 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
Shall Your Data Strategy Work? Perform a Swift Study
Feb 19, 2025This work presents a swift method to assess the efficacy of particular types of instruction-tuning data, utilizing just a handful of probe examples and eliminating the need for model retraining. This method employs the idea of gradient-based data influence estimation, analyzing the gradient projections of probe examples from the chosen strategy onto evaluation examples to assess its advantages. Building upon this method, we conducted three swift studies to investigate the potential of Chain-of-thought (CoT) data, query clarification data, and response evaluation data in enhancing model generalization. Subsequently, we embarked on a validation study to corroborate the findings of these swift studies. In this validation study, we developed training datasets tailored to each studied strategy and compared model performance with and without the use of these datasets. The results of the validation study aligned with the findings of the swift studies, validating the efficacy of our proposed method.
Towards Boosting Many-to-Many Multilingual Machine Translation with Large Language Models
Jan 11, 2024The training paradigm for machine translation has gradually shifted, from learning neural machine translation (NMT) models with extensive parallel corpora to instruction finetuning on pretrained multilingual large language models (LLMs) with high-quality translation pairs. In this paper, we focus on boosting the many-to-many multilingual translation performance of LLMs with an emphasis on zero-shot translation directions. We demonstrate that prompt strategies adopted during instruction finetuning are crucial to zero-shot translation performance and introduce a cross-lingual consistency regularization, XConST, to bridge the representation gap among different languages and improve zero-shot translation performance. XConST is not a new method, but a version of CrossConST (Gao et al., 2023a) adapted for multilingual finetuning on LLMs with translation instructions. Experimental results on ALMA (Xu et al., 2023) and LLaMA-2 (Touvron et al., 2023) show that our approach consistently improves translation performance. Our implementations are available at https://github.com/gpengzhi/CrossConST-LLM.
An Empirical Study of Consistency Regularization for End-to-End Speech-to-Text Translation
Aug 28, 2023



Consistency regularization methods, such as R-Drop (Liang et al., 2021) and CrossConST (Gao et al., 2023), have achieved impressive supervised and zero-shot performance in the neural machine translation (NMT) field. Can we also boost end-to-end (E2E) speech-to-text translation (ST) by leveraging consistency regularization? In this paper, we conduct empirical studies on intra-modal and cross-modal consistency and propose two training strategies, SimRegCR and SimZeroCR, for E2E ST in regular and zero-shot scenarios. Experiments on the MuST-C benchmark show that our approaches achieve state-of-the-art (SOTA) performance in most translation directions. The analyses prove that regularization brought by the intra-modal consistency, instead of modality gap, is crucial for the regular E2E ST, and the cross-modal consistency could close the modality gap and boost the zero-shot E2E ST performance.
Learning Multilingual Sentence Representations with Cross-lingual Consistency Regularization
Jun 12, 2023



Multilingual sentence representations are the foundation for similarity-based bitext mining, which is crucial for scaling multilingual neural machine translation (NMT) system to more languages. In this paper, we introduce MuSR: a one-for-all Multilingual Sentence Representation model that supports more than 220 languages. Leveraging billions of English-centric parallel corpora, we train a multilingual Transformer encoder, coupled with an auxiliary Transformer decoder, by adopting a multilingual NMT framework with CrossConST, a cross-lingual consistency regularization technique proposed in Gao et al. (2023). Experimental results on multilingual similarity search and bitext mining tasks show the effectiveness of our approach. Specifically, MuSR achieves superior performance over LASER3 (Heffernan et al., 2022) which consists of 148 independent multilingual sentence encoders.
