 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQwen-Image-2.0 Technical Report
May 11, 2026We present Qwen-Image-2.0, an omni-capable image generation foundation model that unifies high-fidelity generation and precise image editing within a single framework. Despite recent progress, existing models still struggle with ultra-long text rendering, multilingual typography, high-resolution photorealism, robust instruction following, and efficient deployment, especially in text-rich and compositionally complex scenarios. Qwen-Image-2.0 addresses these challenges by coupling Qwen3-VL as the condition encoder with a Multimodal Diffusion Transformer for joint condition-target modeling, supported by large-scale data curation and a customized multi-stage training pipeline. This enables strong multimodal understanding while preserving flexible generation and editing capabilities. The model supports instructions of up to 1K tokens for generating text-rich content such as slides, posters, infographics, and comics, while significantly improving multilingual text fidelity and typography. It also enhances photorealistic generation with richer details, more realistic textures, and coherent lighting, and follows complex prompts more reliably across diverse styles. Extensive human evaluations show that Qwen-Image-2.0 substantially outperforms previous Qwen-Image models in both generation and editing, marking a step toward more general, reliable, and practical image generation foundation models.
Align Generative Artificial Intelligence with Human Preferences: A Novel Large Language Model Fine-Tuning Method for Online Review Management
Apr 23, 2026Online reviews have played a pivotal role in consumers' decision-making processes. Existing research has highlighted the significant impact of managerial review responses on customer relationship management and firm performance. However, a large portion of online reviews remains unaddressed due to the considerable human labor required to respond to the rapid growth of online reviews. While generative AI has achieved remarkable success in a range of tasks, they are general-purpose models and may not align well with domain-specific human preferences. To tailor these general generative AI models to domain-specific applications, finetuning is commonly employed. Nevertheless, several challenges persist in finetuning with domain-specific data, including hallucinations, difficulty in representing domain-specific human preferences, and over conservatism in offline policy optimization. To address these challenges, we propose a novel preference finetuning method to align an LLM with domain-specific human preferences for generating online review responses. Specifically, we first identify the source of hallucination and propose an effective context augmentation approach to mitigate the LLM hallucination. To represent human preferences, we propose a novel theory-driven preference finetuning approach that automatically constructs human preference pairs in the online review domain. Additionally, we propose a curriculum learning approach to further enhance preference finetuning. To overcome the challenge of over conservatism in existing offline preference finetuning method, we propose a novel density estimation-based support constraint method to relax the conservatism, and we mathematically prove its superior theoretical guarantees. Extensive evaluations substantiate the superiority of our proposed preference finetuning method.
LILAC: Language-Conditioned Object-Centric Optical Flow for Open-Loop Trajectory Generation
Mar 26, 2026We address language-conditioned robotic manipulation using flow-based trajectory generation, which enables training on human and web videos of object manipulation and requires only minimal embodiment-specific data. This task is challenging, as object trajectory generation from pre-manipulation images and natural language instructions requires appropriate instruction-flow alignment. To tackle this challenge, we propose the flow-based Language Instruction-guided open-Loop ACtion generator (LILAC). This flow-based Vision-Language-Action model (VLA) generates object-centric 2D optical flow from an RGB image and a natural language instruction, and converts the flow into a 6-DoF manipulator trajectory. LILAC incorporates two key components: Semantic Alignment Loss, which strengthens language conditioning to generate instruction-aligned optical flow, and Prompt-Conditioned Cross-Modal Adapter, which aligns learned visual prompts with image and text features to provide rich cues for flow generation. Experimentally, our method outperformed existing approaches in generated flow quality across multiple benchmarks. Furthermore, in physical object manipulation experiments using free-form instructions, LILAC demonstrated a superior task success rate compared to existing methods. The project page is available at https://lilac-75srg.kinsta.page/.
Logics-Parsing-Omni Technical Report
Mar 12, 2026Addressing the challenges of fragmented task definitions and the heterogeneity of unstructured data in multimodal parsing, this paper proposes the Omni Parsing framework. This framework establishes a Unified Taxonomy covering documents, images, and audio-visual streams, introducing a progressive parsing paradigm that bridges perception and cognition. Specifically, the framework integrates three hierarchical levels: 1) Holistic Detection, which achieves precise spatial-temporal grounding of objects or events to establish a geometric baseline for perception; 2) Fine-grained Recognition, which performs symbolization (e.g., OCR/ASR) and attribute extraction on localized objects to complete structured entity parsing; and 3) Multi-level Interpreting, which constructs a reasoning chain from local semantics to global logic. A pivotal advantage of this framework is its evidence anchoring mechanism, which enforces a strict alignment between high-level semantic descriptions and low-level facts. This enables ``evidence-based'' logical induction, transforming unstructured signals into standardized knowledge that is locatable, enumerable, and traceable. Building on this foundation, we constructed a standardized dataset and released the Logics-Parsing-Omni model, which successfully converts complex audio-visual signals into machine-readable structured knowledge. Experiments demonstrate that fine-grained perception and high-level cognition are synergistic, effectively enhancing model reliability. Furthermore, to quantitatively evaluate these capabilities, we introduce OmniParsingBench. Code, models and the benchmark are released at https://github.com/alibaba/Logics-Parsing/tree/master/Logics-Parsing-Omni.
