of trustworthiness research. Therefore, in order to systematically evaluate the factors for building trustworthy systems, we propose a novel and well-annotated sentiment analysis dataset to evaluate robustness and interpretability. To evaluate these factors, our dataset contains diverse annotations about the challenging distribution of instances, manual adversarial instances and sentiment explanations. Several evaluation metrics are further proposed for interpretability and robustness. Based on the dataset and metrics, we conduct comprehensive comparisons for the trustworthiness of three typical models, and also study the relations between accuracy, robustness and interpretability. We release this trustworthiness evaluation dataset at \url{https://github/xyz} and hope our work can facilitate the progress on building more trustworthy systems for real-world applications.
PAIR: Leveraging Passage-Centric Similarity Relation for Improving Dense Passage Retrieval
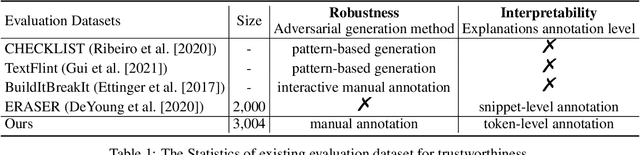
Aug 13, 2021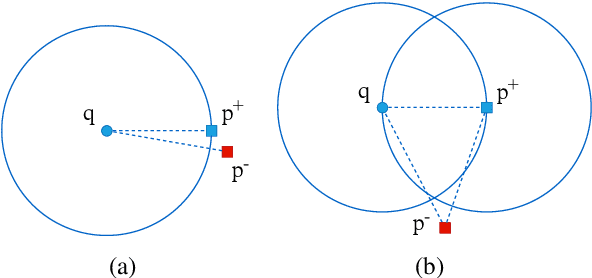

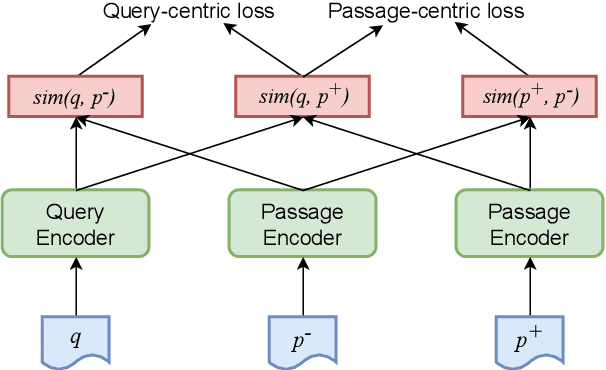
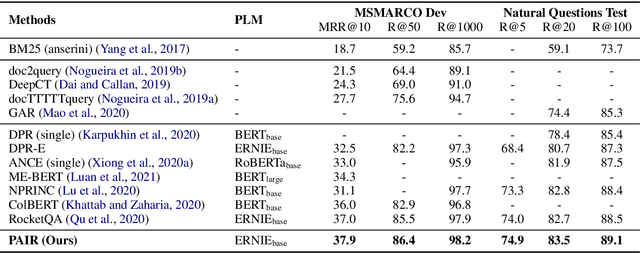
Recently, dense passage retrieval has become a mainstream approach to finding relevant information in various natural language processing tasks. A number of studies have been devoted to improving the widely adopted dual-encoder architecture. However, most of the previous studies only consider query-centric similarity relation when learning the dual-encoder retriever. In order to capture more comprehensive similarity relations, we propose a novel approach that leverages both query-centric and PAssage-centric sImilarity Relations (called PAIR) for dense passage retrieval. To implement our approach, we make three major technical contributions by introducing formal formulations of the two kinds of similarity relations, generating high-quality pseudo labeled data via knowledge distillation, and designing an effective two-stage training procedure that incorporates passage-centric similarity relation constraint. Extensive experiments show that our approach significantly outperforms previous state-of-the-art models on both MSMARCO and Natural Questions datasets.