Improving Zero-shot Multilingual Neural Machine Translation by Leveraging Cross-lingual Consistency Regularization
May 12, 2023The multilingual neural machine translation (NMT) model has a promising capability of zero-shot translation, where it could directly translate between language pairs unseen during training. For good transfer performance from supervised directions to zero-shot directions, the multilingual NMT model is expected to learn universal representations across different languages. This paper introduces a cross-lingual consistency regularization, CrossConST, to bridge the representation gap among different languages and boost zero-shot translation performance. The theoretical analysis shows that CrossConST implicitly maximizes the probability distribution for zero-shot translation, and the experimental results on both low-resource and high-resource benchmarks show that CrossConST consistently improves the translation performance. The experimental analysis also proves that CrossConST could close the sentence representation gap and better align the representation space. Given the universality and simplicity of CrossConST, we believe it can serve as a strong baseline for future multilingual NMT research.
Bi-SimCut: A Simple Strategy for Boosting Neural Machine Translation
Jun 06, 2022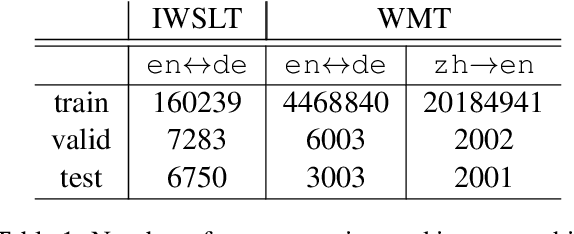
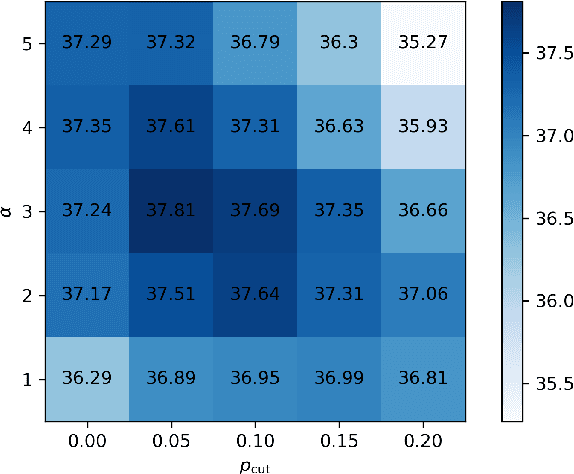
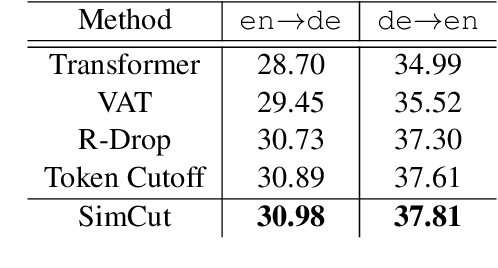
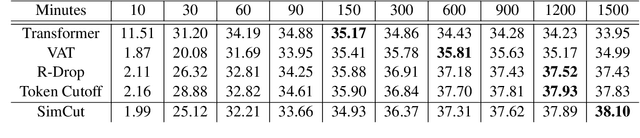
We introduce Bi-SimCut: a simple but effective training strategy to boost neural machine translation (NMT) performance. It consists of two procedures: bidirectional pretraining and unidirectional finetuning. Both procedures utilize SimCut, a simple regularization method that forces the consistency between the output distributions of the original and the cutoff sentence pairs. Without leveraging extra dataset via back-translation or integrating large-scale pretrained model, Bi-SimCut achieves strong translation performance across five translation benchmarks (data sizes range from 160K to 20.2M): BLEU scores of 31.16 for en -> de and 38.37 for de -> en on the IWSLT14 dataset, 30.78 for en -> de and 35.15 for de -> en on the WMT14 dataset, and 27.17 for zh -> en on the WMT17 dataset. SimCut is not a new method, but a version of Cutoff (Shen et al., 2020) simplified and adapted for NMT, and it could be considered as a perturbation-based method. Given the universality and simplicity of SimCut and Bi-SimCut, we believe they can serve as strong baselines for future NMT research.
