 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemNovo: Look Back at the Spectrum for Balanced De Novo Peptide Sequencing from Mass Spectrometry
Jun 10, 2026De novo peptide sequencing from tandem mass spectrometry is pivotal in proteomics, enabling identification of novel peptides without reference databases. While recent Transformer-based encoder-decoder models have achieved remarkable performance, we uncover a critical pathology in their inference dynamics. Through comprehensive feature scaling experiments, we demonstrate that existing auto-regressive peptide decoders tend to over-rely on generated-sequence priors while progressively under-utilizing fine-grained physical evidence from the input mass spectrum. This phenomenon leads to suboptimal results, where generated peptide sequences are biologically plausible yet not faithful to the input spectrum. To rectify this, we propose MemNovo, a training-free and plug-and-play mechanism that re-balances peptide and spectral contributions at inference time. MemNovo alleviates the information bottleneck by establishing a persistent spectral memory bank and injecting retrieved features directly into the final decoding stage via an ultra-conservative residual connection. Theoretical analysis confirms that this mechanism restores the mutual information between the decoder state and the raw spectrum. Extensive experiments on the Nine Species benchmark with two representative baselines, Casanovo and InstaNovo, demonstrate that MemNovo consistently improves both amino acid precision and peptide precision, achieving up to 39.1% relative improvement in peptide precision for Casanovo and up to 3.9% for InstaNovo, with negligible computational overhead.
* Code: https://github.com/AIMS-Lab-HKUSTGZ/MemNovo
scTranslation: A Comprehensive Benchmark for Single-Cell Multi-Omics Modality Translation
Jun 02, 2026Simultaneous measurement of multiple omics modalities in single cells enables researchers to gain a more comprehensive understanding of cellular states and regulatory mechanisms. However, due to high experimental costs, significant noise, and incomplete modality coverage, a variety of computational methods for modality translation have emerged in recent years. Despite the development of translation models, there is still a lack of systematic benchmark evaluation in terms of datasets, evaluation metrics, and influencing factors. To address this, we present scTranslation, a comprehensive benchmark for single-cell multi-omics modality translation tasks. It includes diverse translation datasets, integrates state-of-the-art models, and provides a comprehensive evaluation metrics. In addition, we assess model performance under different scenarios, such as feature selection, feature quality, and few-shot settings. These factors significantly affect model performance but have rarely been systematically studied before. Leveraging this benchmark, we conduct a large-scale study of current methods, report many insightful findings that open up new possibilities for future development. The benchmark is open-sourced to facilitate future research. The code is anonymously released at https://github.com/Bunnybeibei/scTranslation.
scHelix: Asymmetric Dual-Stream Integration via Explicit Gene-Level Disentanglement
May 18, 2026A critical challenge in single-cell RNA sequencing (scRNA-seq) integration is resolving the tension between eliminating batch effects and maintaining biological fidelity. While recent evidence indicates that batch effects manifest heterogeneously across genes, most existing methods process the transcriptome uniformly, frequently resulting in over-correction and loss of subtle biological signals. To address this, we present scHelix, a dataset-adaptive framework that fundamentally changes how features are processed by explicitly partitioning genes into domain-invariant Anchors and domain-sensitive Variants at the input level. scHelix utilizes a dual-stream sparse diffusion encoder equipped with stop-gradient graph caching to efficiently learn multi-scale structural representations. The core of our approach is a novel asymmetric Align-Refine-Fuse protocol: the unstable Variant stream is first aligned to the robust topology of the Anchor stream, followed by a conservative refinement phase where the Anchor stream absorbs denoised details via bounded residual gating. This divide-and-conquer architecture prevents shortcut learning and ensures robust batch removal without compromising the integrity of biological clusters. Extensive benchmarking demonstrates that scHelix outperforms state-of-the-art methods.
LoReC: Rethinking Large Language Models for Graph Data Analysis
Apr 20, 2026The advent of Large Language Models (LLMs) has fundamentally reshaped the way we interact with graphs, giving rise to a new paradigm called GraphLLM. As revealed in recent studies, graph learning can benefit from LLMs. However, we observe limited benefits when we directly utilize LLMs to make predictions for graph-related tasks within GraphLLM paradigm, which even yields suboptimal results compared to conventional GNN-based approaches. Through in-depth analysis, we find this failure can be attributed to LLMs' limited capability for processing graph data and their tendency to overlook graph information. To address this issue, we propose LoReC (Look, Remember, and Contrast), a novel plug-and-play method for GraphLLM paradigm, which enhances LLM's understanding of graph data through three stages: (1) Look: redistributing attention to graph; (2) Remember: re-injecting graph information into the Feed-Forward Network (FFN); (3) Contrast: rectifying the vanilla logits produced in the decoding process. Extensive experiments demonstrate that LoReC brings notable improvements over current GraphLLM methods and outperforms GNN-based approaches across diverse datasets. The implementation is available at https://github.com/Git-King-Zhan/LoReC.
