 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAME-2: Agile and Generalized Legged Locomotion via Attention-Based Neural Map Encoding
Jan 13, 2026Achieving agile and generalized legged locomotion across terrains requires tight integration of perception and control, especially under occlusions and sparse footholds. Existing methods have demonstrated agility on parkour courses but often rely on end-to-end sensorimotor models with limited generalization and interpretability. By contrast, methods targeting generalized locomotion typically exhibit limited agility and struggle with visual occlusions. We introduce AME-2, a unified reinforcement learning (RL) framework for agile and generalized locomotion that incorporates a novel attention-based map encoder in the control policy. This encoder extracts local and global mapping features and uses attention mechanisms to focus on salient regions, producing an interpretable and generalized embedding for RL-based control. We further propose a learning-based mapping pipeline that provides fast, uncertainty-aware terrain representations robust to noise and occlusions, serving as policy inputs. It uses neural networks to convert depth observations into local elevations with uncertainties, and fuses them with odometry. The pipeline also integrates with parallel simulation so that we can train controllers with online mapping, aiding sim-to-real transfer. We validate AME-2 with the proposed mapping pipeline on a quadruped and a biped robot, and the resulting controllers demonstrate strong agility and generalization to unseen terrains in simulation and in real-world experiments.
GeM-VG: Towards Generalized Multi-image Visual Grounding with Multimodal Large Language Models
Jan 08, 2026Multimodal Large Language Models (MLLMs) have demonstrated impressive progress in single-image grounding and general multi-image understanding. Recently, some methods begin to address multi-image grounding. However, they are constrained by single-target localization and limited types of practical tasks, due to the lack of unified modeling for generalized grounding tasks. Therefore, we propose GeM-VG, an MLLM capable of Generalized Multi-image Visual Grounding. To support this, we systematically categorize and organize existing multi-image grounding tasks according to their reliance of cross-image cues and reasoning, and introduce the MG-Data-240K dataset, addressing the limitations of existing datasets regarding target quantity and image relation. To tackle the challenges of robustly handling diverse multi-image grounding tasks, we further propose a hybrid reinforcement finetuning strategy that integrates chain-of-thought (CoT) reasoning and direct answering, considering their complementary strengths. This strategy adopts an R1-like algorithm guided by a carefully designed rule-based reward, effectively enhancing the model's overall perception and reasoning capabilities. Extensive experiments demonstrate the superior generalized grounding capabilities of our model. For multi-image grounding, it outperforms the previous leading MLLMs by 2.0% and 9.7% on MIG-Bench and MC-Bench, respectively. In single-image grounding, it achieves a 9.1% improvement over the base model on ODINW. Furthermore, our model retains strong capabilities in general multi-image understanding.
Feature-based Inversion of 2.5D Controlled Source Electromagnetic Data using Generative Priors
Jan 05, 2026In this study, we investigate feature-based 2.5D controlled source marine electromagnetic (mCSEM) data inversion using generative priors. Two-and-half dimensional modeling using finite difference method (FDM) is adopted to compute the response of horizontal electric dipole (HED) excitation. Rather than using a neural network to approximate the entire inverse mapping in a black-box manner, we adopt a plug-andplay strategy in which a variational autoencoder (VAE) is used solely to learn prior information on conductivity distributions. During the inversion process, the conductivity model is iteratively updated using the Gauss Newton method, while the model space is constrained by projections onto the learned VAE decoder. This framework preserves explicit control over data misfit and enables flexible adaptation to different survey configurations. Numerical and field experiments demonstrate that the proposed approach effectively incorporates prior information, improves reconstruction accuracy, and exhibits good generalization performance.