ChemRL-GEM: Geometry Enhanced Molecular Representation Learning for Property Prediction
Jul 08, 2021
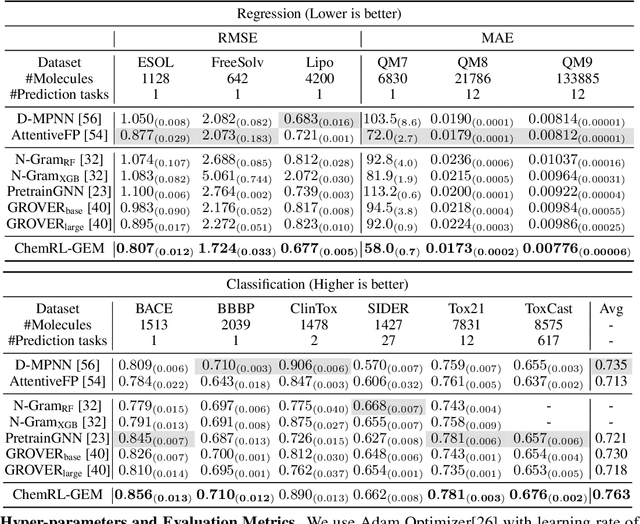
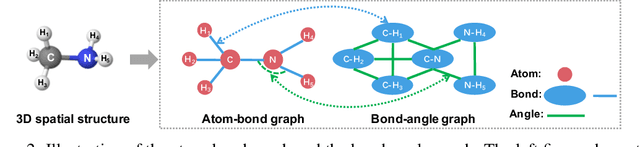
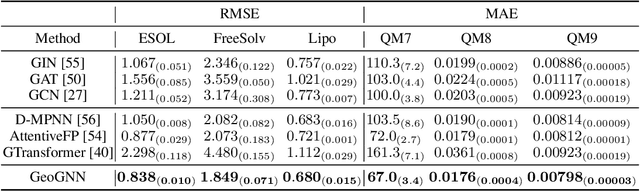
Effective molecular representation learning is of great importance to facilitate molecular property prediction, which is a fundamental task for the drug and material industry. Recent advances in graph neural networks (GNNs) have shown great promise in applying GNNs for molecular representation learning. Moreover, a few recent studies have also demonstrated successful applications of self-supervised learning methods to pre-train the GNNs to overcome the problem of insufficient labeled molecules. However, existing GNNs and pre-training strategies usually treat molecules as topological graph data without fully utilizing the molecular geometry information. Whereas, the three-dimensional (3D) spatial structure of a molecule, a.k.a molecular geometry, is one of the most critical factors for determining molecular physical, chemical, and biological properties. To this end, we propose a novel Geometry Enhanced Molecular representation learning method (GEM) for Chemical Representation Learning (ChemRL). At first, we design a geometry-based GNN architecture that simultaneously models atoms, bonds, and bond angles in a molecule. To be specific, we devised double graphs for a molecule: The first one encodes the atom-bond relations; The second one encodes bond-angle relations. Moreover, on top of the devised GNN architecture, we propose several novel geometry-level self-supervised learning strategies to learn spatial knowledge by utilizing the local and global molecular 3D structures. We compare ChemRL-GEM with various state-of-the-art (SOTA) baselines on different molecular benchmarks and exhibit that ChemRL-GEM can significantly outperform all baselines in both regression and classification tasks. For example, the experimental results show an overall improvement of 8.8% on average compared to SOTA baselines on the regression tasks, demonstrating the superiority of the proposed method.
