 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZeroGUI: Automating Online GUI Learning at Zero Human Cost
May 29, 2025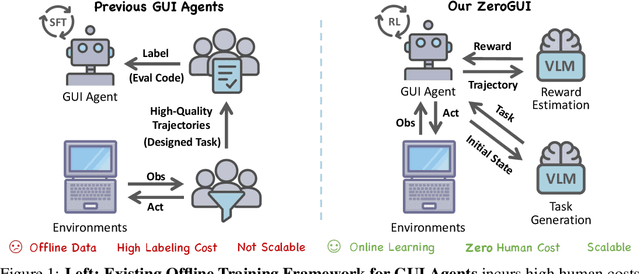
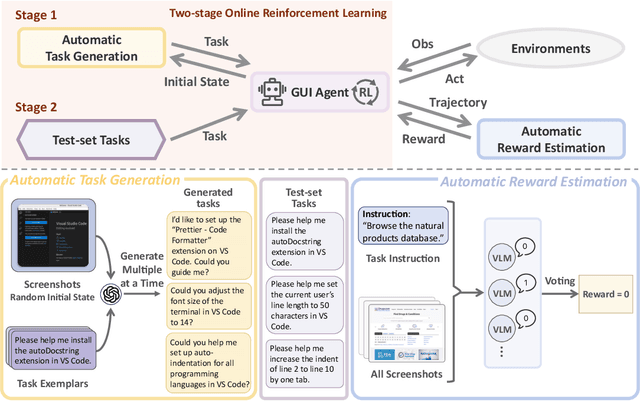


The rapid advancement of large Vision-Language Models (VLMs) has propelled the development of pure-vision-based GUI Agents, capable of perceiving and operating Graphical User Interfaces (GUI) to autonomously fulfill user instructions. However, existing approaches usually adopt an offline learning framework, which faces two core limitations: (1) heavy reliance on high-quality manual annotations for element grounding and action supervision, and (2) limited adaptability to dynamic and interactive environments. To address these limitations, we propose ZeroGUI, a scalable, online learning framework for automating GUI Agent training at Zero human cost. Specifically, ZeroGUI integrates (i) VLM-based automatic task generation to produce diverse training goals from the current environment state, (ii) VLM-based automatic reward estimation to assess task success without hand-crafted evaluation functions, and (iii) two-stage online reinforcement learning to continuously interact with and learn from GUI environments. Experiments on two advanced GUI Agents (UI-TARS and Aguvis) demonstrate that ZeroGUI significantly boosts performance across OSWorld and AndroidLab environments. The code is available at https://github.com/OpenGVLab/ZeroGUI.
Wav2Sem: Plug-and-Play Audio Semantic Decoupling for 3D Speech-Driven Facial Animation
May 29, 2025In 3D speech-driven facial animation generation, existing methods commonly employ pre-trained self-supervised audio models as encoders. However, due to the prevalence of phonetically similar syllables with distinct lip shapes in language, these near-homophone syllables tend to exhibit significant coupling in self-supervised audio feature spaces, leading to the averaging effect in subsequent lip motion generation. To address this issue, this paper proposes a plug-and-play semantic decorrelation module-Wav2Sem. This module extracts semantic features corresponding to the entire audio sequence, leveraging the added semantic information to decorrelate audio encodings within the feature space, thereby achieving more expressive audio features. Extensive experiments across multiple Speech-driven models indicate that the Wav2Sem module effectively decouples audio features, significantly alleviating the averaging effect of phonetically similar syllables in lip shape generation, thereby enhancing the precision and naturalness of facial animations. Our source code is available at https://github.com/wslh852/Wav2Sem.git.
SDPO: Importance-Sampled Direct Preference Optimization for Stable Diffusion Training
May 28, 2025



Preference learning has become a central technique for aligning generative models with human expectations. Recently, it has been extended to diffusion models through methods like Direct Preference Optimization (DPO). However, existing approaches such as Diffusion-DPO suffer from two key challenges: timestep-dependent instability, caused by a mismatch between the reverse and forward diffusion processes and by high gradient variance in early noisy timesteps, and off-policy bias arising from the mismatch between optimization and data collection policies. We begin by analyzing the reverse diffusion trajectory and observe that instability primarily occurs at early timesteps with low importance weights. To address these issues, we first propose DPO-C\&M, a practical strategy that improves stability by clipping and masking uninformative timesteps while partially mitigating off-policy bias. Building on this, we introduce SDPO (Importance-Sampled Direct Preference Optimization), a principled framework that incorporates importance sampling into the objective to fully correct for off-policy bias and emphasize informative updates during the diffusion process. Experiments on CogVideoX-2B, CogVideoX-5B, and Wan2.1-1.3B demonstrate that both methods outperform standard Diffusion-DPO, with SDPO achieving superior VBench scores, human preference alignment, and training robustness. These results highlight the importance of timestep-aware, distribution-corrected optimization in diffusion-based preference learning.