SAHA: Supervised Autonomous HArvester for selective forest thinning
Jan 03, 2026Forestry plays a vital role in our society, creating significant ecological, economic, and recreational value. Efficient forest management involves labor-intensive and complex operations. One essential task for maintaining forest health and productivity is selective thinning, which requires skilled operators to remove specific trees to create optimal growing conditions for the remaining ones. In this work, we present a solution based on a small-scale robotic harvester (SAHA) designed for executing this task with supervised autonomy. We build on a 4.5-ton harvester platform and implement key hardware modifications for perception and automatic control. We implement learning- and model-based approaches for precise control of hydraulic actuators, accurate navigation through cluttered environments, robust state estimation, and reliable semantic estimation of terrain traversability. Integrating state-of-the-art techniques in perception, planning, and control, our robotic harvester can autonomously navigate forest environments and reach targeted trees for selective thinning. We present experimental results from extensive field trials over kilometer-long autonomous missions in northern European forests, demonstrating the harvester's ability to operate in real forests. We analyze the performance and provide the lessons learned for advancing robotic forest management.
IRPO: Scaling the Bradley-Terry Model via Reinforcement Learning
Jan 02, 2026Generative Reward Models (GRMs) have attracted considerable research interest in reward modeling due to their interpretability, inference-time scalability, and potential for refinement through reinforcement learning (RL). However, widely used pairwise GRMs create a computational bottleneck when integrated with RL algorithms such as Group Relative Policy Optimization (GRPO). This bottleneck arises from two factors: (i) the O(n^2) time complexity of pairwise comparisons required to obtain relative scores, and (ii) the computational overhead of repeated sampling or additional chain-of-thought (CoT) reasoning to improve performance. To address the first factor, we propose Intergroup Relative Preference Optimization (IRPO), a novel RL framework that incorporates the well-established Bradley-Terry model into GRPO. By generating a pointwise score for each response, IRPO enables efficient evaluation of arbitrarily many candidates during RL training while preserving interpretability and fine-grained reward signals. Experimental results demonstrate that IRPO achieves state-of-the-art (SOTA) performance among pointwise GRMs across multiple benchmarks, with performance comparable to that of current leading pairwise GRMs. Furthermore, we show that IRPO significantly outperforms pairwise GRMs in post-training evaluations.
OpenOneRec Technical Report
Dec 31, 2025While the OneRec series has successfully unified the fragmented recommendation pipeline into an end-to-end generative framework, a significant gap remains between recommendation systems and general intelligence. Constrained by isolated data, they operate as domain specialists-proficient in pattern matching but lacking world knowledge, reasoning capabilities, and instruction following. This limitation is further compounded by the lack of a holistic benchmark to evaluate such integrated capabilities. To address this, our contributions are: 1) RecIF Bench & Open Data: We propose RecIF-Bench, a holistic benchmark covering 8 diverse tasks that thoroughly evaluate capabilities from fundamental prediction to complex reasoning. Concurrently, we release a massive training dataset comprising 96 million interactions from 160,000 users to facilitate reproducible research. 2) Framework & Scaling: To ensure full reproducibility, we open-source our comprehensive training pipeline, encompassing data processing, co-pretraining, and post-training. Leveraging this framework, we demonstrate that recommendation capabilities can scale predictably while mitigating catastrophic forgetting of general knowledge. 3) OneRec-Foundation: We release OneRec Foundation (1.7B and 8B), a family of models establishing new state-of-the-art (SOTA) results across all tasks in RecIF-Bench. Furthermore, when transferred to the Amazon benchmark, our models surpass the strongest baselines with an average 26.8% improvement in Recall@10 across 10 diverse datasets (Figure 1). This work marks a step towards building truly intelligent recommender systems. Nonetheless, realizing this vision presents significant technical and theoretical challenges, highlighting the need for broader research engagement in this promising direction.
