 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuery-Kontext: An Unified Multimodal Model for Image Generation and Editing
Sep 30, 2025



Unified Multimodal Models (UMMs) have demonstrated remarkable performance in text-to-image generation (T2I) and editing (TI2I), whether instantiated as assembled unified frameworks which couple powerful vision-language model (VLM) with diffusion-based generator, or as naive Unified Multimodal Models with an early fusion of understanding and generation modalities. We contend that in current unified frameworks, the crucial capability of multimodal generative reasoning which encompasses instruction understanding, grounding, and image referring for identity preservation and faithful reconstruction, is intrinsically entangled with high-fidelity synthesis. In this work, we introduce Query-Kontext, a novel approach that bridges the VLM and diffusion model via a multimodal ``kontext'' composed of semantic cues and coarse-grained image conditions encoded from multimodal inputs. This design delegates the complex ability of multimodal generative reasoning to powerful VLM while reserving diffusion model's role for high-quality visual synthesis. To achieve this, we propose a three-stage progressive training strategy. First, we connect the VLM to a lightweight diffusion head via multimodal kontext tokens to unleash the VLM's generative reasoning ability. Second, we scale this head to a large, pre-trained diffusion model to enhance visual detail and realism. Finally, we introduce a low-level image encoder to improve image fidelity and perform instruction tuning on downstream tasks. Furthermore, we build a comprehensive data pipeline integrating real, synthetic, and open-source datasets, covering diverse multimodal reference-to-image scenarios, including image generation, instruction-driven editing, customized generation, and multi-subject composition. Experiments show that our approach matches strong unified baselines and even outperforms task-specific state-of-the-art methods in several cases.
Can Understanding and Generation Truly Benefit Together -- or Just Coexist?
Sep 11, 2025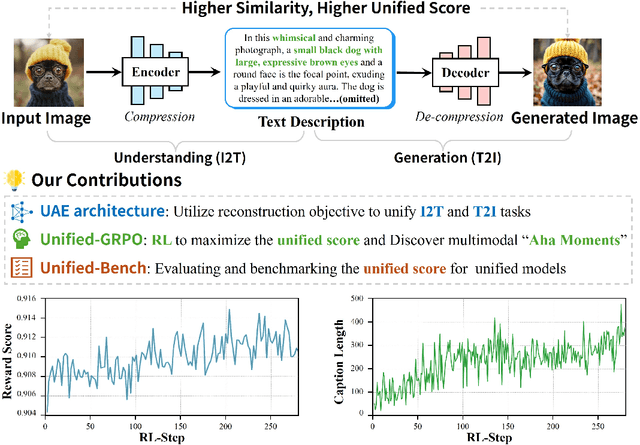
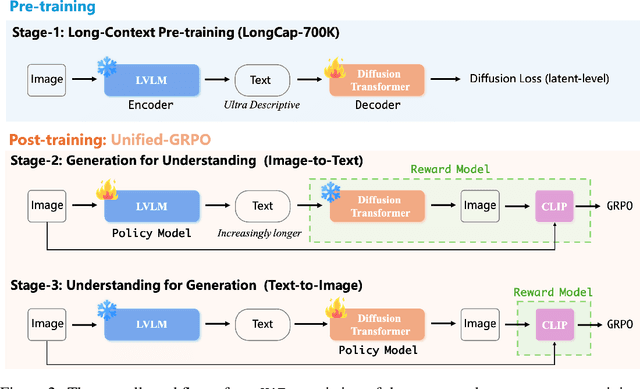
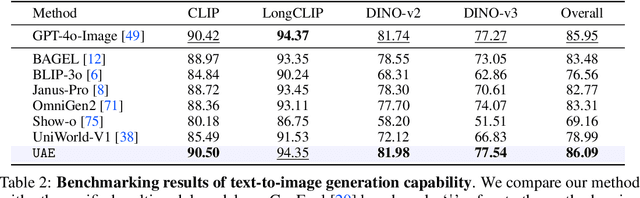
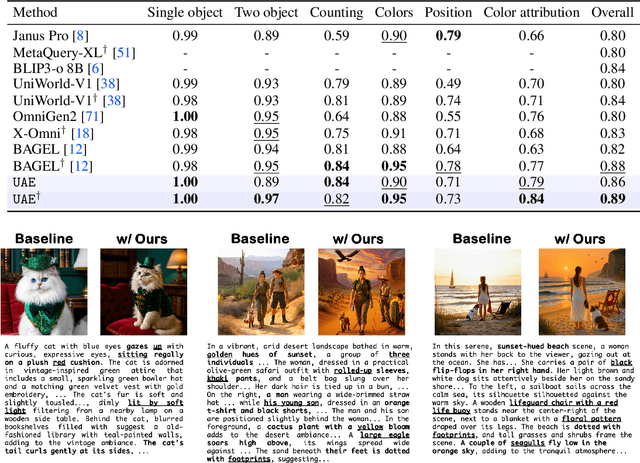
In this paper, we introduce an insightful paradigm through the Auto-Encoder lens-understanding as the encoder (I2T) that compresses images into text, and generation as the decoder (T2I) that reconstructs images from that text. Using reconstruction fidelity as the unified training objective, we enforce the coherent bidirectional information flow between the understanding and generation processes, bringing mutual gains. To implement this, we propose UAE, a novel framework for unified multimodal learning. We begin