Beyond Chemical QA: Evaluating LLM's Chemical Reasoning with Modular Chemical Operations
May 27, 2025While large language models (LLMs) with Chain-of-Thought (CoT) reasoning excel in mathematics and coding, their potential for systematic reasoning in chemistry, a domain demanding rigorous structural analysis for real-world tasks like drug design and reaction engineering, remains untapped. Current benchmarks focus on simple knowledge retrieval, neglecting step-by-step reasoning required for complex tasks such as molecular optimization and reaction prediction. To address this, we introduce ChemCoTBench, a reasoning framework that bridges molecular structure understanding with arithmetic-inspired operations, including addition, deletion, and substitution, to formalize chemical problem-solving into transparent, step-by-step workflows. By treating molecular transformations as modular "chemical operations", the framework enables slow-thinking reasoning, mirroring the logic of mathematical proofs while grounding solutions in real-world chemical constraints. We evaluate models on two high-impact tasks: Molecular Property Optimization and Chemical Reaction Prediction. These tasks mirror real-world challenges while providing structured evaluability. By providing annotated datasets, a reasoning taxonomy, and baseline evaluations, ChemCoTBench bridges the gap between abstract reasoning methods and practical chemical discovery, establishing a foundation for advancing LLMs as tools for AI-driven scientific innovation.
Rethinking Text-based Protein Understanding: Retrieval or LLM?
May 26, 2025In recent years, protein-text models have gained significant attention for their potential in protein generation and understanding. Current approaches focus on integrating protein-related knowledge into large language models through continued pretraining and multi-modal alignment, enabling simultaneous comprehension of textual descriptions and protein sequences. Through a thorough analysis of existing model architectures and text-based protein understanding benchmarks, we identify significant data leakage issues present in current benchmarks. Moreover, conventional metrics derived from natural language processing fail to accurately assess the model's performance in this domain. To address these limitations, we reorganize existing datasets and introduce a novel evaluation framework based on biological entities. Motivated by our observation, we propose a retrieval-enhanced method, which significantly outperforms fine-tuned LLMs for protein-to-text generation and shows accuracy and efficiency in training-free scenarios. Our code and data can be seen at https://github.com/IDEA-XL/RAPM.
The Avengers: A Simple Recipe for Uniting Smaller Language Models to Challenge Proprietary Giants
May 26, 2025



As proprietary giants increasingly dominate the race for ever-larger language models, a pressing question arises for the open-source community: can smaller models remain competitive across a broad range of tasks? In this paper, we present the Avengers--a simple recipe that effectively leverages the collective intelligence of open-source, smaller language models. Our framework is built upon four lightweight operations: (i) embedding: encode queries using a text embedding model; (ii) clustering: group queries based on their semantic similarity; (iii) scoring: scores each model's performance within each cluster; and (iv) voting: improve outputs via repeated sampling and voting. At inference time, each query is embedded and assigned to its nearest cluster. The top-performing model(s) within that cluster are selected to generate the response using the Self-Consistency or its multi-model variant. Remarkably, with 10 open-source models (~7B parameters each), the Avengers collectively outperforms GPT-4.1 on 10 out of 15 datasets (spanning mathematics, code, logic, knowledge, and affective tasks). In particular, it surpasses GPT-4.1 on mathematics tasks by 18.21% and on code tasks by 7.46%. Furthermore, the Avengers delivers superior out-of-distribution generalization, and remains robust across various embedding models, clustering algorithms, ensemble strategies, and values of its sole parameter--the number of clusters. We have open-sourced the code on GitHub: https://github.com/ZhangYiqun018/Avengers
Self-Critique Guided Iterative Reasoning for Multi-hop Question Answering
May 25, 2025Although large language models (LLMs) have demonstrated remarkable reasoning capabilities, they still face challenges in knowledge-intensive multi-hop reasoning. Recent work explores iterative retrieval to address complex problems. However, the lack of intermediate guidance often results in inaccurate retrieval and flawed intermediate reasoning, leading to incorrect reasoning. To address these, we propose Self-Critique Guided Iterative Reasoning (SiGIR), which uses self-critique feedback to guide the iterative reasoning process. Specifically, through end-to-end training, we enable the model to iteratively address complex problems via question decomposition. Additionally, the model is able to self-evaluate its intermediate reasoning steps. During iterative reasoning, the model engages in branching exploration and employs self-evaluation to guide the selection of promising reasoning trajectories. Extensive experiments on three multi-hop reasoning datasets demonstrate the effectiveness of our proposed method, surpassing the previous SOTA by $8.6\%$. Furthermore, our thorough analysis offers insights for future research. Our code, data, and models are available at Github: https://github.com/zchuz/SiGIR-MHQA.