ERNIE 3.0: Large-scale Knowledge Enhanced Pre-training for Language Understanding and Generation
Jul 05, 2021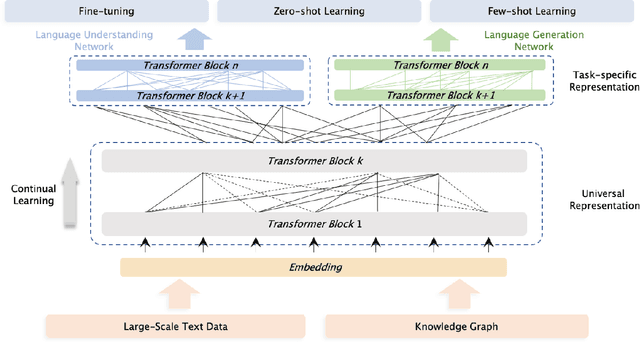

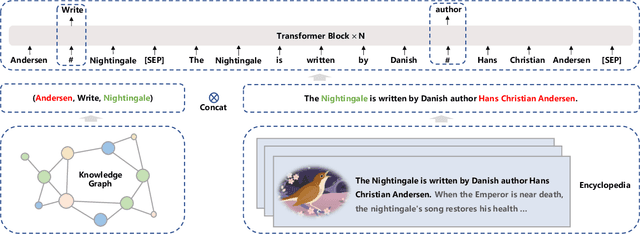
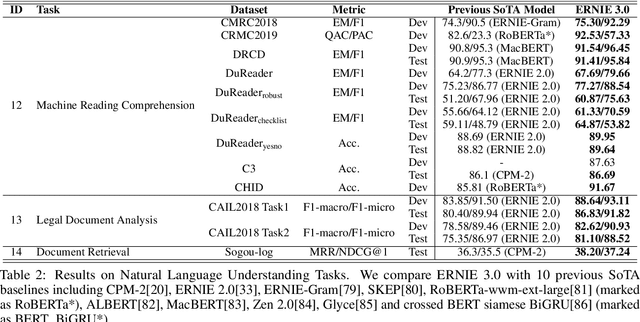
Pre-trained models have achieved state-of-the-art results in various Natural Language Processing (NLP) tasks. Recent works such as T5 and GPT-3 have shown that scaling up pre-trained language models can improve their generalization abilities. Particularly, the GPT-3 model with 175 billion parameters shows its strong task-agnostic zero-shot/few-shot learning capabilities. Despite their success, these large-scale models are trained on plain texts without introducing knowledge such as linguistic knowledge and world knowledge. In addition, most large-scale models are trained in an auto-regressive way. As a result, this kind of traditional fine-tuning approach demonstrates relatively weak performance when solving downstream language understanding tasks. In order to solve the above problems, we propose a unified framework named ERNIE 3.0 for pre-training large-scale knowledge enhanced models. It fuses auto-regressive network and auto-encoding network, so that the trained model can be easily tailored for both natural language understanding and generation tasks with zero-shot learning, few-shot learning or fine-tuning. We trained the model with 10 billion parameters on a 4TB corpus consisting of plain texts and a large-scale knowledge graph. Empirical results show that the model outperforms the state-of-the-art models on 54 Chinese NLP tasks, and its English version achieves the first place on the SuperGLUE benchmark (July 3, 2021), surpassing the human performance by +0.8% (90.6% vs. 89.8%).
ERNIE-Tiny : A Progressive Distillation Framework for Pretrained Transformer Compression
Jun 04, 2021
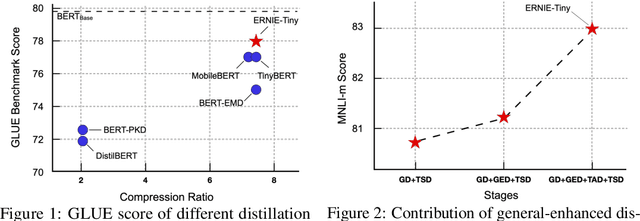
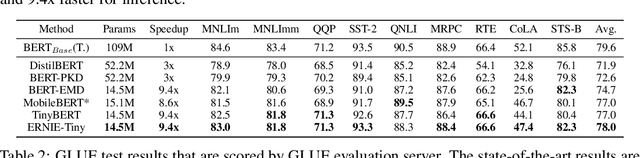
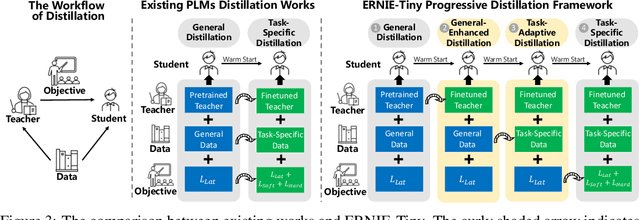
Pretrained language models (PLMs) such as BERT adopt a training paradigm which first pretrain the model in general data and then finetune the model on task-specific data, and have recently achieved great success. However, PLMs are notorious for their enormous parameters and hard to be deployed on real-life applications. Knowledge distillation has been prevailing to address this problem by transferring knowledge from a large teacher to a much smaller student over a set of data. We argue that the selection of thee three key components, namely teacher, training data, and learning objective, is crucial to the effectiveness of distillation. We, therefore, propose a four-stage progressive distillation framework ERNIE-Tiny to compress PLM, which varies the three components gradually from general level to task-specific level. Specifically, the first stage, General Distillation, performs distillation with guidance from pretrained teacher, gerenal data and latent distillation loss. Then, General-Enhanced Distillation changes teacher model from pretrained teacher to finetuned teacher. After that, Task-Adaptive Distillation shifts training data from general data to task-specific data. In the end, Task-Specific Distillation, adds two additional losses, namely Soft-Label and Hard-Label loss onto the last stage. Empirical results demonstrate the effectiveness of our framework and generalization gain brought by ERNIE-Tiny.In particular, experiments show that a 4-layer ERNIE-Tiny maintains over 98.0%performance of its 12-layer teacher BERT base on GLUE benchmark, surpassing state-of-the-art (SOTA) by 1.0% GLUE score with the same amount of parameters. Moreover, ERNIE-Tiny achieves a new compression SOTA on five Chinese NLP tasks, outperforming BERT base by 0.4% accuracy with 7.5x fewer parameters and9.4x faster inference speed.
