 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoRA: Confidence-Rationale Alignment for Reliable Chain-of-Thought Reasoning
Jun 12, 2026Chain-of-thought (CoT) reasoning can improve LLM performance, but high answer confidence may be misleading when the accompanying CoT rationale is plausible yet incomplete or poorly supported. We study confidence--rationale alignment: whether a model's confidence in its committed answer is justified by its generated rationale. We introduce a GRPO-based reinforcement learning framework that jointly rewards answer correctness, committed-answer probability, and rubric-based rationale support, where the rubric assesses grounding, coherence, task match, and connection to the selected answer without revealing the gold answer to the judge. Across MedQA, MathQA, and OpenBookQA using three open-weight LLMs, our method reduces the confidence--rationale alignment error by up to 26.51% compared with untuned checkpoints, SFT, and correctness-only GRPO, while maintaining competitive accuracy and often improving calibration. These results show that reliable CoT reasoning requires not only confident answers, but rationales that substantively support them.
RadOT-Eval: Auditable Structured-Evidence Transport for Radiology Report Evaluation
Jun 07, 2026Automatic evaluation is critical for high-stakes text generation, where errors often involve omitted findings, hallucinated content, polarity reversals, location changes, uncertainty mismatches, and temporal-comparison errors rather than low surface similarity alone. Radiology report generation provides a challenging test case because generated reports must preserve structured clinical evidence across sources. We present RadOT-Eval, an interpretable structured-evidence optimal transport framework for offline auditing of radiology report generation. RadOT-Eval decomposes reference and candidate reports into attribute-structured clinical evidence units, aligns corresponding evidence using entropy-regularized optimal transport, and uses clinically meaningful side-channel discrepancies in a monotone risk model to predict error burden. All transport, feature, and readout choices are selected using the ReXVal dataset, and the frozen system is evaluated on the independent RadEvalX dataset. RadOT-Eval achieves Spearman correlations of 0.715, 0.548, and 0.399 with total, clinically significant, and clinically insignificant annotated error burden, respectively, yielding higher point estimates than standard evaluation metrics and the open-source large language model (LLM)-based evaluator GREEN-radllama2-7B. In a frozen auxiliary corruption-sensitivity stress test on ReXErr-v1, RadOT-Eval achieves 0.768 AUROC and a 0.990 corrupted-greater-than-clean paired win rate. These results show that structured evidence transport provides an auditable, rank-oriented evaluation tool for high-stakes generated clinical text under ReXVal-only model selection and frozen RadEvalX testing.
Vectors Are Not Neutral: Sensitive-Information Inference from Exported LLM Representations in Summarization
May 26, 2026Large language model (LLM) summarization systems may pass compact vector representations of private inputs to downstream retrieval, monitoring, audit, or analytic workflows. Even when source documents remain access-restricted, derived vectors may be handled under different access controls and still support sensitive-information inference, creating a residual information-disclosure risk. We study this issue in clinical discharge-summary generation as a high-stakes case study, using electronic health record (EHR)-recorded race as a controlled sensitive-label audit. We audit two artifacts that a system might retain or expose to downstream components: the final prompt-token hidden state and the mean-pooled prompt representation. Our results show that reducing recoverability of the case-study sensitive label from one exported artifact does not necessarily reduce recoverability from another. As a mitigation case study, we introduce SurfaceLoRA, an exported-vector-targeted parameter-efficient fine-tuning method that uses a gradient-reversal discriminator attached to a designated exported vector. Under a balanced five-way probing protocol, SurfaceLoRA reduces EHR-recorded race recoverability from the targeted final-token artifact toward chance while preserving summarization utility, yet recoverability remains substantially higher from untargeted pooled artifacts. These findings show that privacy auditing and mitigation should be performed on the exact vector artifact retained or exposed to downstream components.
