 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoStream: Composing Simple Behaviors for Generalizable Complex Manipulation
Jun 24, 2026Long-horizon, contact-rich complex manipulation tasks, such as seating a GPU into a PCIe slot, demand both millimeter high precision and out-of-the-box generalization to new tasks. Existing paradigms struggle to satisfy both: classical pipelines use brittle, task-specific interfaces to achieve high-precision control but require costly pipeline redesigns to adapt to new tasks, whereas monolithic end-to-end policies provide better generalization but lack high precision on complex, out-of-distribution tasks unless retrained with new data. Both paradigms share an implicit assumption: once a manipulation capability is acquired, it must be deployed as a rigid pipeline or monolithic whole, rather than being freely decomposed and recomposed. In this paper, we show that complex manipulation capabilities can emerge naturally from the composition of simple, independent behaviors. Rather than deploying a monolithic policy or a rigid pipeline, we propose \ourshort, a framework orchestrating foundation models and diverse sensing modalities into multiple composable core behaviors: a semantic behavior extracting spatial constraints via foundation models; a predictive behavior forecasting trajectories by tracking keypoints in imagined videos; and a reactive behavior providing high-frequency tactile and force corrections. On a shared $SE(3)$ interface, these outputs compose by right-multiplication into a single pose command at each control step, executed by a compliant controller. We demonstrate \ourshort on 8 real-world tasks spanning everyday manipulation and precision assembly, with the strongest gains in contact-rich assembly and object transfer, and show robust recovery from manual perturbations during execution. {Website:} https://costream-simple.github.io
OAT: Ordered Action Tokenization
Feb 04, 2026Autoregressive policies offer a compelling foundation for scalable robot learning by enabling discrete abstraction, token-level reasoning, and flexible inference. However, applying autoregressive modeling to continuous robot actions requires an effective action tokenization scheme. Existing approaches either rely on analytical discretization methods that produce prohibitively long token sequences, or learned latent tokenizers that lack structure, limiting their compatibility with next-token prediction. In this work, we identify three desiderata for action tokenization - high compression, total decodability, and a left-to-right causally ordered token space - and introduce Ordered Action Tokenization (OAT), a learned action tokenizer that satisfies all three. OAT discretizes action chunks into an ordered sequence of tokens using transformer with registers, finite scalar quantization, and ordering-inducing training mechanisms. The resulting token space aligns naturally with autoregressive generation and enables prefix-based detokenization, yielding an anytime trade-off between inference cost and action fidelity. Across more than 20 tasks spanning four simulation benchmarks and real-world settings, autoregressive policies equipped with OAT consistently outperform prior tokenization schemes and diffusion-based baselines, while offering significantly greater flexibility at inference time.
RoboGround: Robotic Manipulation with Grounded Vision-Language Priors
Apr 30, 2025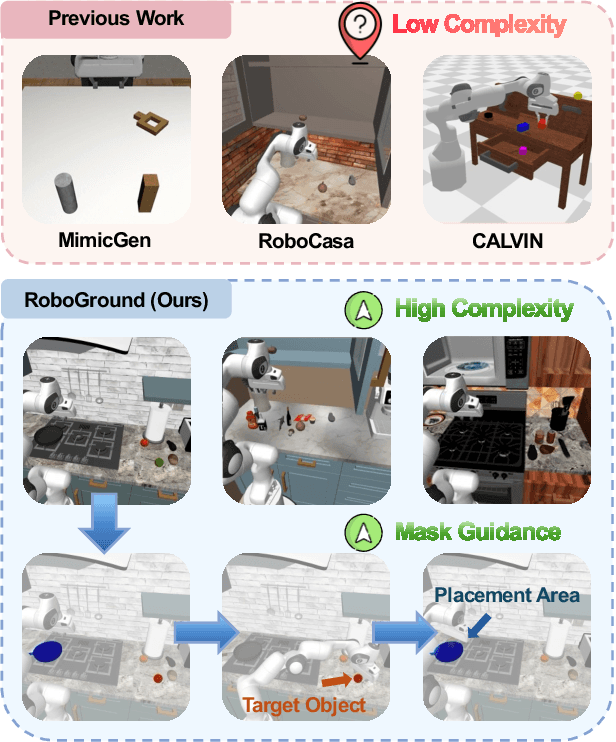

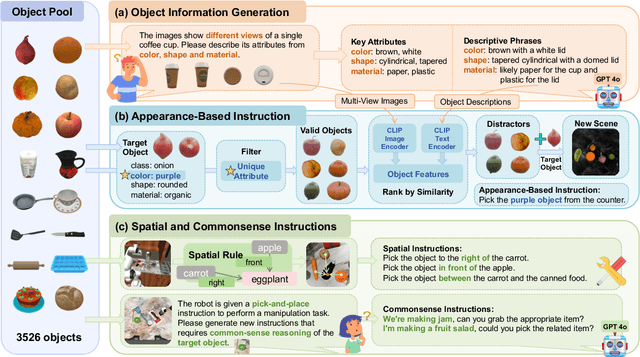
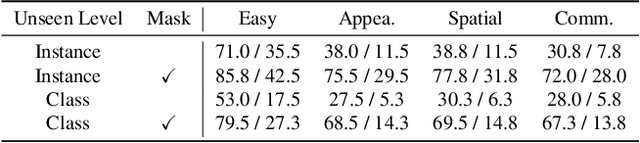
Recent advancements in robotic manipulation have highlighted the potential of intermediate representations for improving policy generalization. In this work, we explore grounding masks as an effective intermediate representation, balancing two key advantages: (1) effective spatial guidance that specifies target objects and placement areas while also conveying information about object shape and size, and (2) broad generalization potential driven by large-scale vision-language models pretrained on diverse grounding datasets. We introduce RoboGround, a grounding-aware robotic manipulation system that leverages grounding masks as an intermediate representation to guide policy networks in object manipulation tasks. To further explore and enhance generalization, we propose an automated pipeline for generating large-scale, simulated data with a diverse set of objects and instructions. Extensive experiments show the value of our dataset and the effectiveness of grounding masks as intermediate guidance, significantly enhancing the generalization abilities of robot policies.