by pre-training the decoder with large-scale long-context image captions to capture fine-grained semantic and complex spatial relationships. We then propose Unified-GRPO via reinforcement learning (RL), which covers three stages: (1) A cold-start phase to gently initialize both encoder and decoder with a semantic reconstruction loss; (2) Generation for Understanding, where the encoder is trained to generate informative captions that maximize the decoder's reconstruction quality, enhancing its visual understanding; (3) Understanding for Generation, where the decoder is refined to reconstruct from these captions, forcing it to leverage every detail and improving its long-context instruction following and generation fidelity. For evaluation, we introduce Unified-Bench, the first benchmark tailored to assess the degree of unification of the UMMs. A surprising "aha moment" arises within the multimodal learning domain: as RL progresses, the encoder autonomously produces more descriptive captions, while the decoder simultaneously demonstrates a profound ability to understand these intricate descriptions, resulting in reconstructions of striking fidelity.
A Token is Worth over 1,000 Tokens: Efficient Knowledge Distillation through Low-Rank Clone
May 19, 2025
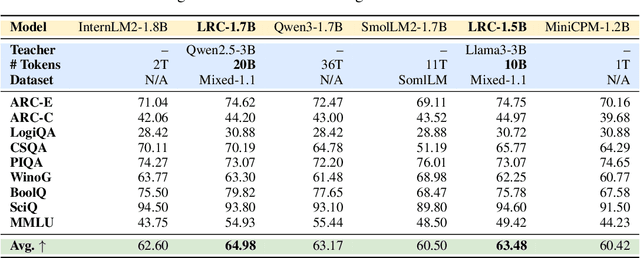
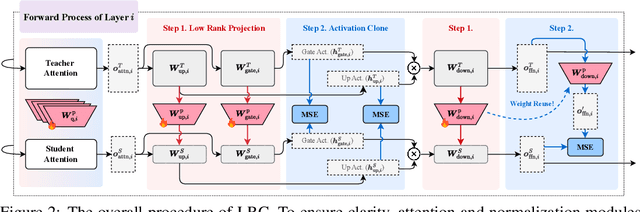
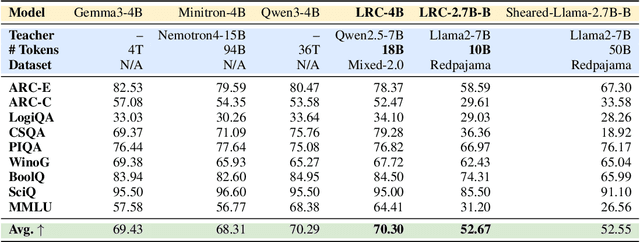
Training high-performing Small Language Models (SLMs) remains costly, even with knowledge distillation and pruning from larger teacher models. Existing work often faces three key challenges: (1) information loss from hard pruning, (2) inefficient alignment of representations, and (3) underutilization of informative activations, particularly from Feed-Forward Networks (FFNs). To address these challenges, we introduce Low-Rank Clone (LRC), an efficient pre-training method that constructs SLMs aspiring to behavioral equivalence with strong teacher models. LRC trains a set of low-rank projection matrices that jointly enable soft pruning by compressing teacher weights, and activation clone by aligning student activations, including FFN signals, with those of the teacher. This unified design maximizes knowledge transfer while removing the need for explicit alignment modules. Extensive experiments with open-source teachers (e.g., Llama-3.2-3B-Instruct, Qwen2.5-3B/7B-Instruct) show that LRC matches or surpasses state-of-the-art models trained on trillions of tokens--while using only 20B tokens, achieving over 1,000x training efficiency. Our codes and model checkpoints are available at https://github.com/CURRENTF/LowRankClone and https://huggingface.co/collections/JitaiHao/low-rank-clone-lrc-6828389e96a93f1d4219dfaf.
UGen: Unified Autoregressive Multimodal Model with Progressive Vocabulary Learning
Mar 27, 2025



