 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
MEnvAgent: Scalable Polyglot Environment Construction for Verifiable Software Engineering
Jan 30, 2026The evolution of Large Language Model (LLM) agents for software engineering (SWE) is constrained by the scarcity of verifiable datasets, a bottleneck stemming from the complexity of constructing executable environments across diverse languages. To address this, we introduce MEnvAgent, a Multi-language framework for automated Environment construction that facilitates scalable generation of verifiable task instances. MEnvAgent employs a multi-agent Planning-Execution-Verification architecture to autonomously resolve construction failures and integrates a novel Environment Reuse Mechanism that reduces computational overhead by incrementally patching historical environments. Evaluations on MEnvBench, a new benchmark comprising 1,000 tasks across 10 languages, demonstrate that MEnvAgent outperforms baselines, improving Fail-to-Pass (F2P) rates by 8.6% while reducing time costs by 43%. Additionally, we demonstrate the utility of MEnvAgent by constructing MEnvData-SWE, the largest open-source polyglot dataset of realistic verifiable Docker environments to date, alongside solution trajectories that enable consistent performance gains on SWE tasks across a wide range of models. Our code, benchmark, and dataset are available at https://github.com/ernie-research/MEnvAgent.
Distributional Clarity: The Hidden Driver of RL-Friendliness in Large Language Models
Jan 11, 2026Language model families exhibit striking disparity in their capacity to benefit from reinforcement learning: under identical training, models like Qwen achieve substantial gains, while others like Llama yield limited improvements. Complementing data-centric approaches, we reveal that this disparity reflects a hidden structural property: \textbf{distributional clarity} in probability space. Through a three-stage analysis-from phenomenon to mechanism to interpretation-we uncover that RL-friendly models exhibit intra-class compactness and inter-class separation in their probability assignments to correct vs. incorrect responses. We quantify this clarity using the \textbf{Silhouette Coefficient} ($S$) and demonstrate that (1) high $S$ correlates strongly with RL performance; (2) low $S$ is associated with severe logic errors and reasoning instability. To confirm this property, we introduce a Silhouette-Aware Reweighting strategy that prioritizes low-$S$ samples during training. Experiments across six mathematical benchmarks show consistent improvements across all model families, with gains up to 5.9 points on AIME24. Our work establishes distributional clarity as a fundamental, trainable property underlying RL-Friendliness.
A Unified Pre-training Framework for Conversational AI
May 27, 2021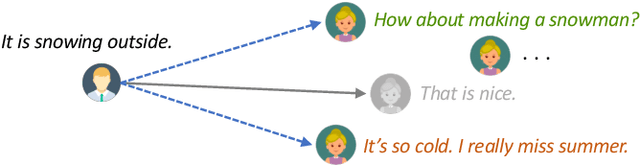

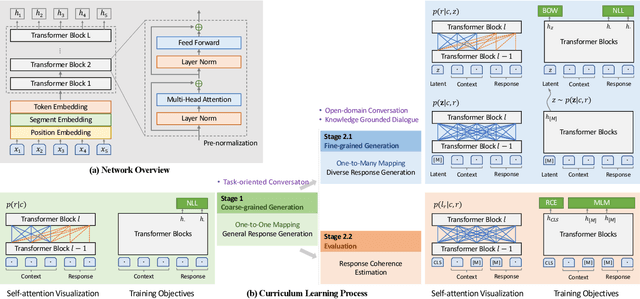

In this work, we explore the application of PLATO-2 on various dialogue systems, including open-domain conversation, knowledge grounded dialogue, and task-oriented conversation. PLATO-2 is initially designed as an open-domain chatbot, trained via two-stage curriculum learning. In the first stage, a coarse-grained response generation model is learned to fit the simplified one-to-one mapping relationship. This model is applied to the task-oriented conversation, given that the semantic mappings tend to be deterministic in task completion. In the second stage, another fine-grained generation model and an evaluation model are further learned for diverse response generation and coherence estimation, respectively. With superior capability on capturing one-to-many mapping, such models are suitable for the open-domain conversation and knowledge grounded dialogue. For the comprehensive evaluation of PLATO-2, we have participated in multiple tasks of DSTC9, including interactive evaluation of open-domain conversation (Track3-task2), static evaluation of knowledge grounded dialogue (Track3-task1), and end-to-end task-oriented conversation (Track2-task1). PLATO-2 has obtained the 1st place in all three tasks, verifying its effectiveness as a unified framework for various dialogue systems.