A Unified Pre-training Framework for Conversational AI
May 27, 2021

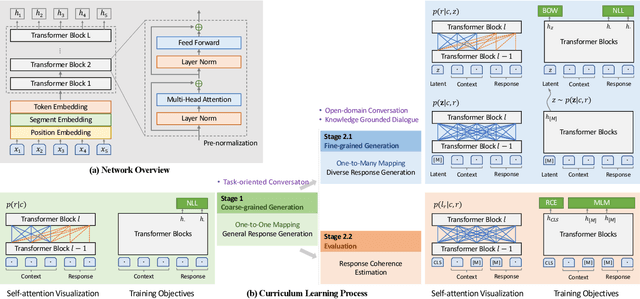

In this work, we explore the application of PLATO-2 on various dialogue systems, including open-domain conversation, knowledge grounded dialogue, and task-oriented conversation. PLATO-2 is initially designed as an open-domain chatbot, trained via two-stage curriculum learning. In the first stage, a coarse-grained response generation model is learned to fit the simplified one-to-one mapping relationship. This model is applied to the task-oriented conversation, given that the semantic mappings tend to be deterministic in task completion. In the second stage, another fine-grained generation model and an evaluation model are further learned for diverse response generation and coherence estimation, respectively. With superior capability on capturing one-to-many mapping, such models are suitable for the open-domain conversation and knowledge grounded dialogue. For the comprehensive evaluation of PLATO-2, we have participated in multiple tasks of DSTC9, including interactive evaluation of open-domain conversation (Track3-task2), static evaluation of knowledge grounded dialogue (Track3-task1), and end-to-end task-oriented conversation (Track2-task1). PLATO-2 has obtained the 1st place in all three tasks, verifying its effectiveness as a unified framework for various dialogue systems.
BASS: Boosting Abstractive Summarization with Unified Semantic Graph
May 25, 2021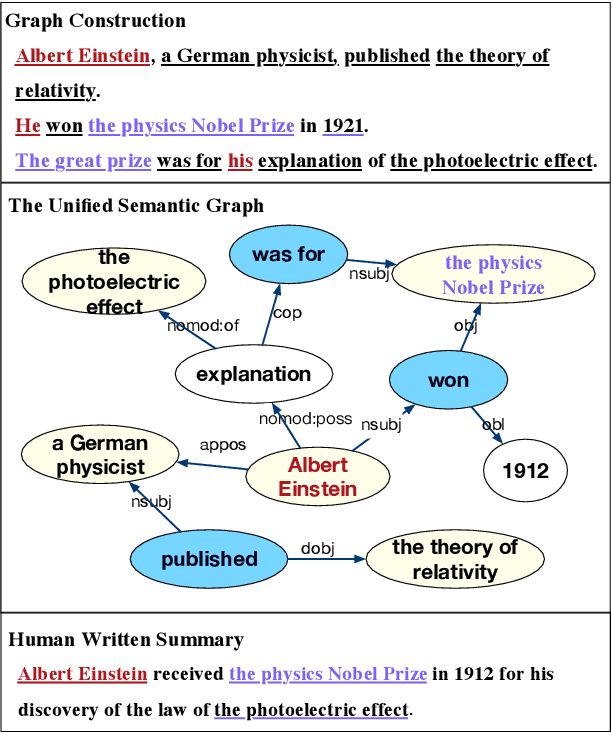
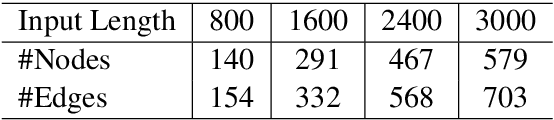
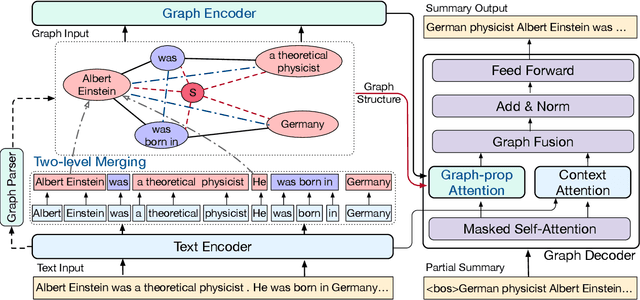
