 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUNIMO-2: End-to-End Unified Vision-Language Grounded Learning
Mar 17, 2022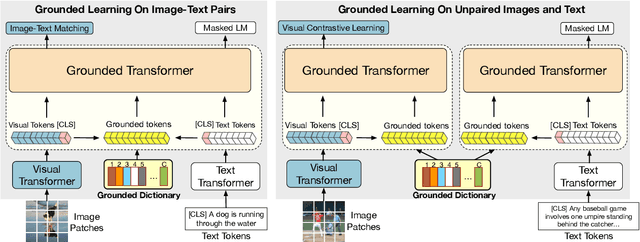
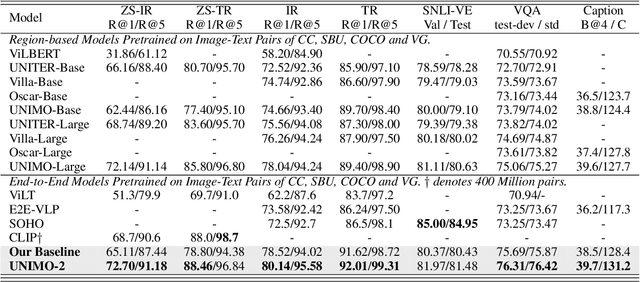
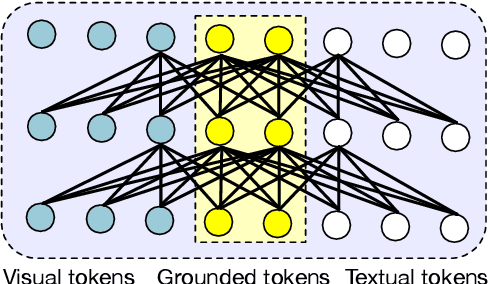

Vision-Language Pre-training (VLP) has achieved impressive performance on various cross-modal downstream tasks. However, most existing methods can only learn from aligned image-caption data and rely heavily on expensive regional features, which greatly limits their scalability and performance. In this paper, we propose an end-to-end unified-modal pre-training framework, namely UNIMO-2, for joint learning on both aligned image-caption data and unaligned image-only and text-only corpus. We build a unified Transformer model to jointly learn visual representations, textual representations and semantic alignment between images and texts. In particular, we propose to conduct grounded learning on both images and texts via a sharing grounded space, which helps bridge unaligned images and texts, and align the visual and textual semantic spaces on different types of corpora. The experiments show that our grounded learning method can improve textual and visual semantic alignment for improving performance on various cross-modal tasks. Moreover, benefiting from effective joint modeling of different types of corpora, our model also achieves impressive performance on single-modal visual and textual tasks. Our code and models are public at the UNIMO project page https://unimo-ptm.github.io/.
