 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$R^3$: 3D Reconstruction via Relative Regression
May 26, 2026Recent feed-forward geometry foundation models have demonstrated impressive generalization by recovering depth and poses in a single forward pass. However, these models are typically constrained by a global coordinate frame assumption. This dependency becomes a significant bottleneck for long-context and streaming reconstruction, as it forces the network to maintain an arbitrary temporal origin and handle translation magnitudes that grow unbounded over time. Our solution, which we call $R^3$, employs relative regression. We employ a lightweight MLP to predict confidence-weighted relative constraints. These confidences serve as a unified anchor: weighting losses during training and guiding pose aggregation during inference. $R^3$ supports both full-context offline reconstruction and causal, bounded-memory streaming. Our evaluation in both offline and streaming settings validates the effectiveness of our relative mechanism. Project page: https://kevinxu02.github.io/r3-site
Towards Anatomically Plausible Human Image Generation via Synthetic Localized Preferences
May 25, 2026Large-scale text-to-image foundation models have achieved remarkable visual realism, yet generating human images with correct anatomical structures remains challenging. Existing approaches enforce anatomical constraints through part-specific modules or localized loss weighting during supervised fine-tuning on high-quality human photos, but such datasets are limited and often provide ambiguous optimization signals due to confounding factors such as lighting, pose, and background. Preference-based alignment offers an alternative, but standard Direct Preference Optimization (DPO) treats all pixels equally and therefore fails to exploit the localized nature of anatomical artifacts. To address this, we propose the framework of Alignment via Synthetic Anatomical Preference (ASAP), which constructs controlled preference pairs through a localized degradation mechanism applied to high-fidelity human images. This mechanism performs a controlled experiment on images by introducing explicit anatomical errors in targeted regions while preserving the remaining content. With this mechanism, we create the Human Anatomical Preference (HAP) dataset with over 10K curated pairs for effective anatomical alignment of text-to-image human image generative models. To better leverage the locality of these controlled preference pairs, we introduce a localized and margin-bounded variant of DPO that prioritizes optimization in targeted anatomical regions while enforcing a finite preference margin to prevent over-optimization and preserve global semantics. We further introduce HAF-Bench, a benchmark for systematic evaluation of anatomical fidelity. Extensive experiments demonstrate that ASAP consistently reduces anatomical errors across multiple foundation models while maintaining overall image quality.
OmniFit: Multi-modal 3D Body Fitting via Scale-agnostic Dense Landmark Prediction
Apr 23, 2026Fitting an underlying body model to 3D clothed human assets has been extensively studied, yet most approaches focus on either single-modal inputs such as point clouds or multi-view images alone, often requiring a known metric scale. This constraint is frequently impractical, especially for AI-generated assets where scale distortion is common. We propose OmniFit, a method that can seamlessly handle diverse multi-modal inputs, including full scans, partial depth observations, and image captures, while remaining scale-agnostic for both real and synthetic assets. Our key innovation is a simple yet effective conditional transformer decoder that directly maps surface points to dense body landmarks, which are then used for SMPL-X parameter fitting. In addition, an optional plug-and-play image adapter incorporates visual cues to compensate for missing geometric information. We further introduce a dedicated scale predictor that rescales subjects to canonical body proportions. OmniFit substantially outperforms state-of-the-art methods by 57.1 to 80.9 percent across daily and loose clothing scenarios. To the best of our knowledge, it is the first body fitting method to surpass multi-view optimization baselines and the first to achieve millimeter-level accuracy on the CAPE and 4D-DRESS benchmarks.
GaussiAnimate: Reconstruct and Rig Animatable Categories with Level of Dynamics
Apr 09, 2026Free-form bones, that conform closely to the surface, can effectively capture non-rigid deformations, but lack a kinematic structure necessary for intuitive control. Thus, we propose a Scaffold-Skin Rigging System, termed "Skelebones", with three key steps: (1) Bones: compress temporally-consistent deformable Gaussians into free-form bones, approximating non-rigid surface deformations; (2) Skeleton: extract a Mean Curvature Skeleton from canonical Gaussians and refine it temporally, ensuring a category-agnostic, motion-adaptive, and topology-correct kinematic structure; (3) Binding: bind the skeleton and bones via non-parametric partwise motion matching (PartMM), synthesizing novel bone motions by matching, retrieving, and blending existing ones. Collectively, these three steps enable us to compress the Level of Dynamics of 4D shapes into compact skelebones that are both controllable and expressive. We validate our approach on both synthetic and real-world datasets, achieving significant improvements in reanimation performance across unseen poses-with 17.3% PSNR gains over Linear Blend Skinning (LBS) and 21.7% over Bag-of-Bones (BoB)-while maintaining excellent reconstruction fidelity, particularly for characters exhibiting complex non-rigid surface dynamics. Our Partwise Motion Matching algorithm demonstrates strong generalization to both Gaussian and mesh representations, especially under low-data regime (~1000 frames), achieving 48.4% RMSE improvement over robust LBS and outperforming GRU- and MLP-based learning methods by >20%. Code will be made publicly available for research purposes at cookmaker.cn/gaussianimate.