Ca-MCF: Category-level Multi-label Causal Feature selection
Feb 13, 2026Multi-label causal feature selection has attracted extensive attention in recent years. However, current methods primarily operate at the label level, treating each label variable as a monolithic entity and overlooking the fine-grained causal mechanisms unique to individual categories. To address this, we propose a Category-level Multi-label Causal Feature selection method named Ca-MCF. Ca-MCF utilizes label category flattening to decompose label variables into specific category nodes, enabling precise modeling of causal structures within the label space. Furthermore, we introduce an explanatory competition-based category-aware recovery mechanism that leverages the proposed Specific Category-Specific Mutual Information (SCSMI) and Distinct Category-Specific Mutual Information (DCSMI) to salvage causal features obscured by label correlations. The method also incorporates structural symmetry checks and cross-dimensional redundancy removal to ensure the robustness and compactness of the identified Markov Blankets. Extensive experiments across seven real-world datasets demonstrate that Ca-MCF significantly outperforms state-of-the-art benchmarks, achieving superior predictive accuracy with reduced feature dimensionality.
SimuScene: Training and Benchmarking Code Generation to Simulate Physical Scenarios
Feb 11, 2026Large language models (LLMs) have been extensively studied for tasks like math competitions, complex coding, and scientific reasoning, yet their ability to accurately represent and simulate physical scenarios via code remains underexplored. We propose SimuScene, the first systematic study that trains and evaluates LLMs on simulating physical scenarios across five physics domains and 52 physical concepts. We build an automatic pipeline to collect data, with human verification to ensure quality. The final dataset contains 7,659 physical scenarios with 334 human-verified examples as the test set. We evaluated 10 contemporary LLMs and found that even the strongest model achieves only a 21.5% pass rate, demonstrating the difficulty of the task. Finally, we introduce a reinforcement learning pipeline with visual rewards that uses a vision-language model as a judge to train textual models. Experiments show that training with our data improves physical simulation via code while substantially enhancing general code generation performance.
SpatialV2A: Visual-Guided High-fidelity Spatial Audio Generation
Jan 21, 2026While video-to-audio generation has achieved remarkable progress in semantic and temporal alignment, most existing studies focus solely on these aspects, paying limited attention to the spatial perception and immersive quality of the synthesized audio. This limitation stems largely from current models' reliance on mono audio datasets, which lack the binaural spatial information needed to learn visual-to-spatial audio mappings. To address this gap, we introduce two key contributions: we construct BinauralVGGSound, the first large-scale video-binaural audio dataset designed to support spatially aware video-to-audio generation; and we propose a end-to-end spatial audio generation framework guided by visual cues, which explicitly models spatial features. Our framework incorporates a visual-guided audio spatialization module that ensures the generated audio exhibits realistic spatial attributes and layered spatial depth while maintaining semantic and temporal alignment. Experiments show that our approach substantially outperforms state-of-the-art models in spatial fidelity and delivers a more immersive auditory experience, without sacrificing temporal or semantic consistency. All datasets, code, and model checkpoints will be publicly released to facilitate future research.
Learning Audio-Visual Embeddings with Inferred Latent Interaction Graphs
Jan 17, 2026Learning robust audio-visual embeddings requires bringing genuinely related audio and visual signals together while filtering out incidental co-occurrences - background noise, unrelated elements, or unannotated events. Most contrastive and triplet-loss methods use sparse annotated labels per clip and treat any co-occurrence as semantic similarity. For example, a video labeled "train" might also contain motorcycle audio and visual, because "motorcycle" is not the chosen annotation; standard methods treat these co-occurrences as negatives to true motorcycle anchors elsewhere, creating false negatives and missing true cross-modal dependencies. We propose a framework that leverages soft-label predictions and inferred latent interactions to address these issues: (1) Audio-Visual Semantic Alignment Loss (AV-SAL) trains a teacher network to produce aligned soft-label distributions across modalities, assigning nonzero probability to co-occurring but unannotated events and enriching the supervision signal. (2) Inferred Latent Interaction Graph (ILI) applies the GRaSP algorithm to teacher soft labels to infer a sparse, directed dependency graph among classes. This graph highlights directional dependencies (e.g., "Train (visual)" -> "Motorcycle (audio)") that expose likely semantic or conditional relationships between classes; these are interpreted as estimated dependency patterns. (3) Latent Interaction Regularizer (LIR): A student network is trained with both metric loss and a regularizer guided by the ILI graph, pulling together embeddings of dependency-linked but unlabeled pairs in proportion to their soft-label probabilities. Experiments on AVE and VEGAS benchmarks show consistent improvements in mean average precision (mAP), demonstrating that integrating inferred latent interactions into embedding learning enhances robustness and semantic coherence.