Learning Adaptive and Temporally Causal Video Tokenization in a 1D Latent Space
May 22, 2025We propose AdapTok, an adaptive temporal causal video tokenizer that can flexibly allocate tokens for different frames based on video content. AdapTok is equipped with a block-wise masking strategy that randomly drops tail tokens of each block during training, and a block causal scorer to predict the reconstruction quality of video frames using different numbers of tokens. During inference, an adaptive token allocation strategy based on integer linear programming is further proposed to adjust token usage given predicted scores. Such design allows for sample-wise, content-aware, and temporally dynamic token allocation under a controllable overall budget. Extensive experiments for video reconstruction and generation on UCF-101 and Kinetics-600 demonstrate the effectiveness of our approach. Without additional image data, AdapTok consistently improves reconstruction quality and generation performance under different token budgets, allowing for more scalable and token-efficient generative video modeling.
When to Continue Thinking: Adaptive Thinking Mode Switching for Efficient Reasoning
May 21, 2025



Large reasoning models (LRMs) achieve remarkable performance via long reasoning chains, but often incur excessive computational overhead due to redundant reasoning, especially on simple tasks. In this work, we systematically quantify the upper bounds of LRMs under both Long-Thinking and No-Thinking modes, and uncover the phenomenon of "Internal Self-Recovery Mechanism" where models implicitly supplement reasoning during answer generation. Building on this insight, we propose Adaptive Self-Recovery Reasoning (ASRR), a framework that suppresses unnecessary reasoning and enables implicit recovery. By introducing accuracy-aware length reward regulation, ASRR adaptively allocates reasoning effort according to problem difficulty, achieving high efficiency with negligible performance sacrifice. Experiments across multiple benchmarks and models show that, compared with GRPO, ASRR reduces reasoning budget by up to 32.5% (1.5B) and 25.7% (7B) with minimal accuracy loss (1.2% and 0.6% pass@1), and significantly boosts harmless rates on safety benchmarks (up to +21.7%). Our results highlight the potential of ASRR for enabling efficient, adaptive, and safer reasoning in LRMs.
CAD: A General Multimodal Framework for Video Deepfake Detection via Cross-Modal Alignment and Distillation
May 21, 2025The rapid emergence of multimodal deepfakes (visual and auditory content are manipulated in concert) undermines the reliability of existing detectors that rely solely on modality-specific artifacts or cross-modal inconsistencies. In this work, we first demonstrate that modality-specific forensic traces (e.g., face-swap artifacts or spectral distortions) and modality-shared semantic misalignments (e.g., lip-speech asynchrony) offer complementary evidence, and that neglecting either aspect limits detection performance. Existing approaches either naively fuse modality-specific features without reconciling their conflicting characteristics or focus predominantly on semantic misalignment at the expense of modality-specific fine-grained artifact cues. To address these shortcomings, we propose a general multimodal framework for video deepfake detection via Cross-Modal Alignment and Distillation (CAD). CAD comprises two core components: 1) Cross-modal alignment that identifies inconsistencies in high-level semantic synchronization (e.g., lip-speech mismatches); 2) Cross-modal distillation that mitigates feature conflicts during fusion while preserving modality-specific forensic traces (e.g., spectral distortions in synthetic audio). Extensive experiments on both multimodal and unimodal (e.g., image-only/video-only)deepfake benchmarks demonstrate that CAD significantly outperforms previous methods, validating the necessity of harmonious integration of multimodal complementary information.