ETCH-X: Robustify Expressive Body Fitting to Clothed Humans with Composable Datasets
Apr 09, 2026Human body fitting, which aligns parametric body models such as SMPL to raw 3D point clouds of clothed humans, serves as a crucial first step for downstream tasks like animation and texturing. An effective fitting method should be both locally expressive-capturing fine details such as hands and facial features-and globally robust to handle real-world challenges, including clothing dynamics, pose variations, and noisy or partial inputs. Existing approaches typically excel in only one aspect, lacking an all-in-one solution.We upgrade ETCH to ETCH-X, which leverages a tightness-aware fitting paradigm to filter out clothing dynamics ("undress"), extends expressiveness with SMPL-X, and replaces explicit sparse markers (which are highly sensitive to partial data) with implicit dense correspondences ("dense fit") for more robust and fine-grained body fitting. Our disentangled "undress" and "dense fit" modular stages enable separate and scalable training on composable data sources, including diverse simulated garments (CLOTH3D), large-scale full-body motions (AMASS), and fine-grained hand gestures (InterHand2.6M), improving outfit generalization and pose robustness of both bodies and hands. Our approach achieves robust and expressive fitting across diverse clothing, poses, and levels of input completeness, delivering a substantial performance improvement over ETCH on both: 1) seen data, such as 4D-Dress (MPJPE-All, 33.0% ) and CAPE (V2V-Hands, 35.8% ), and 2) unseen data, such as BEDLAM2.0 (MPJPE-All, 80.8% ; V2V-All, 80.5% ). Code and models will be released at https://xiaobenli00.github.io/ETCH-X/.
TTT3R: 3D Reconstruction as Test-Time Training
Sep 30, 2025Modern Recurrent Neural Networks have become a competitive architecture for 3D reconstruction due to their linear-time complexity. However, their performance degrades significantly when applied beyond the training context length, revealing limited length generalization. In this work, we revisit the 3D reconstruction foundation models from a Test-Time Training perspective, framing their designs as an online learning problem. Building on this perspective, we leverage the alignment confidence between the memory state and incoming observations to derive a closed-form learning rate for memory updates, to balance between retaining historical information and adapting to new observations. This training-free intervention, termed TTT3R, substantially improves length generalization, achieving a $2\times$ improvement in global pose estimation over baselines, while operating at 20 FPS with just 6 GB of GPU memory to process thousands of images. Code available in https://rover-xingyu.github.io/TTT3R
SOAP: Style-Omniscient Animatable Portraits
May 08, 2025
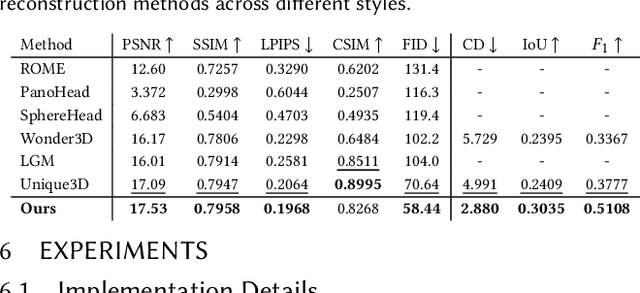
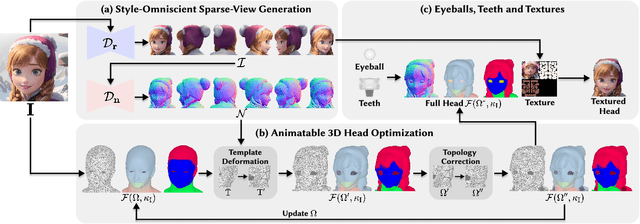
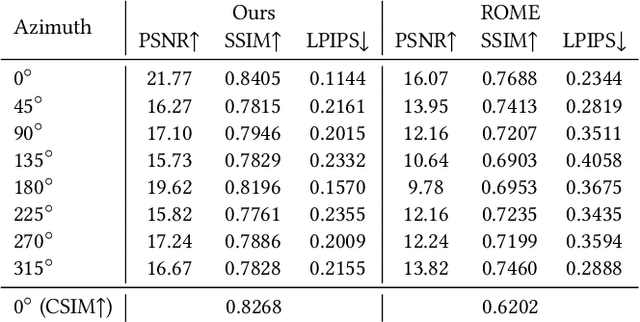
Creating animatable 3D avatars from a single image remains challenging due to style limitations (realistic, cartoon, anime) and difficulties in handling accessories or hairstyles. While 3D diffusion models advance single-view reconstruction for general objects, outputs often lack animation controls or suffer from artifacts because of the domain gap. We propose SOAP, a style-omniscient framework to generate rigged, topology-consistent avatars from any portrait. Our method leverages a multiview diffusion model trained on 24K 3D heads with multiple styles and an adaptive optimization pipeline to deform the FLAME mesh while maintaining topology and rigging via differentiable rendering. The resulting textured avatars support FACS-based animation, integrate with eyeballs and teeth, and preserve details like braided hair or accessories. Extensive experiments demonstrate the superiority of our method over state-of-the-art techniques for both single-view head modeling and diffusion-based generation of Image-to-3D. Our code and data are publicly available for research purposes at https://github.com/TingtingLiao/soap.