MAT-Cell: A Multi-Agent Tree-Structured Reasoning Framework for Batch-Level Single-Cell Annotation
Apr 07, 2026Automated cellular reasoning faces a core dichotomy: supervised methods fall into the Reference Trap and fail to generalize to out-of-distribution cell states, while large language models (LLMs), without grounded biological priors, suffer from a Signal-to-Noise Paradox that produces spurious associations. We propose MAT-Cell, a neuro-symbolic reasoning framework that reframes single-cell analysis from black-box classification into constructive, verifiable proof generation. MAT-Cell injects symbolic constraints through adaptive Retrieval-Augmented Generation (RAG) to ground neural reasoning in biological axioms and reduce transcriptomic noise. It further employs a dialectic verification process with homogeneous rebuttal agents to audit and prune reasoning paths, forming syllogistic derivation trees that enforce logical consistency.Across large-scale and cross-species benchmarks, MAT-Cell significantly outperforms state-of-the-art (SOTA) models and maintains robust per-formance in challenging scenarios where baselinemethods severely degrade. Code is available at https://gith ub.com/jiangliu91/MAT-Cell-A-Mul ti-Agent-Tree-Structured-Reasoni ng-Framework-for-Batch-Level-Sin gle-Cell-Annotation.
VecFormer: Towards Efficient and Generalizable Graph Transformer with Graph Token Attention
Feb 23, 2026Graph Transformer has demonstrated impressive capabilities in the field of graph representation learning. However, existing approaches face two critical challenges: (1) most models suffer from exponentially increasing computational complexity, making it difficult to scale to large graphs; (2) attention mechanisms based on node-level operations limit the flexibility of the model and result in poor generalization performance in out-of-distribution (OOD) scenarios. To address these issues, we propose \textbf{VecFormer} (the \textbf{Vec}tor Quantized Graph Trans\textbf{former}), an efficient and highly generalizable model for node classification, particularly under OOD settings. VecFormer adopts a two-stage training paradigm. In the first stage, two codebooks are used to reconstruct the node features and the graph structure, aiming to learn the rich semantic \texttt{Graph Codes}. In the second stage, attention mechanisms are performed at the \texttt{Graph Token} level based on the transformed cross codebook, reducing computational complexity while enhancing the model's generalization capability. Extensive experiments on datasets of various sizes demonstrate that VecFormer outperforms the existing Graph Transformer in both performance and speed.
Regressor-guided Diffusion Model for De Novo Peptide Sequencing with Explicit Mass Control
Feb 23, 2026The discovery of novel proteins relies on sensitive protein identification, for which de novo peptide sequencing (DNPS) from mass spectra is a crucial approach. While deep learning has advanced DNPS, existing models inadequately enforce the fundamental mass consistency constraint, that a predicted peptide's mass must match the experimental measured precursor mass. Previous DNPS methods often treat this critical information as a simple input feature or use it in post-processing, leading to numerous implausible predictions that do not adhere to this fundamental physical property. To address this limitation, we introduce DiffuNovo, a novel regressor-guided diffusion model for de novo peptide sequencing that provides explicit peptide-level mass control. Our approach integrates the mass constraint at two critical stages: during training, a novel peptide-level mass loss guides model optimization, while at inference, regressor-based guidance from gradient-based updates in the latent space steers the generation to compel the predicted peptide adheres to the mass constraint. Comprehensive evaluations on established benchmarks demonstrate that DiffuNovo surpasses state-of-the-art methods in DNPS accuracy. Additionally, as the first DNPS model to employ a diffusion model as its core backbone, DiffuNovo leverages the powerful controllability of diffusion architecture and achieves a significant reduction in mass error, thereby producing much more physically plausible peptides. These innovations represent a substantial advancement toward robust and broadly applicable DNPS. The source code is available in the supplementary material.
Unrewarded Exploration in Large Language Models Reveals Latent Learning from Psychology
Jan 30, 2026Latent learning, classically theorized by Tolman, shows that biological agents (e.g., rats) can acquire internal representations of their environment without rewards, enabling rapid adaptation once rewards are introduced. In contrast, from a cognitive science perspective, reward learning remains overly dependent on external feedback, limiting flexibility and generalization. Although recent advances in the reasoning capabilities of large language models (LLMs), such as OpenAI-o1 and DeepSeek-R1, mark a significant breakthrough, these models still rely primarily on reward-centric reinforcement learning paradigms. Whether and how the well-established phenomenon of latent learning in psychology can inform or emerge within LLMs' training remains largely unexplored. In this work, we present novel findings from our experiments that LLMs also exhibit the latent learning dynamics. During an initial phase of unrewarded exploration, LLMs display modest performance improvements, as this phase allows LLMs to organize task-relevant knowledge without being constrained by reward-driven biases, and performance is further enhanced once rewards are introduced. LLMs post-trained under this two-stage exploration regime ultimately achieve higher competence than those post-trained with reward-based reinforcement learning throughout. Beyond these empirical observations, we also provide theoretical analyses for our experiments explaining why unrewarded exploration yields performance gains, offering a mechanistic account of these dynamics. Specifically, we conducted extensive experiments across multiple model families and diverse task domains to establish the existence of the latent learning dynamics in LLMs.