Vibe Reasoning: Eliciting Frontier AI Mathematical Capabilities -- A Case Study on IMO 2025 Problem 6
Dec 22, 2025We introduce Vibe Reasoning, a human-AI collaborative paradigm for solving complex mathematical problems. Our key insight is that frontier AI models already possess the knowledge required to solve challenging problems -- they simply do not know how, what, or when to apply it. Vibe Reasoning transforms AI's latent potential into manifested capability through generic meta-prompts, agentic grounding, and model orchestration. We demonstrate this paradigm through IMO 2025 Problem 6, a combinatorial optimization problem where autonomous AI systems publicly reported failures. Our solution combined GPT-5's exploratory capabilities with Gemini 3 Pro's proof strengths, leveraging agentic workflows with Python code execution and file-based memory, to derive both the correct answer (2112) and a rigorous mathematical proof. Through iterative refinement across multiple attempts, we discovered the necessity of agentic grounding and model orchestration, while human prompts evolved from problem-specific hints to generic, transferable meta-prompts. We analyze why capable AI fails autonomously, how each component addresses specific failure modes, and extract principles for effective vibe reasoning. Our findings suggest that lightweight human guidance can unlock frontier models' mathematical reasoning potential. This is ongoing work; we are developing automated frameworks and conducting broader evaluations to further validate Vibe Reasoning's generality and effectiveness.
Seed-Prover 1.5: Mastering Undergraduate-Level Theorem Proving via Learning from Experience
Dec 19, 2025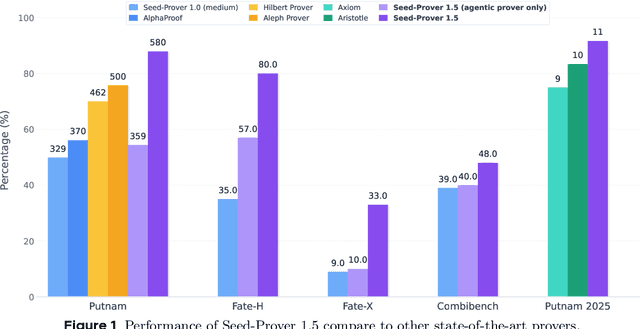

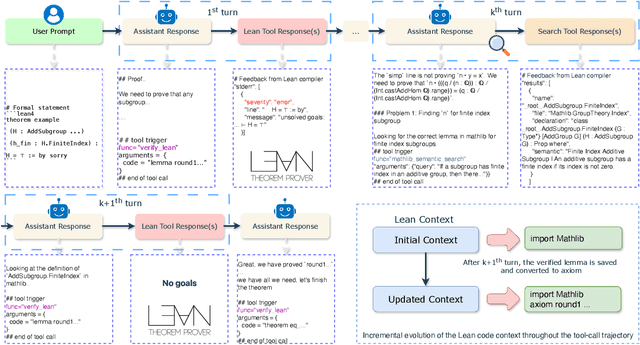

Large language models have recently made significant progress to generate rigorous mathematical proofs. In contrast, utilizing LLMs for theorem proving in formal languages (such as Lean) remains challenging and computationally expensive, particularly when addressing problems at the undergraduate level and beyond. In this work, we present \textbf{Seed-Prover 1.5}, a formal theorem-proving model trained via large-scale agentic reinforcement learning, alongside an efficient test-time scaling (TTS) workflow. Through extensive interactions with Lean and other tools, the model continuously accumulates experience during the RL process, substantially enhancing the capability and efficiency of formal theorem proving. Furthermore, leveraging recent advancements in natural language proving, our TTS workflow efficiently bridges the gap between natural and formal languages. Compared to state-of-the-art methods, Seed-Prover 1.5 achieves superior performance with a smaller compute budget. It solves \textbf{88\% of PutnamBench} (undergraduate-level), \textbf{80\% of Fate-H} (graduate-level), and \textbf{33\% of Fate-X} (PhD-level) problems. Notably, using our system, we solved \textbf{11 out of 12 problems} from Putnam 2025 within 9 hours. Our findings suggest that scaling learning from experience, driven by high-quality formal feedback, holds immense potential for the future of formal mathematical reasoning.
