 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDFlare: Scaling Up Draft Capacity for Block Diffusion Speculative Decoding
Jun 01, 2026Block diffusion speculative decoding accelerates LLM inference by predicting all tokens within a block simultaneously for the target model to verify in parallel. Predicting an entire block at once requires a sufficiently capable draft model and effective utilization of the target model's internal knowledge. However, the state-of-the-art method DFlash constrains all draft layers to share a single fused representation derived from only a few target layers, limiting per-layer expressiveness and hindering further scaling of draft capacity. In this paper, we present \modelname, which flares out the narrow conditioning bottleneck of DFlash through a lightweight layer-wise fusion mechanism: each draft layer attends to its own learnable combination of a broad set of target layers at negligible overhead, simultaneously injecting richer target knowledge and providing every draft layer with a distinct input. This enhanced per-layer expressiveness enables scaling the draft model to deeper architectures with consistent gains. We further scale training data from 800K to 2.4M samples to fully exploit the enlarged capacity. On six benchmarks spanning mathematical reasoning, code generation, and conversation, \modelname attains average wall-clock speedups of 5.52x on Qwen3-4B, 5.46x on Qwen3-8B, and 3.91x on GPT-OSS-20B, improving over DFlash by roughly 11\%, 8\%, and 5\% respectively. Our code is available at https://github.com/Tencent/AngelSlim.
Video2GUI: Synthesizing Large-Scale Interaction Trajectories for Generalized GUI Agent Pretraining
May 14, 2026Recent advances in multimodal large language models have driven growing interest in graphical user interface (GUI) agents, yet their generalization remains constrained by the scarcity of large-scale training data spanning diverse real-world applications. Existing datasets rely heavily on costly manual annotations and are typically confined to narrow domains. To address this challenge, we propose Video2GUI, a fully automated framework that extracts grounded GUI interaction trajectories directly from unlabeled Internet videos. Video2GUI employs a coarse-to-fine filtering strategy to identify high-quality GUI tutorial videos and convert them into structured agent trajectories. Applying this pipeline to 500 million video metadata entries, we construct WildGUI, a large-scale dataset containing 12 million interaction trajectories spanning over 1,500 applications and websites. Pre-training Qwen2.5-VL and Mimo-VL on WildGUI yields consistent improvements of 5-20% across multiple GUI grounding and action benchmarks, matching or surpassing state-of-the-art performance. We will release both the WildGUI dataset and the Video2GUI pipeline to support future research of GUI agents.
Learning to Draft: Adaptive Speculative Decoding with Reinforcement Learning
Mar 02, 2026Speculative decoding accelerates large language model (LLM) inference by using a small draft model to generate candidate tokens for a larger target model to verify. The efficacy of this technique hinges on the trade-off between the time spent on drafting candidates and verifying them. However, current state-of-the-art methods rely on a static time allocation, while recent dynamic approaches optimize for proxy metrics like acceptance length, often neglecting the true time cost and treating the drafting and verification phases in isolation. To address these limitations, we introduce Learning to Draft (LTD), a novel method that directly optimizes for throughput of each draft-and-verify cycle. We formulate the problem as a reinforcement learning environment and train two co-adaptive policies to dynamically coordinate the draft and verification phases. This encourages the policies to adapt to each other and explicitly maximize decoding efficiency. We conducted extensive evaluations on five diverse LLMs and four distinct tasks. Our results show that LTD achieves speedup ratios ranging from 2.24x to 4.32x, outperforming the state-of-the-art method Eagle3 up to 36.4%.
PaperBanana: Automating Academic Illustration for AI Scientists
Jan 30, 2026Despite rapid advances in autonomous AI scientists powered by language models, generating publication-ready illustrations remains a labor-intensive bottleneck in the research workflow. To lift this burden, we introduce PaperBanana, an agentic framework for automated generation of publication-ready academic illustrations. Powered by state-of-the-art VLMs and image generation models, PaperBanana orchestrates specialized agents to retrieve references, plan content and style, render images, and iteratively refine via self-critique. To rigorously evaluate our framework, we introduce PaperBananaBench, comprising 292 test cases for methodology diagrams curated from NeurIPS 2025 publications, covering diverse research domains and illustration styles. Comprehensive experiments demonstrate that PaperBanana consistently outperforms leading baselines in faithfulness, conciseness, readability, and aesthetics. We further show that our method effectively extends to the generation of high-quality statistical plots. Collectively, PaperBanana paves the way for the automated generation of publication-ready illustrations.