DirectSwap: Mask-Free Cross-Identity Training and Benchmarking for Expression-Consistent Video Head Swapping
Dec 10, 2025
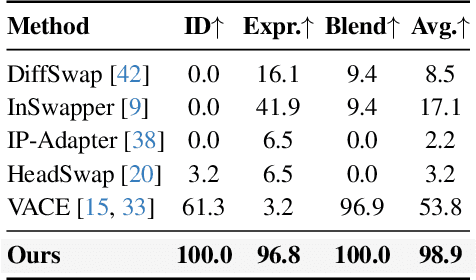
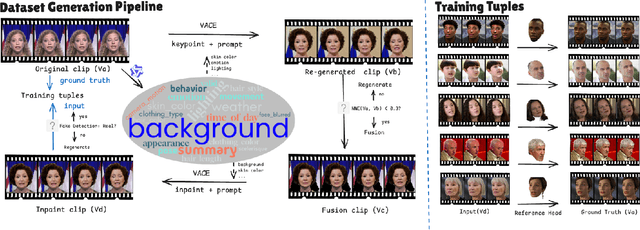
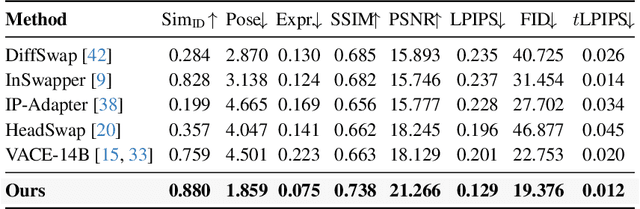
Video head swapping aims to replace the entire head of a video subject, including facial identity, head shape, and hairstyle, with that of a reference image, while preserving the target body, background, and motion dynamics. Due to the lack of ground-truth paired swapping data, prior methods typically train on cross-frame pairs of the same person within a video and rely on mask-based inpainting to mitigate identity leakage. Beyond potential boundary artifacts, this paradigm struggles to recover essential cues occluded by the mask, such as facial pose, expressions, and motion dynamics. To address these issues, we prompt a video editing model to synthesize new heads for existing videos as fake swapping inputs, while maintaining frame-synchronized facial poses and expressions. This yields HeadSwapBench, the first cross-identity paired dataset for video head swapping, which supports both training (\TrainNum{} videos) and benchmarking (\TestNum{} videos) with genuine outputs. Leveraging this paired supervision, we propose DirectSwap, a mask-free, direct video head-swapping framework that extends an image U-Net into a video diffusion model with a motion module and conditioning inputs. Furthermore, we introduce the Motion- and Expression-Aware Reconstruction (MEAR) loss, which reweights the diffusion loss per pixel using frame-difference magnitudes and facial-landmark proximity, thereby enhancing cross-frame coherence in motion and expressions. Extensive experiments demonstrate that DirectSwap achieves state-of-the-art visual quality, identity fidelity, and motion and expression consistency across diverse in-the-wild video scenes. We will release the source code and the HeadSwapBench dataset to facilitate future research.
RCPU: Rotation-Constrained Error Compensation for Structured Pruning of a Large Language Model
Oct 09, 2025In this paper, we propose a rotation-constrained compensation method to address the errors introduced by structured pruning of large language models (LLMs). LLMs are trained on massive datasets and accumulate rich semantic knowledge in their representation space. In contrast, pruning is typically carried out with only a small amount of calibration data, which makes output mismatches unavoidable. Although direct least-squares fitting can reduce such errors, it tends to overfit to the limited calibration set, destructively modifying pretrained weights. To overcome this difficulty, we update the pruned parameters under a rotation constraint. This constrained update preserves the geometry of output representations (i.e., norms and inner products) and simultaneously re-aligns the pruned subspace with the original outputs. Furthermore, in rotation-constrained compensation, removing components that strongly contribute to the principal directions of the output makes error recovery difficult. Since input dimensions with large variance strongly affect these principal directions, we design a variance-aware importance score that ensures such dimensions are preferentially kept in the pruned model. By combining this scoring rule with rotation-constrained updates, the proposed method effectively compensates errors while retaining the components likely to be more important in a geometry-preserving manner. In the experiments, we apply the proposed method to LLaMA-7B and evaluate it on WikiText-2 and multiple language understanding benchmarks. The results demonstrate consistently better perplexity and task accuracy compared with existing baselines.