 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHairOrbit: Multi-view Aware 3D Hair Modeling from Single Portraits
Apr 03, 2026Reconstructing strand-level 3D hair from a single-view image is highly challenging, especially when preserving consistent and realistic attributes in unseen regions. Existing methods rely on limited frontal-view cues and small-scale/style-restricted synthetic data, often failing to produce satisfactory results in invisible regions. In this work, we propose a novel framework that leverages the strong 3D priors of video generation models to transform single-view hair reconstruction into a calibrated multi-view reconstruction task. To balance reconstruction quality and efficiency for the reformulated multi-view task, we further introduce a neural orientation extractor trained on sparse real-image annotations for better full-view orientation estimation. In addition, we design a two-stage strand-growing algorithm based on a hybrid implicit field to synthesize the 3D strand curves with fine-grained details at a relatively fast speed. Extensive experiments demonstrate that our method achieves state-of-the-art performance on single-view 3D hair strand reconstruction on a diverse range of hair portraits in both visible and invisible regions.
InverseDraping: Recovering Sewing Patterns from 3D Garment Surfaces via BoxMesh Bridging
Apr 03, 2026Recovering sewing patterns from draped 3D garments is a challenging problem in human digitization research. In contrast to the well-studied forward process of draping designed sewing patterns using mature physical simulation engines, the inverse process of recovering parametric 2D patterns from deformed garment geometry remains fundamentally ill-posed for existing methods. We propose a two-stage framework that centers on a structured intermediate representation, BoxMesh, which serves as the key to bridging the gap between 3D garment geometry and parametric sewing patterns. BoxMesh encodes both garment-level geometry and panel-level structure in 3D, while explicitly disentangling intrinsic panel geometry and stitching topology from draping-induced deformations. This representation imposes a physically grounded structure on the problem, significantly reducing ambiguity. In Stage I, a geometry-driven autoregressive model infers BoxMesh from the input 3D garment. In Stage II, a semantics-aware autoregressive model parses BoxMesh into parametric sewing patterns. We adopt autoregressive modeling to naturally handle the variable-length and structured nature of panel configurations and stitching relationships. This decomposition separates geometric inversion from structured pattern inference, leading to more accurate and robust recovery. Extensive experiments demonstrate that our method achieves state-of-the-art performance on the GarmentCodeData benchmark and generalizes effectively to real-world scans and single-view images.
SOAP: Style-Omniscient Animatable Portraits
May 08, 2025
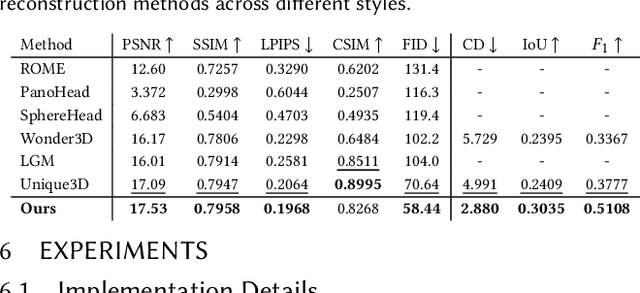
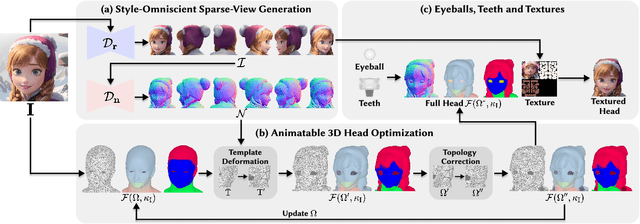
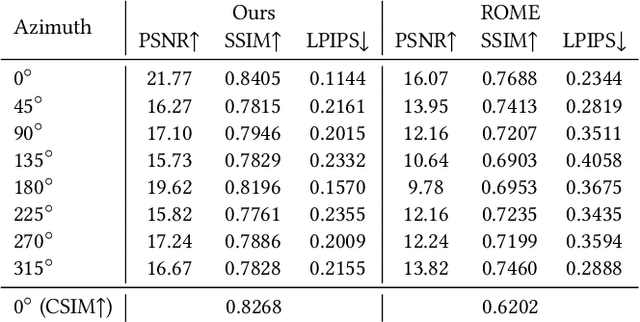
Creating animatable 3D avatars from a single image remains challenging due to style limitations (realistic, cartoon, anime) and difficulties in handling accessories or hairstyles. While 3D diffusion models advance single-view reconstruction for general objects, outputs often lack animation controls or suffer from artifacts because of the domain gap. We propose SOAP, a style-omniscient framework to generate rigged, topology-consistent avatars from any portrait. Our method leverages a multiview diffusion model trained on 24K 3D heads with multiple styles and an adaptive optimization pipeline to deform the FLAME mesh while maintaining topology and rigging via differentiable rendering. The resulting textured avatars support FACS-based animation, integrate with eyeballs and teeth, and preserve details like braided hair or accessories. Extensive experiments demonstrate the superiority of our method over state-of-the-art techniques for both single-view head modeling and diffusion-based generation of Image-to-3D. Our code and data are publicly available for research purposes at https://github.com/TingtingLiao/soap.