DU-VLG: Unifying Vision-and-Language Generation via Dual Sequence-to-Sequence Pre-training
Mar 17, 2022
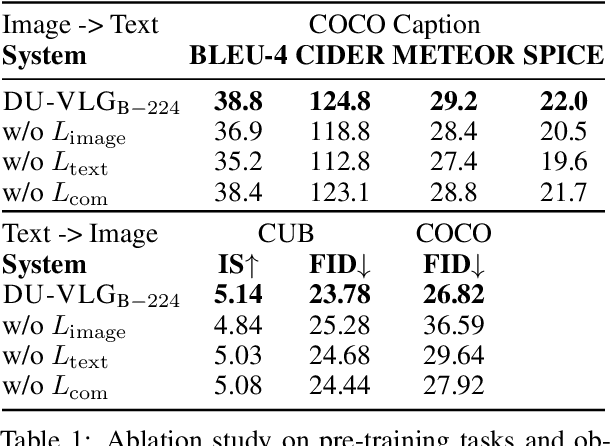
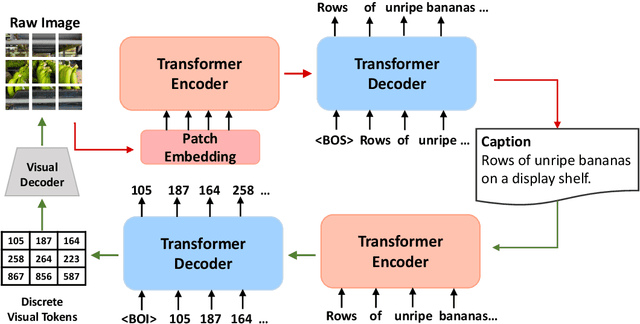
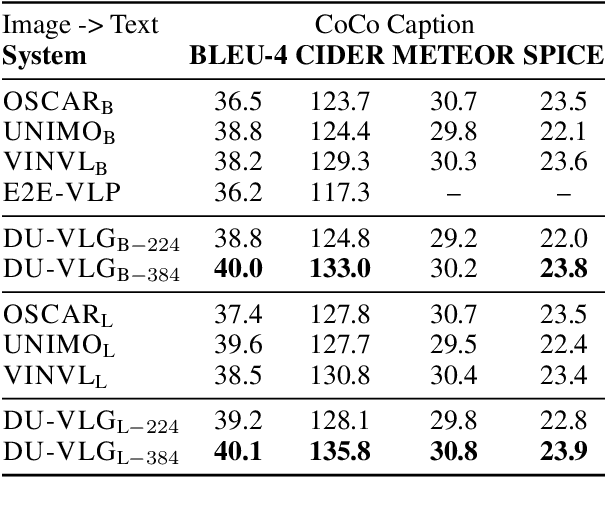
Due to the limitations of the model structure and pre-training objectives, existing vision-and-language generation models cannot utilize pair-wise images and text through bi-directional generation. In this paper, we propose DU-VLG, a framework which unifies vision-and-language generation as sequence generation problems. DU-VLG is trained with novel dual pre-training tasks: multi-modal denoising autoencoder tasks and modality translation tasks. To bridge the gap between image understanding and generation, we further design a novel commitment loss. We compare pre-training objectives on image captioning and text-to-image generation datasets. Results show that DU-VLG yields better performance than variants trained with uni-directional generation objectives or the variant without the commitment loss. We also obtain higher scores compared to previous state-of-the-art systems on three vision-and-language generation tasks. In addition, human judges further confirm that our model generates real and relevant images as well as faithful and informative captions.
Weakly Supervised Dense Video Captioning via Jointly Usage of Knowledge Distillation and Cross-modal Matching
May 18, 2021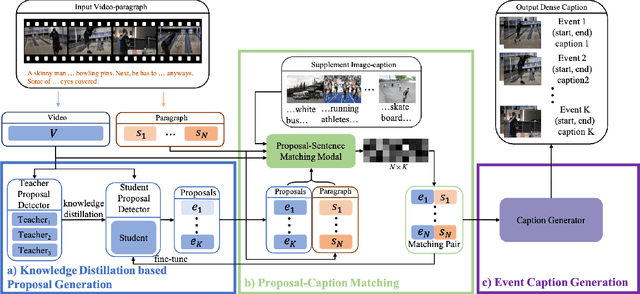
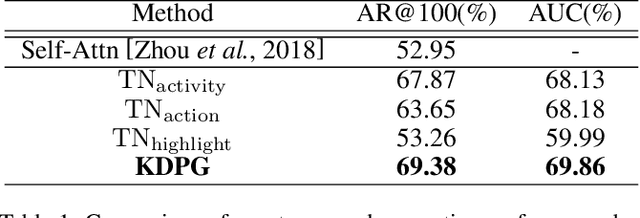
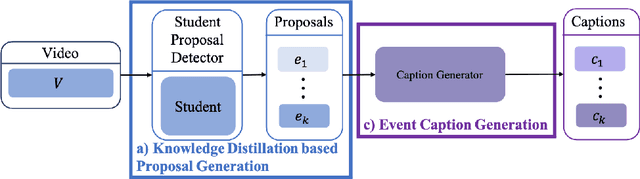
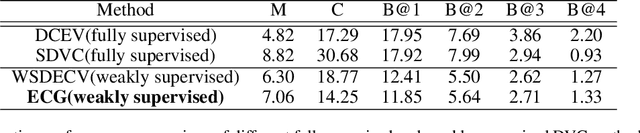
This paper proposes an approach to Dense Video Captioning (DVC) without pairwise event-sentence annotation. First, we adopt the knowledge distilled from relevant and well solved tasks to generate high-quality event proposals. Then we incorporate contrastive loss and cycle-consistency loss typically applied to cross-modal retrieval tasks to build semantic matching between the proposals and sentences, which are eventually used to train the caption generation module. In addition, the parameters of matching module are initialized via pre-training based on annotated images to improve the matching performance. Extensive experiments on ActivityNet-Caption dataset reveal the significance of distillation-based event proposal generation and cross-modal retrieval-based semantic matching to weakly supervised DVC, and demonstrate the superiority of our method to existing state-of-the-art methods.