Robust Nasality Representation Learning for Cleft Palate-Related Velopharyngeal Dysfunction Screening in Real-World Settings
Mar 18, 2026Velopharyngeal dysfunction (VPD) is characterized by inadequate velopharyngeal closure during speech and often causes hypernasality and reduced intelligibility. Although speech-based machine learning models can perform well under standardized clinical recording conditions, their performance often drops in real-world settings because of domain shift caused by differences in devices, channels, noise, and room acoustics. To improve robustness, we propose a two-stage framework for VPD screening. First, a nasality-focused speech representation is learned by supervised contrastive pre-training on an auxiliary corpus with phoneme alignments, using oral-context versus nasal-context supervision. Second, the encoder is frozen and used with lightweight classifiers on 0.5-second speech chunks, whose probabilities are aggregated to produce recording-level decisions with a fixed threshold. On an in-domain clinical cohort of 82 subjects, the proposed method achieved perfect recording-level screening performance (macro-F1 = 1.000, accuracy = 1.000). On a separate out-of-domain set of 131 heterogeneous public Internet recordings, large pretrained speech representations degraded substantially, while MFCC was the strongest baseline (macro-F1 = 0.612, accuracy = 0.641). The proposed method achieved the best out-of-domain performance (macro-F1 = 0.679, accuracy = 0.695), improving on the strongest baseline under the same evaluation protocol. These results suggest that learning a nasality-focused representation before clinical classification can reduce sensitivity to recording artifacts and improve robustness for deployable speech-based VPD screening.
VERI-DPO: Evidence-Aware Alignment for Clinical Summarization via Claim Verification and Direct Preference Optimization
Mar 11, 2026Brief Hospital Course (BHC) narratives must be clinically useful yet faithful to fragmented EHR evidence. LLM-based clinical summarizers still introduce unsupported statements, and alignment can encourage omissions ("say-less" degeneration). We introduce VERI-DPO, which uses claim verification to mine preferences and distill them into the summarizer with Direct Preference Optimization (DPO). On MIMIC-III-Ext-VeriFact-BHC (100 ICU patients; patient-level splits), we train a retrieval-augmented verifier to label claim-evidence pairs as Supported, Not Supported, or Not Addressed via a single-token format. The verifier scores sentence-level claims from sampled BHC candidates and aggregates margins into a coverage-aware utility to mine length-controlled, contradiction-anchored preference pairs. On held-out patients, verifier-mined preferences separate candidates by contradiction density, and VERI-DPO reduces Not Supported claim rates from 10.7% to 1.9% (local verifier judge) and from 11.6% to 6.4% (GPT-4o judge), while improving validity from 76.7% to 82.5% and maintaining informative length.
Optimizing Domain-Adaptive Self-Supervised Learning for Clinical Voice-Based Disease Classification
Jan 29, 2026The human voice is a promising non-invasive digital biomarker, yet deep learning for voice-based health analysis is hindered by data scarcity and domain mismatch, where models pre-trained on general audio fail to capture the subtle pathological features characteristic of clinical voice data. To address these challenges, we investigate domain-adaptive self-supervised learning (SSL) with Masked Autoencoders (MAE) and demonstrate that standard configurations are suboptimal for health-related audio. Using the Bridge2AI-Voice dataset, a multi-institutional collection of pathological voices, we systematically examine three performance-critical factors: reconstruction loss (Mean Absolute Error vs. Mean Squared Error), normalization (patch-wise vs. global), and masking (random vs. content-aware). Our optimized design, which combines Mean Absolute Error (MA-Error) loss, patch-wise normalization, and content-aware masking, achieves a Macro F1 of $0.688 \pm 0.009$ (over 10 fine-tuning runs), outperforming a strong out-of-domain SSL baseline pre-trained on large-scale general audio, which has a Macro F1 of $0.663 \pm 0.011$. The results show that MA-Error loss improves robustness and content-aware masking boosts performance by emphasizing information-rich regions. These findings highlight the importance of component-level optimization in data-constrained medical applications that rely on audio data.