JudgeRLVR: Judge First, Generate Second for Efficient Reasoning
Jan 13, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has become a standard paradigm for reasoning in Large Language Models. However, optimizing solely for final-answer correctness often drives models into aimless, verbose exploration, where they rely on exhaustive trial-and-error tactics rather than structured planning to reach solutions. While heuristic constraints like length penalties can reduce verbosity, they often truncate essential reasoning steps, creating a difficult trade-off between efficiency and verification. In this paper, we argue that discriminative capability is a prerequisite for efficient generation: by learning to distinguish valid solutions, a model can internalize a guidance signal that prunes the search space. We propose JudgeRLVR, a two-stage judge-then-generate paradigm. In the first stage, we train the model to judge solution responses with verifiable answers. In the second stage, we fine-tune the same model with vanilla generating RLVR initialized from the judge. Compared to Vanilla RLVR using the same math-domain training data, JudgeRLVR achieves a better quality--efficiency trade-off for Qwen3-30B-A3B: on in-domain math, it delivers about +3.7 points average accuracy gain with -42\% average generation length; on out-of-domain benchmarks, it delivers about +4.5 points average accuracy improvement, demonstrating enhanced generalization.
DocLens : A Tool-Augmented Multi-Agent Framework for Long Visual Document Understanding
Nov 14, 2025Comprehending long visual documents, where information is distributed across extensive pages of text and visual elements, is a critical but challenging task for modern Vision-Language Models (VLMs). Existing approaches falter on a fundamental challenge: evidence localization. They struggle to retrieve relevant pages and overlook fine-grained details within visual elements, leading to limited performance and model hallucination. To address this, we propose DocLens, a tool-augmented multi-agent framework that effectively ``zooms in'' on evidence like a lens. It first navigates from the full document to specific visual elements on relevant pages, then employs a sampling-adjudication mechanism to generate a single, reliable answer. Paired with Gemini-2.5-Pro, DocLens achieves state-of-the-art performance on MMLongBench-Doc and FinRAGBench-V, surpassing even human experts. The framework's superiority is particularly evident on vision-centric and unanswerable queries, demonstrating the power of its enhanced localization capabilities.
FinRAGBench-V: A Benchmark for Multimodal RAG with Visual Citation in the Financial Domain
May 23, 2025Retrieval-Augmented Generation (RAG) plays a vital role in the financial domain, powering applications such as real-time market analysis, trend forecasting, and interest rate computation. However, most existing RAG research in finance focuses predominantly on textual data, overlooking the rich visual content in financial documents, resulting in the loss of key analytical insights. To bridge this gap, we present FinRAGBench-V, a comprehensive visual RAG benchmark tailored for finance which effectively integrates multimodal data and provides visual citation to ensure traceability. It includes a bilingual retrieval corpus with 60,780 Chinese and 51,219 English pages, along with a high-quality, human-annotated question-answering (QA) dataset spanning heterogeneous data types and seven question categories. Moreover, we introduce RGenCite, an RAG baseline that seamlessly integrates visual citation with generation. Furthermore, we propose an automatic citation evaluation method to systematically assess the visual citation capabilities of Multimodal Large Language Models (MLLMs). Extensive experiments on RGenCite underscore the challenging nature of FinRAGBench-V, providing valuable insights for the development of multimodal RAG systems in finance.
KNN-SSD: Enabling Dynamic Self-Speculative Decoding via Nearest Neighbor Layer Set Optimization
May 22, 2025Speculative Decoding (SD) has emerged as a widely used paradigm to accelerate the inference of large language models (LLMs) without compromising generation quality. It works by efficiently drafting multiple tokens using a compact model and then verifying them in parallel using the target LLM. Notably, Self-Speculative Decoding proposes skipping certain layers to construct the draft model, which eliminates the need for additional parameters or training. Despite its strengths, we observe in this work that drafting with layer skipping exhibits significant sensitivity to domain shifts, leading to a substantial drop in acceleration performance. To enhance the domain generalizability of this paradigm, we introduce KNN-SSD, an algorithm that leverages K-Nearest Neighbor (KNN) search to match different skipped layers with various domain inputs. We evaluated our algorithm in various models and multiple tasks, observing that its application leads to 1.3x-1.6x speedup in LLM inference.