Mixup Decoding for Diverse Machine Translation
Sep 14, 2021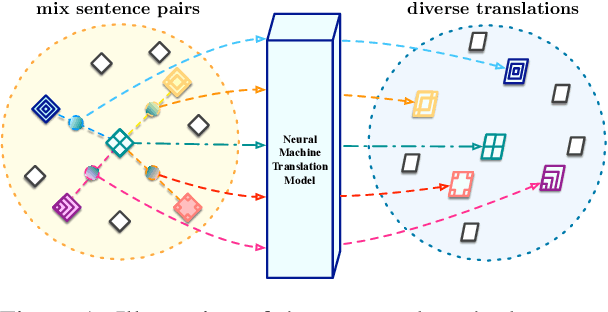

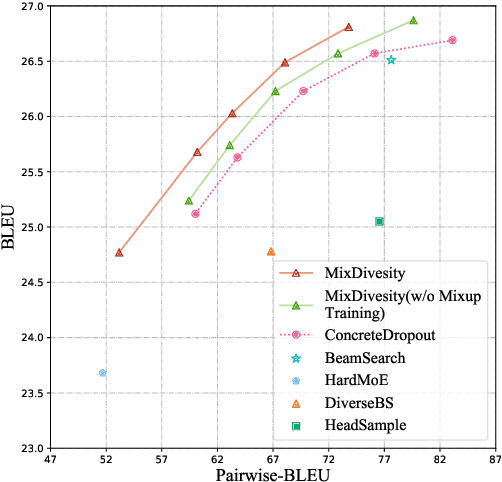
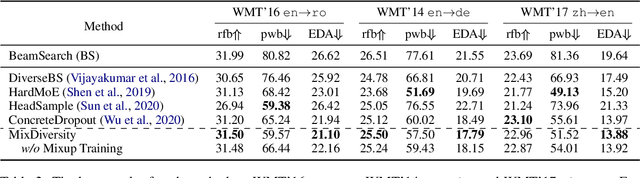
Diverse machine translation aims at generating various target language translations for a given source language sentence. Leveraging the linear relationship in the sentence latent space introduced by the mixup training, we propose a novel method, MixDiversity, to generate different translations for the input sentence by linearly interpolating it with different sentence pairs sampled from the training corpus when decoding. To further improve the faithfulness and diversity of the translations, we propose two simple but effective approaches to select diverse sentence pairs in the training corpus and adjust the interpolation weight for each pair correspondingly. Moreover, by controlling the interpolation weight, our method can achieve the trade-off between faithfulness and diversity without any additional training, which is required in most of the previous methods. Experiments on WMT'16 en-ro, WMT'14 en-de, and WMT'17 zh-en are conducted to show that our method substantially outperforms all previous diverse machine translation methods.
BSTC: A Large-Scale Chinese-English Speech Translation Dataset
Apr 27, 2021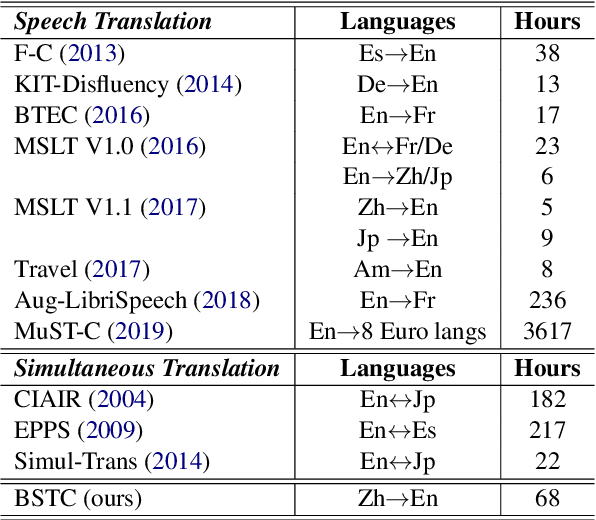
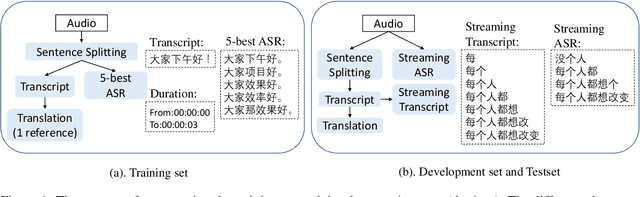

This paper presents BSTC (Baidu Speech Translation Corpus), a large-scale Chinese-English speech translation dataset. This dataset is constructed based on a collection of licensed videos of talks or lectures, including about 68 hours of Mandarin data, their manual transcripts and translations into English, as well as automated transcripts by an automatic speech recognition (ASR) model. We have further asked three experienced interpreters to simultaneously interpret the testing talks in a mock conference setting. This corpus is expected to promote the research of automatic simultaneous translation as well as the development of practical systems. We have organized simultaneous translation tasks and used this corpus to evaluate automatic simultaneous translation systems.