UNIMO: Towards Unified-Modal Understanding and Generation via Cross-Modal Contrastive Learning
Dec 31, 2020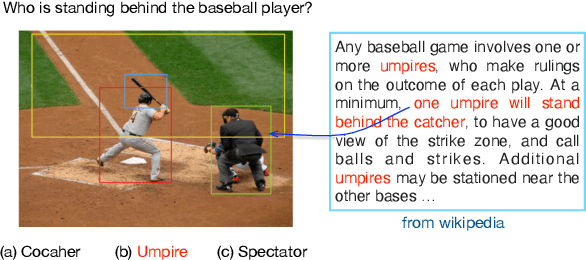

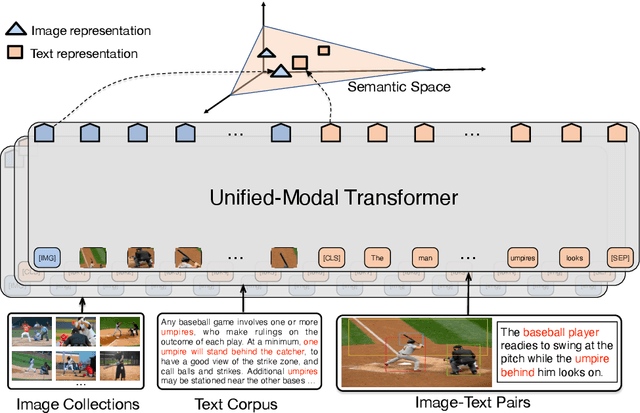
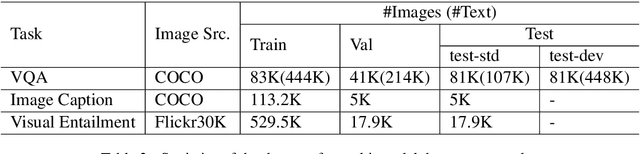
Existed pre-training methods either focus on single-modal tasks or multi-modal tasks, and cannot effectively adapt to each other. They can only utilize single-modal data (i.e. text or image) or limited multi-modal data (i.e. image-text pairs). In this work, we propose a unified-modal pre-training architecture, namely UNIMO, which can effectively adapt to both single-modal and multi-modal understanding and generation tasks. Large scale of free text corpus and image collections can be utilized to improve the capability of visual and textual understanding, and cross-modal contrastive learning (CMCL) is leveraged to align the textual and visual information into a unified semantic space over a corpus of image-text pairs. As the non-paired single-modal data is very rich, our model can utilize much larger scale of data to learn more generalizable representations. Moreover, the textual knowledge and visual knowledge can enhance each other in the unified semantic space. The experimental results show that UNIMO significantly improves the performance of several single-modal and multi-modal downstream tasks.