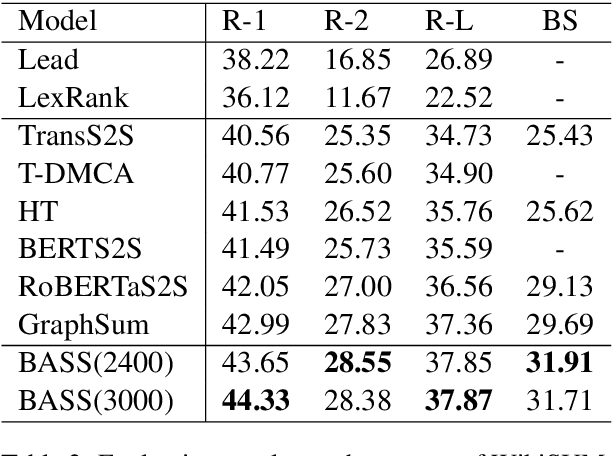
Abstractive summarization for long-document or multi-document remains challenging for the Seq2Seq architecture, as Seq2Seq is not good at analyzing long-distance relations in text. In this paper, we present BASS, a novel framework for Boosting Abstractive Summarization based on a unified Semantic graph, which aggregates co-referent phrases distributing across a long range of context and conveys rich relations between phrases. Further, a graph-based encoder-decoder model is proposed to improve both the document representation and summary generation process by leveraging the graph structure. Specifically, several graph augmentation methods are designed to encode both the explicit and implicit relations in the text while the graph-propagation attention mechanism is developed in the decoder to select salient content into the summary. Empirical results show that the proposed architecture brings substantial improvements for both long-document and multi-document summarization tasks.
Weakly Supervised Dense Video Captioning via Jointly Usage of Knowledge Distillation and Cross-modal Matching
May 18, 2021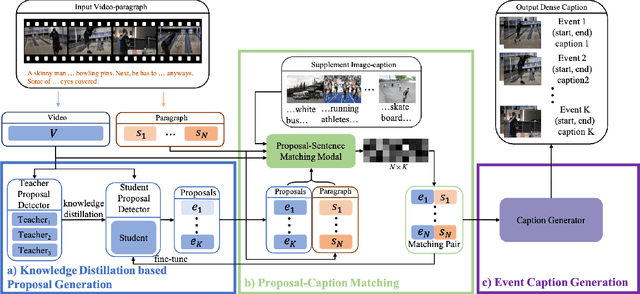
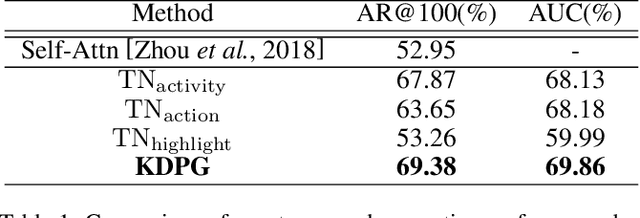
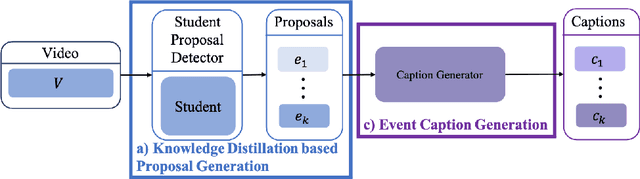
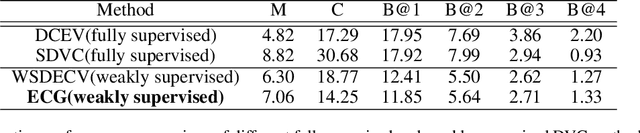
This paper proposes an approach to Dense Video Captioning (DVC) without pairwise event-sentence annotation. First, we adopt the knowledge distilled from relevant and well solved tasks to generate high-quality event proposals. Then we incorporate contrastive loss and