Easi3R: Estimating Disentangled Motion from DUSt3R Without Training
Mar 31, 2025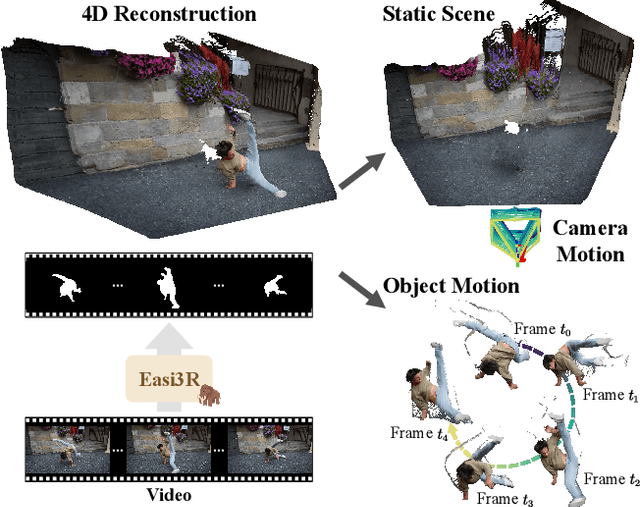



Recent advances in DUSt3R have enabled robust estimation of dense point clouds and camera parameters of static scenes, leveraging Transformer network architectures and direct supervision on large-scale 3D datasets. In contrast, the limited scale and diversity of available 4D datasets present a major bottleneck for training a highly generalizable 4D model. This constraint has driven conventional 4D methods to fine-tune 3D models on scalable dynamic video data with additional geometric priors such as optical flow and depths. In this work, we take an opposite path and introduce Easi3R, a simple yet efficient training-free method for 4D reconstruction. Our approach applies attention adaptation during inference, eliminating the need for from-scratch pre-training or network fine-tuning. We find that the attention layers in DUSt3R inherently encode rich information about camera and object motion. By carefully disentangling these attention maps, we achieve accurate dynamic region segmentation, camera pose estimation, and 4D dense point map reconstruction. Extensive experiments on real-world dynamic videos demonstrate that our lightweight attention adaptation significantly outperforms previous state-of-the-art methods that are trained or finetuned on extensive dynamic datasets. Our code is publicly available for research purpose at https://easi3r.github.io/
ETCH: Generalizing Body Fitting to Clothed Humans via Equivariant Tightness
Mar 13, 2025Fitting a body to a 3D clothed human point cloud is a common yet challenging task. Traditional optimization-based approaches use multi-stage pipelines that are sensitive to pose initialization, while recent learning-based methods often struggle with generalization across diverse poses and garment types. We propose Equivariant Tightness Fitting for Clothed Humans, or ETCH, a novel pipeline that estimates cloth-to-body surface mapping through locally approximate SE(3) equivariance, encoding tightness as displacement vectors from the cloth surface to the underlying body. Following this mapping, pose-invariant body features regress sparse body markers, simplifying clothed human fitting into an inner-body marker fitting task. Extensive experiments on CAPE and 4D-Dress show that ETCH significantly outperforms state-of-the-art methods -- both tightness-agnostic and tightness-aware -- in body fitting accuracy on loose clothing (16.7% ~ 69.5%) and shape accuracy (average 49.9%). Our equivariant tightness design can even reduce directional errors by (67.2% ~ 89.8%) in one-shot (or out-of-distribution) settings. Qualitative results demonstrate strong generalization of ETCH, regardless of challenging poses, unseen shapes, loose clothing, and non-rigid dynamics. We will release the code and models soon for research purposes at https://boqian-li.github.io/ETCH/.
ChatGarment: Garment Estimation, Generation and Editing via Large Language Models
Dec 23, 2024We introduce ChatGarment, a novel approach that leverages large vision-language models (VLMs) to automate the estimation, generation, and editing of 3D garments from images or text descriptions. Unlike previous methods that struggle in real-world scenarios or lack interactive editing capabilities, ChatGarment can estimate sewing patterns from in-the-wild images or sketches, generate them from text descriptions, and edit garments based on user instructions, all within an interactive dialogue. These sewing patterns can then be draped into 3D garments, which are easily animatable and simulatable. This is achieved by finetuning a VLM to directly generate a JSON file that includes both textual descriptions of garment types and styles, as well as continuous numerical attributes. This JSON file is then used to create sewing patterns through a programming parametric model. To support this, we refine the existing programming model, GarmentCode, by expanding its garment type coverage and simplifying its structure for efficient VLM fine-tuning. Additionally, we construct a large-scale dataset of image-to-sewing-pattern and text-to-sewing-pattern pairs through an automated data pipeline. Extensive evaluations demonstrate ChatGarment's ability to accurately reconstruct, generate, and edit garments from multimodal inputs, highlighting its potential to revolutionize workflows in fashion and gaming applications. Code and data will be available at https://chatgarment.github.io/.