Synchronous Speech Recognition and Speech-to-Text Translation with Interactive Decoding
Dec 16, 2019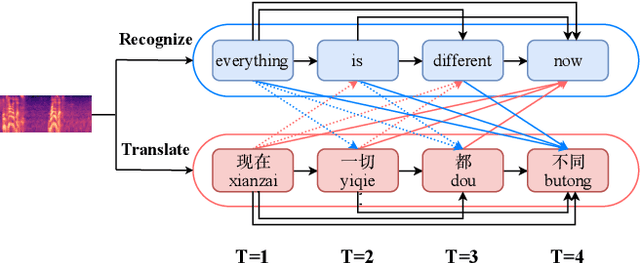
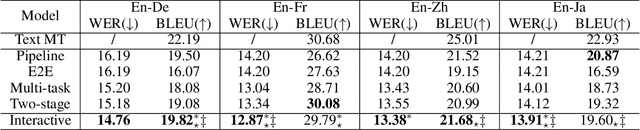
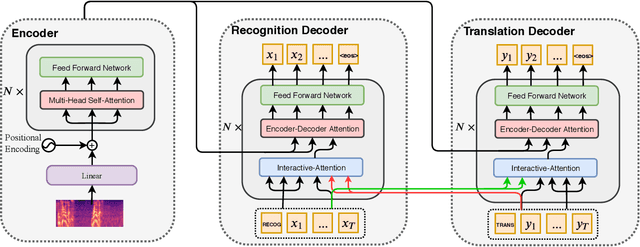
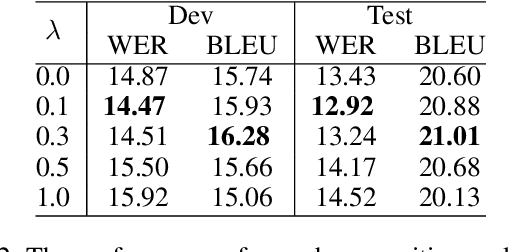
Speech-to-text translation (ST), which translates source language speech into target language text, has attracted intensive attention in recent years. Compared to the traditional pipeline system, the end-to-end ST model has potential benefits of lower latency, smaller model size, and less error propagation. However, it is notoriously difficult to implement such a model without transcriptions as intermediate. Existing works generally apply multi-task learning to improve translation quality by jointly training end-to-end ST along with automatic speech recognition (ASR). However, different tasks in this method cannot utilize information from each other, which limits the improvement. Other works propose a two-stage model where the second model can use the hidden state from the first one, but its cascade manner greatly affects the efficiency of training and inference process. In this paper, we propose a novel interactive attention mechanism which enables ASR and ST to perform synchronously and interactively in a single model. Specifically, the generation of transcriptions and translations not only relies on its previous outputs but also the outputs predicted in the other task. Experiments on TED speech translation corpora have shown that our proposed model can outperform strong baselines on the quality of speech translation and achieve better speech recognition performances as well.