Re$^3$Sim: Generating High-Fidelity Simulation Data via 3D-Photorealistic Real-to-Sim for Robotic Manipulation
Feb 12, 2025Real-world data collection for robotics is costly and resource-intensive, requiring skilled operators and expensive hardware. Simulations offer a scalable alternative but often fail to achieve sim-to-real generalization due to geometric and visual gaps. To address these challenges, we propose a 3D-photorealistic real-to-sim system, namely, RE$^3$SIM, addressing geometric and visual sim-to-real gaps. RE$^3$SIM employs advanced 3D reconstruction and neural rendering techniques to faithfully recreate real-world scenarios, enabling real-time rendering of simulated cross-view cameras within a physics-based simulator. By utilizing privileged information to collect expert demonstrations efficiently in simulation, and train robot policies with imitation learning, we validate the effectiveness of the real-to-sim-to-real pipeline across various manipulation task scenarios. Notably, with only simulated data, we can achieve zero-shot sim-to-real transfer with an average success rate exceeding 58%. To push the limit of real-to-sim, we further generate a large-scale simulation dataset, demonstrating how a robust policy can be built from simulation data that generalizes across various objects. Codes and demos are available at: http://xshenhan.github.io/Re3Sim/.
Long-Horizon Rollout via Dynamics Diffusion for Offline Reinforcement Learning
Jun 09, 2024



With the great success of diffusion models (DMs) in generating realistic synthetic vision data, many researchers have investigated their potential in decision-making and control. Most of these works utilized DMs to sample directly from the trajectory space, where DMs can be viewed as a combination of dynamics models and policies. In this work, we explore how to decouple DMs' ability as dynamics models in fully offline settings, allowing the learning policy to roll out trajectories. As DMs learn the data distribution from the dataset, their intrinsic policy is actually the behavior policy induced from the dataset, which results in a mismatch between the behavior policy and the learning policy. We propose Dynamics Diffusion, short as DyDiff, which can inject information from the learning policy to DMs iteratively. DyDiff ensures long-horizon rollout accuracy while maintaining policy consistency and can be easily deployed on model-free algorithms. We provide theoretical analysis to show the advantage of DMs on long-horizon rollout over models and demonstrate the effectiveness of DyDiff in the context of offline reinforcement learning, where the rollout dataset is provided but no online environment for interaction. Our code is at https://github.com/FineArtz/DyDiff.
Diffusion-based Dynamics Models for Long-Horizon Rollout in Offline Reinforcement Learning
May 29, 2024With the great success of diffusion models (DMs) in generating realistic synthetic vision data, many researchers have investigated their potential in decision-making and control. Most of these works utilized DMs to sample directly from the trajectory space, where DMs can be viewed as a combination of dynamics models and policies. In this work, we explore how to decouple DMs' ability as dynamics models in fully offline settings, allowing the learning policy to roll out trajectories. As DMs learn the data distribution from the dataset, their intrinsic policy is actually the behavior policy induced from the dataset, which results in a mismatch between the behavior policy and the learning policy. We propose Dynamics Diffusion, short as DyDiff, which can inject information from the learning policy to DMs iteratively. DyDiff ensures long-horizon rollout accuracy while maintaining policy consistency and can be easily deployed on model-free algorithms. We provide theoretical analysis to show the advantage of DMs on long-horizon rollout over models and demonstrate the effectiveness of DyDiff in the context of offline reinforcement learning, where the rollout dataset is provided but no online environment for interaction. Our code is at https://github.com/FineArtz/DyDiff.