We introduce UGen, a unified autoregressive multimodal model that demonstrates strong performance across text processing, image understanding, and image generation tasks simultaneously. UGen converts both texts and images into discrete token sequences and utilizes a single transformer to generate them uniformly in an autoregressive manner. To address the challenges associated with unified multimodal learning, UGen is trained using a novel mechanism, namely progressive vocabulary learning. In this process, visual token IDs are incrementally activated and integrated into the training phase, ultimately enhancing the effectiveness of unified multimodal learning. Experiments on comprehensive text and image tasks show that UGen achieves a significant overall performance improvement of 13.3% compared to the vanilla unified autoregressive method, and it also delivers competitive results across all tasks against several task-specific models.
BiDeV: Bilateral Defusing Verification for Complex Claim Fact-Checking
Feb 22, 2025



Complex claim fact-checking performs a crucial role in disinformation detection. However, existing fact-checking methods struggle with claim vagueness, specifically in effectively handling latent information and complex relations within claims. Moreover, evidence redundancy, where nonessential information complicates the verification process, remains a significant issue. To tackle these limitations, we propose Bilateral Defusing Verification (BiDeV), a novel fact-checking working-flow framework integrating multiple role-played LLMs to mimic the human-expert fact-checking process. BiDeV consists of two main modules: Vagueness Defusing identifies latent information and resolves complex relations to simplify the claim, and Redundancy Defusing eliminates redundant content to enhance the evidence quality. Extensive experimental results on two widely used challenging fact-checking benchmarks (Hover and Feverous-s) demonstrate that our BiDeV can achieve the best performance under both gold and open settings. This highlights the effectiveness of BiDeV in handling complex claims and ensuring precise fact-checking
Investigating Inference-time Scaling for Chain of Multi-modal Thought: A Preliminary Study
Feb 17, 2025



Recently, inference-time scaling of chain-of-thought (CoT) has been demonstrated as a promising approach for addressing multi-modal reasoning tasks. While existing studies have predominantly centered on text-based thinking, the integration of both visual and textual modalities within the reasoning process remains unexplored. In this study, we pioneer the exploration of inference-time scaling with multi-modal thought, aiming to bridge this gap. To provide a comprehensive analysis, we systematically investigate popular sampling-based and tree search-based inference-time scaling methods on 10 challenging tasks spanning various domains. Besides, we uniformly adopt a consistency-enhanced verifier to ensure effective guidance for both methods across different thought paradigms. Results show that multi-modal thought promotes better performance against conventional text-only thought, and blending the two types of thought fosters more diverse thinking. Despite these advantages, multi-modal thoughts necessitate higher token consumption for processing richer visual inputs, which raises concerns in practical applications. We hope that our findings on the merits and drawbacks of this research line will inspire future works in the field.
Empowering Backbone Models for Visual Text Generation with Input Granularity Control and Glyph-Aware Training
Oct 06, 2024