cycle-consistency loss typically applied to cross-modal retrieval tasks to build semantic matching between the proposals and sentences, which are eventually used to train the caption generation module. In addition, the parameters of matching module are initialized via pre-training based on annotated images to improve the matching performance. Extensive experiments on ActivityNet-Caption dataset reveal the significance of distillation-based event proposal generation and cross-modal retrieval-based semantic matching to weakly supervised DVC, and demonstrate the superiority of our method to existing state-of-the-art methods.
BSTC: A Large-Scale Chinese-English Speech Translation Dataset
Apr 27, 2021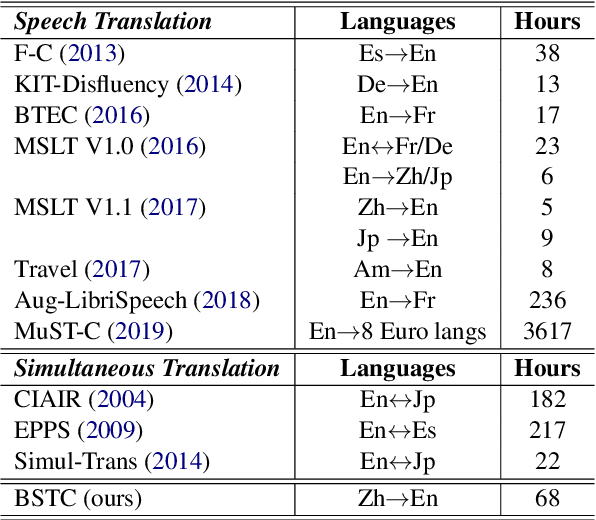
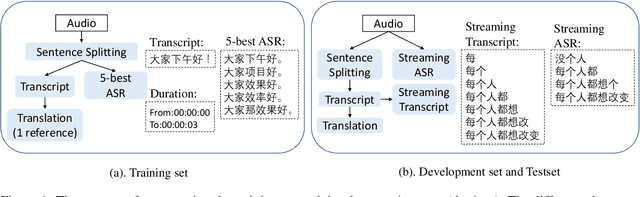

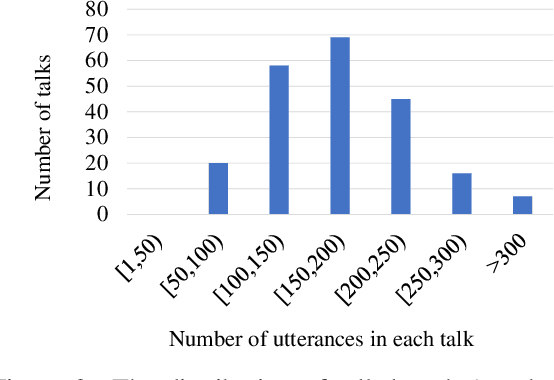
This paper presents BSTC (Baidu Speech Translation Corpus), a large-scale Chinese-English speech translation dataset. This dataset is constructed based on a collection of licensed videos of talks or lectures, including about 68 hours of Mandarin data, their manual transcripts and translations into English, as well as automated transcripts by an automatic speech recognition (ASR) model. We have further asked three experienced interpreters to simultaneously interpret the testing talks in a mock conference setting. This corpus is expected to promote the research of automatic simultaneous translation as well as the development of practical systems. We have organized simultaneous translation tasks and used this corpus to evaluate automatic simultaneous translation systems.