East: Efficient and Accurate Secure Transformer Framework for Inference
Aug 19, 2023



Transformer has been successfully used in practical applications, such as ChatGPT, due to its powerful advantages. However, users' input is leaked to the model provider during the service. With people's attention to privacy, privacy-preserving Transformer inference is on the demand of such services. Secure protocols for non-linear functions are crucial in privacy-preserving Transformer inference, which are not well studied. Thus, designing practical secure protocols for non-linear functions is hard but significant to model performance. In this work, we propose a framework \emph{East} to enable efficient and accurate secure Transformer inference. Firstly, we propose a new oblivious piecewise polynomial evaluation algorithm and apply it to the activation functions, which reduces the runtime and communication of GELU by over 1.5$\times$ and 2.5$\times$, compared to prior arts. Secondly, the secure protocols for softmax and layer normalization are carefully designed to faithfully maintain the desired functionality. Thirdly, several optimizations are conducted in detail to enhance the overall efficiency. We applied \emph{East} to BERT and the results show that the inference accuracy remains consistent with the plaintext inference without fine-tuning. Compared to Iron, we achieve about 1.8$\times$ lower communication within 1.2$\times$ lower runtime.
ERNIE 3.0 Tiny: Frustratingly Simple Method to Improve Task-Agnostic Distillation Generalization
Jan 09, 2023



Task-agnostic knowledge distillation attempts to address the problem of deploying large pretrained language model in resource-constrained scenarios by compressing a large pretrained model called teacher into a smaller one called student such that the student can be directly finetuned on downstream tasks and retains comparable performance. However, we empirically find that there is a generalization gap between the student and the teacher in existing methods. In this work, we show that we can leverage multi-task learning in task-agnostic distillation to advance the generalization of the resulted student. In particular, we propose Multi-task Infused Task-agnostic Knowledge Distillation (MITKD). We first enhance the teacher by multi-task training it on multiple downstream tasks and then perform distillation to produce the student. Experimental results demonstrate that our method yields a student with much better generalization, significantly outperforms existing baselines, and establishes a new state-of-the-art result on in-domain, out-domain, and low-resource datasets in the setting of task-agnostic distillation. Moreover, our method even exceeds an 8x larger BERT$_{\text{Base}}$ on SQuAD and four GLUE tasks. In addition, by combining ERNIE 3.0, our method achieves state-of-the-art results on 10 Chinese datasets.
Learning Weakly-Supervised Contrastive Representations
Feb 18, 2022



We argue that a form of the valuable information provided by the auxiliary information is its implied data clustering information. For instance, considering hashtags as auxiliary information, we can hypothesize that an Instagram image will be semantically more similar with the same hashtags. With this intuition, we present a two-stage weakly-supervised contrastive learning approach. The first stage is to cluster data according to its auxiliary information. The second stage is to learn similar representations within the same cluster and dissimilar representations for data from different clusters. Our empirical experiments suggest the following three contributions. First, compared to conventional self-supervised representations, the auxiliary-information-infused representations bring the performance closer to the supervised representations, which use direct downstream labels as supervision signals. Second, our approach performs the best in most cases, when comparing our approach with other baseline representation learning methods that also leverage auxiliary data information. Third, we show that our approach also works well with unsupervised constructed clusters (e.g., no auxiliary information), resulting in a strong unsupervised representation learning approach.