Meta Lattice: Model Space Redesign for Cost-Effective Industry-Scale Ads Recommendations
Dec 15, 2025The rapidly evolving landscape of products, surfaces, policies, and regulations poses significant challenges for deploying state-of-the-art recommendation models at industry scale, primarily due to data fragmentation across domains and escalating infrastructure costs that hinder sustained quality improvements. To address this challenge, we propose Lattice, a recommendation framework centered around model space redesign that extends Multi-Domain, Multi-Objective (MDMO) learning beyond models and learning objectives. Lattice addresses these challenges through a comprehensive model space redesign that combines cross-domain knowledge sharing, data consolidation, model unification, distillation, and system optimizations to achieve significant improvements in both quality and cost-efficiency. Our deployment of Lattice at Meta has resulted in 10% revenue-driving top-line metrics gain, 11.5% user satisfaction improvement, 6% boost in conversion rate, with 20% capacity saving.
DirectSwap: Mask-Free Cross-Identity Training and Benchmarking for Expression-Consistent Video Head Swapping
Dec 10, 2025
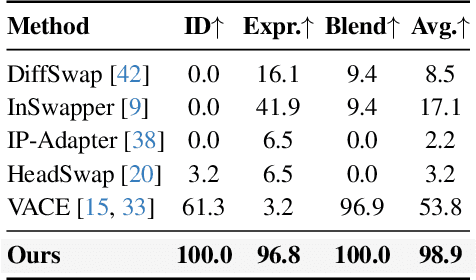
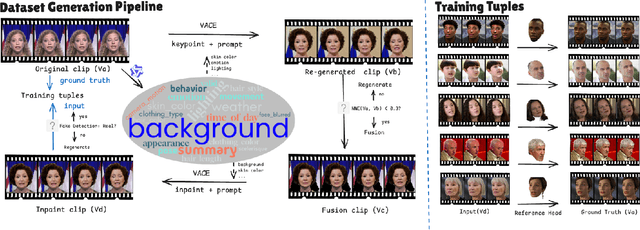
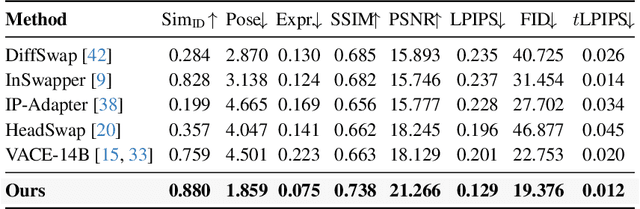
Video head swapping aims to replace the entire head of a video subject, including facial identity, head shape, and hairstyle, with that of a reference image, while preserving the target body, background, and motion dynamics. Due to the lack of ground-truth paired swapping data, prior methods typically train on cross-frame pairs of the same person within a video and rely on mask-based inpainting to mitigate identity leakage. Beyond potential boundary artifacts, this paradigm struggles to recover essential cues occluded by the mask, such as facial pose, expressions, and motion dynamics. To address these issues, we prompt a video editing model to synthesize new heads for existing videos as fake swapping inputs, while maintaining frame-synchronized facial poses and expressions. This yields HeadSwapBench, the first cross-identity paired dataset for video head swapping, which supports both training (\TrainNum{} videos) and benchmarking (\TestNum{} videos) with genuine outputs. Leveraging this paired supervision, we propose DirectSwap, a mask-free, direct video head-swapping framework that extends an image U-Net into a video diffusion model with a motion module and conditioning inputs. Furthermore, we introduce the Motion- and Expression-Aware Reconstruction (MEAR) loss, which reweights the diffusion loss per pixel using frame-difference magnitudes and facial-landmark proximity, thereby enhancing cross-frame coherence in motion and expressions. Extensive experiments demonstrate that DirectSwap achieves state-of-the-art visual quality, identity fidelity, and motion and expression consistency across diverse in-the-wild video scenes. We will release the source code and the HeadSwapBench dataset to facilitate future research.