OmegaUse: Building a General-Purpose GUI Agent for Autonomous Task Execution
Jan 28, 2026Graphical User Interface (GUI) agents show great potential for enabling foundation models to complete real-world tasks, revolutionizing human-computer interaction and improving human productivity. In this report, we present OmegaUse, a general-purpose GUI agent model for autonomous task execution on both mobile and desktop platforms, supporting computer-use and phone-use scenarios. Building an effective GUI agent model relies on two factors: (1) high-quality data and (2) effective training methods. To address these, we introduce a carefully engineered data-construction pipeline and a decoupled training paradigm. For data construction, we leverage rigorously curated open-source datasets and introduce a novel automated synthesis framework that integrates bottom-up autonomous exploration with top-down taxonomy-guided generation to create high-fidelity synthetic data. For training, to better leverage these data, we adopt a two-stage strategy: Supervised Fine-Tuning (SFT) to establish fundamental interaction syntax, followed by Group Relative Policy Optimization (GRPO) to improve spatial grounding and sequential planning. To balance computational efficiency with agentic reasoning capacity, OmegaUse is built on a Mixture-of-Experts (MoE) backbone. To evaluate cross-terminal capabilities in an offline setting, we introduce OS-Nav, a benchmark suite spanning multiple operating systems: ChiM-Nav, targeting Chinese Android mobile environments, and Ubu-Nav, focusing on routine desktop interactions on Ubuntu. Extensive experiments show that OmegaUse is highly competitive across established GUI benchmarks, achieving a state-of-the-art (SOTA) score of 96.3% on ScreenSpot-V2 and a leading 79.1% step success rate on AndroidControl. OmegaUse also performs strongly on OS-Nav, reaching 74.24% step success on ChiM-Nav and 55.9% average success on Ubu-Nav.
MergeDNA: Context-aware Genome Modeling with Dynamic Tokenization through Token Merging
Nov 17, 2025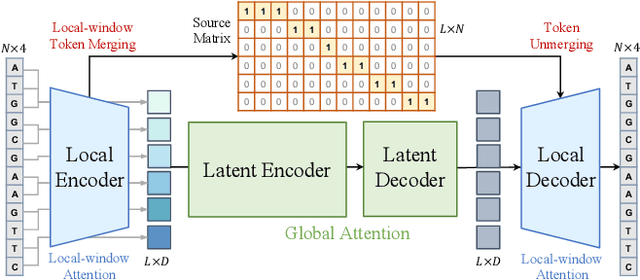

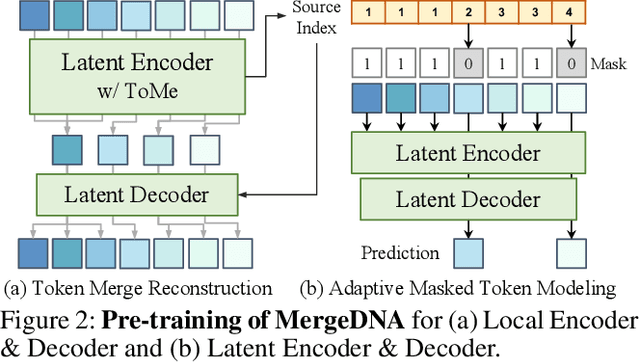
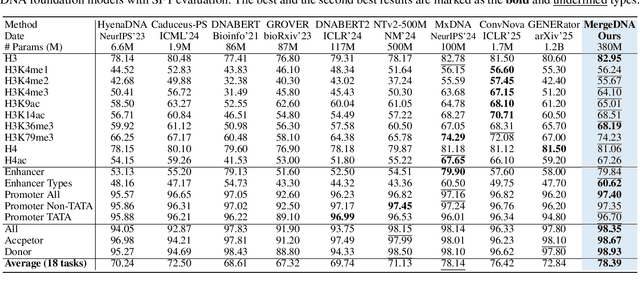
Modeling genomic sequences faces two unsolved challenges: the information density varies widely across different regions, while there is no clearly defined minimum vocabulary unit. Relying on either four primitive bases or independently designed DNA tokenizers, existing approaches with naive masked language modeling pre-training often fail to adapt to the varying complexities of genomic sequences. Leveraging Token Merging techniques, this paper introduces a hierarchical architecture that jointly optimizes a dynamic genomic tokenizer and latent Transformers with context-aware pre-training tasks. As for network structures, the tokenization module automatically chunks adjacent bases into words by stacking multiple layers of the differentiable token merging blocks with local-window constraints, then a Latent Encoder captures the global context of these merged words by full-attention blocks. Symmetrically employing a Latent Decoder and a Local Decoder, MergeDNA learns with two pre-training tasks: Merged Token Reconstruction simultaneously trains the dynamic tokenization module and adaptively filters important tokens, while Adaptive Masked Token Modeling learns to predict these filtered tokens to capture informative contents. Extensive experiments show that MergeDNA achieves superior performance on three popular DNA benchmarks and several multi-omics tasks with fine-tuning or zero-shot evaluation, outperforming typical tokenization methods and large-scale DNA foundation models.