MPO: Boosting LLM Agents with Meta Plan Optimization
Mar 04, 2025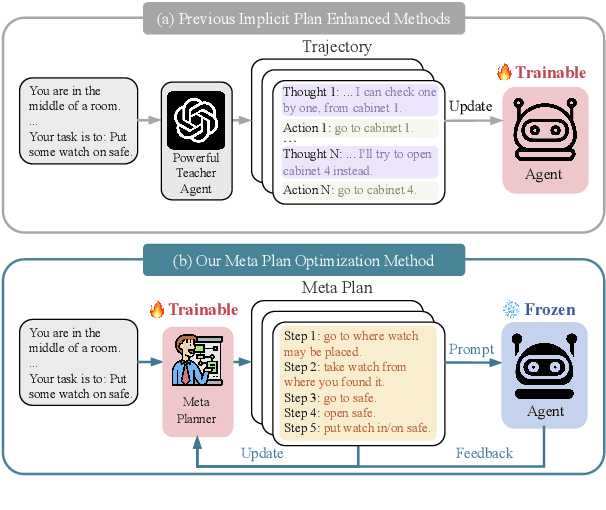

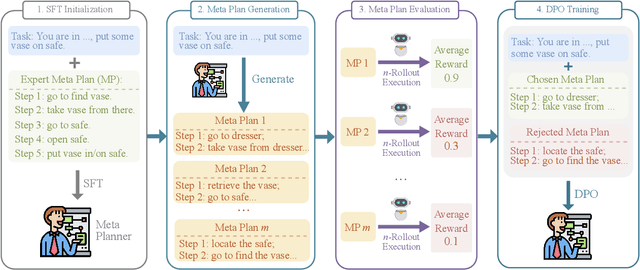
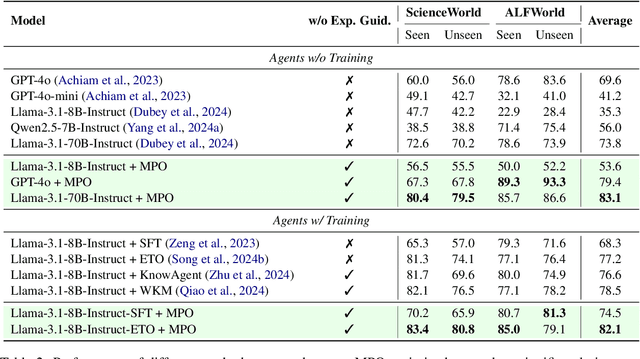
Recent advancements in large language models (LLMs) have enabled LLM-based agents to successfully tackle interactive planning tasks. However, despite their successes, existing approaches often suffer from planning hallucinations and require retraining for each new agent. To address these challenges, we propose the Meta Plan Optimization (MPO) framework, which enhances agent planning capabilities by directly incorporating explicit guidance. Unlike previous methods that rely on complex knowledge, which either require significant human effort or lack quality assurance, MPO leverages high-level general guidance through meta plans to assist agent planning and enables continuous optimization of the meta plans based on feedback from the agent's task execution. Our experiments conducted on two representative tasks demonstrate that MPO significantly outperforms existing baselines. Moreover, our analysis indicates that MPO provides a plug-and-play solution that enhances both task completion efficiency and generalization capabilities in previous unseen scenarios.
Chain-of-Thought Matters: Improving Long-Context Language Models with Reasoning Path Supervision
Feb 28, 2025



Recent advances in Large Language Models (LLMs) have highlighted the challenge of handling long-context tasks, where models need to reason over extensive input contexts to aggregate target information. While Chain-of-Thought (CoT) prompting has shown promise for multi-step reasoning, its effectiveness for long-context scenarios remains underexplored. Through systematic investigation across diverse tasks, we demonstrate that CoT's benefits generalize across most long-context scenarios and amplify with increasing context length. Motivated by this critical observation, we propose LongRePS, a process-supervised framework that teaches models to generate high-quality reasoning paths for enhanced long-context performance. Our framework incorporates a self-sampling mechanism to bootstrap reasoning paths and a novel quality assessment protocol specifically designed for long-context scenarios. Experimental results on various long-context benchmarks demonstrate the effectiveness of our approach, achieving significant improvements over outcome supervision baselines on both in-domain tasks (+13.6/+3.8 points for LLaMA/Qwen on MuSiQue) and cross-domain generalization (+9.3/+8.1 points on average across diverse QA tasks). Our code, data and trained models are made public to facilitate future research.