Towards Unified 3D Hair Reconstruction from Single-View Portraits
Sep 25, 2024



Single-view 3D hair reconstruction is challenging, due to the wide range of shape variations among diverse hairstyles. Current state-of-the-art methods are specialized in recovering un-braided 3D hairs and often take braided styles as their failure cases, because of the inherent difficulty to define priors for complex hairstyles, whether rule-based or data-based. We propose a novel strategy to enable single-view 3D reconstruction for a variety of hair types via a unified pipeline. To achieve this, we first collect a large-scale synthetic multi-view hair dataset SynMvHair with diverse 3D hair in both braided and un-braided styles, and learn two diffusion priors specialized on hair. Then we optimize 3D Gaussian-based hair from the priors with two specially designed modules, i.e. view-wise and pixel-wise Gaussian refinement. Our experiments demonstrate that reconstructing braided and un-braided 3D hair from single-view images via a unified approach is possible and our method achieves the state-of-the-art performance in recovering complex hairstyles. It is worth to mention that our method shows good generalization ability to real images, although it learns hair priors from synthetic data.
EMS: 3D Eyebrow Modeling from Single-view Images
Sep 22, 2023Eyebrows play a critical role in facial expression and appearance. Although the 3D digitization of faces is well explored, less attention has been drawn to 3D eyebrow modeling. In this work, we propose EMS, the first learning-based framework for single-view 3D eyebrow reconstruction. Following the methods of scalp hair reconstruction, we also represent the eyebrow as a set of fiber curves and convert the reconstruction to fibers growing problem. Three modules are then carefully designed: RootFinder firstly localizes the fiber root positions which indicates where to grow; OriPredictor predicts an orientation field in the 3D space to guide the growing of fibers; FiberEnder is designed to determine when to stop the growth of each fiber. Our OriPredictor is directly borrowing the method used in hair reconstruction. Considering the differences between hair and eyebrows, both RootFinder and FiberEnder are newly proposed. Specifically, to cope with the challenge that the root location is severely occluded, we formulate root localization as a density map estimation task. Given the predicted density map, a density-based clustering method is further used for finding the roots. For each fiber, the growth starts from the root point and moves step by step until the ending, where each step is defined as an oriented line with a constant length according to the predicted orientation field. To determine when to end, a pixel-aligned RNN architecture is designed to form a binary classifier, which outputs stop or not for each growing step. To support the training of all proposed networks, we build the first 3D synthetic eyebrow dataset that contains 400 high-quality eyebrow models manually created by artists. Extensive experiments have demonstrated the effectiveness of the proposed EMS pipeline on a variety of different eyebrow styles and lengths, ranging from short and sparse to long bushy eyebrows.