ERNIE 3.0 Titan: Exploring Larger-scale Knowledge Enhanced Pre-training for Language Understanding and Generation
Dec 23, 2021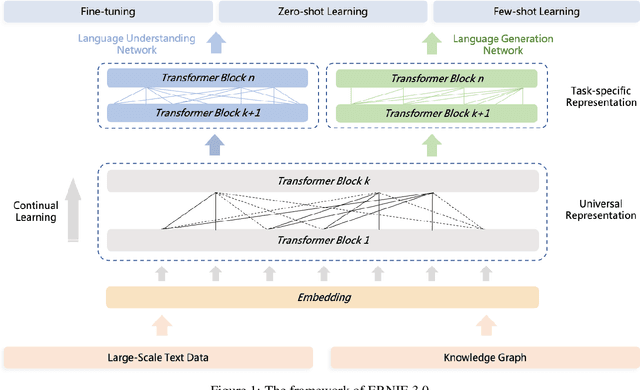
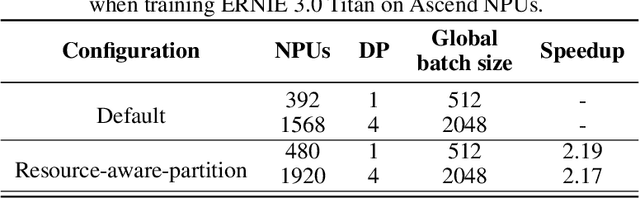
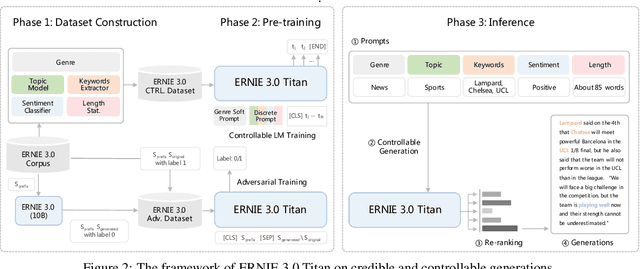
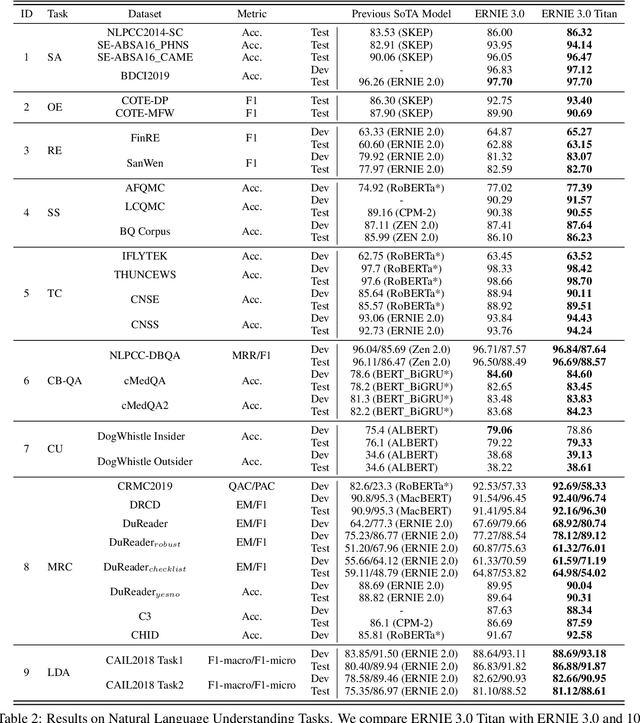
Pre-trained language models have achieved state-of-the-art results in various Natural Language Processing (NLP) tasks. GPT-3 has shown that scaling up pre-trained language models can further exploit their enormous potential. A unified framework named ERNIE 3.0 was recently proposed for pre-training large-scale knowledge enhanced models and trained a model with 10 billion parameters. ERNIE 3.0 outperformed the state-of-the-art models on various NLP tasks. In order to explore the performance of scaling up ERNIE 3.0, we train a hundred-billion-parameter model called ERNIE 3.0 Titan with up to 260 billion parameters on the PaddlePaddle platform. Furthermore, we design a self-supervised adversarial loss and a controllable language modeling loss to make ERNIE 3.0 Titan generate credible and controllable texts. To reduce the computation overhead and carbon emission, we propose an online distillation framework for ERNIE 3.0 Titan, where the teacher model will teach students and train itself simultaneously. ERNIE 3.0 Titan is the largest Chinese dense pre-trained model so far. Empirical results show that the ERNIE 3.0 Titan outperforms the state-of-the-art models on 68 NLP datasets.