Diffusion-based text-to-image models have demonstrated impressive achievements in diversity and aesthetics but struggle to generate images with legible visual texts. Existing backbone models have limitations such as misspelling, failing to generate texts, and lack of support for Chinese text, but their development shows promising potential. In this paper, we propose a series of methods, aiming to empower backbone models to generate visual texts in English and Chinese. We first conduct a preliminary study revealing that Byte Pair Encoding (BPE) tokenization and the insufficient learning of cross-attention modules restrict the performance of the backbone models. Based on these observations, we make the following improvements: (1) We design a mixed granularity input strategy to provide more suitable text representations; (2) We propose to augment the conventional training objective with three glyph-aware training losses, which enhance the learning of cross-attention modules and encourage the model to focus on visual texts. Through experiments, we demonstrate that our methods can effectively empower backbone models to generate semantic relevant, aesthetically appealing, and accurate visual text images, while maintaining their fundamental image generation quality.
MonoFormer: One Transformer for Both Diffusion and Autoregression
Sep 24, 2024



Most existing multimodality methods use separate backbones for autoregression-based discrete text generation and diffusion-based continuous visual generation, or the same backbone by discretizing the visual data to use autoregression for both text and visual generation. In this paper, we propose to study a simple idea: share one transformer for both autoregression and diffusion. The feasibility comes from two main aspects: (i) Transformer is successfully applied to diffusion for visual generation, and (ii) transformer training for autoregression and diffusion is very similar, and the difference merely lies in that diffusion uses bidirectional attention mask and autoregression uses causal attention mask. Experimental results show that our approach achieves comparable image generation performance to current state-of-the-art methods as well as maintains the text generation capability. The project is publicly available at https://monoformer.github.io/.
UNIMO-G: Unified Image Generation through Multimodal Conditional Diffusion
Jan 25, 2024Existing text-to-image diffusion models primarily generate images from text prompts. However, the inherent conciseness of textual descriptions poses challenges in faithfully synthesizing images with intricate details, such as specific entities or scenes. This paper presents UNIMO-G, a simple multimodal conditional diffusion framework that operates on multimodal prompts with interleaved textual and visual inputs, which demonstrates a unified ability for both text-driven and subject-driven image generation. UNIMO-G comprises two core components: a Multimodal Large Language Model (MLLM) for encoding multimodal prompts, and a conditional denoising diffusion network for generating images based on the encoded multimodal input. We leverage a two-stage training strategy to effectively train the framework: firstly pre-training on large-scale text-image pairs to develop conditional image generation capabilities, and then instruction tuning with multimodal prompts to achieve unified image generation proficiency. A well-designed data processing pipeline involving language grounding and image segmentation is employed to construct multi-modal prompts. UNIMO-G excels in both text-to-image generation and zero-shot subject-driven synthesis, and is notably effective in generating high-fidelity images from complex multimodal prompts involving multiple image entities.
UniVG: Towards UNIfied-modal Video Generation
Jan 17, 2024



Diffusion based video generation has received extensive attention and achieved considerable success within both the academic and industrial communities. However, current efforts are mainly concentrated on single-objective or single-task video generation, such as generation driven by text, by image, or by a combination of text and image. This cannot fully meet the needs of real-world application scenarios, as users are likely to input images and text conditions in a flexible manner, either individually or in combination. To address this, we propose a Unified-modal Video Genearation system that is capable of handling multiple video generation tasks across text and image modalities. To this end, we revisit the various video generation tasks within our system from the perspective of generative freedom, and classify them into high-freedom and low-freedom video generation categories. For high-freedom video generation, we employ Multi-condition Cross Attention to generate videos that align with the semantics of the input images or text. For low-freedom video generation, we introduce Biased Gaussian Noise to replace the pure random Gaussian Noise, which helps to better preserve the content of the input conditions. Our method achieves the lowest Fr\'echet Video Distance (FVD) on the public academic benchmark MSR-VTT, surpasses the current open-source methods in human evaluations, and is on par with the current close-source method Gen2. For more samples, visit https://univg-baidu.github.io.